Classical Automation enters Alien World of IT: Part 1
Follow article
 Dave from DesignSpark
Dave from DesignSpark
How do you feel about this article? Help us to provide better content for you.
Dave from DesignSpark
Thank you! Your feedback has been received.
Dave from DesignSpark
There was a problem submitting your feedback, please try again later.
Dave from DesignSpark
What do you think of this article?

When I started computing in the seventies, it was natural to understand the hardware of your CPU. I needed to key in every single byte and its RAM address with a hex-keyboard. After filling one kB of RAM, you better have been sure to control the content by reading your 7-segment display a second time before pressing the “run” button. Connecting switches and LEDs was the normal way to let “users” interact with your software. It was very much “physical computing”. Later in university, I learned using FORTRAN to do calculations. I was not even allowed to touch the computer. We needed to punch holes into sheets of cardboard (so-called “punchcards”) and let an “operator” feed these sheets into the computer which was more or less a room full of 19” towers. The next day we could collect the computing results as printouts or punchcards. Since these days I have been a traveller between these two worlds of physical computing and the classical IT world. They are very different and specialised. Very often the experts of one world do not understand what the experts of the other world are talking about, or why they see difficulties in problems which do not exist in their own world.
Naturally, the tools and rules for these two computing topics have been historically established differently to follow their specific aims. And this seems to be one of the main obstacles for rapid development in IIoT (“Industrial Internet of Things”). In this series of articles, I will try to explain some of the core differences. Hopefully, you will come to understand why safety and security have seldom met in the automation industry before Industry 4.0 or why cyclically running a state machine is not the best architecture for an OS like MS Windows. Maybe you are more the IT type of expert and want to understand what makes a PLC (“programmable logic controller”) architecture so unique. Go on reading…
Part 1
Deterministic versus probabilistic system architectures.
In the automation industry, “Things” are the domain of classical engineers. They design embedded systems or program PLCs (“Programmable Logic Controller”) to control complex machines for production processes. Their system architecture aims to maximise reliability and often uses maximum reduction. Things need to reliably perform the same tasks over and over very often without the interaction of humans. So-called HMIs (human-machine interfaces) allow human supervision and adaption of process values but are not a central part of the core control algorithms. I’ll try to give you an impression of how this type of architecture developed.
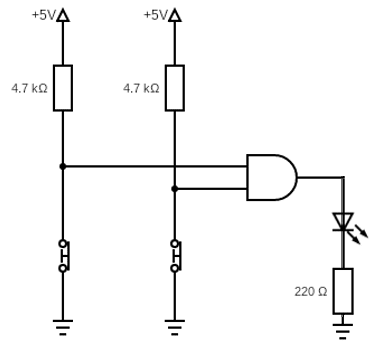
Pic. 1: Simple logic circuit. LED turns on if both buttons are pressed.
In the beginning, physical computing was done by combining binary logic gates. Like in picture 1 you see two switches (could be binary sensors like light barriers). If you close both, the output turns on a LED. Now think of a way to monitor a switching sequence by such logic gates. You end up with a “clocked logic” which works in cycles (pic. 2).
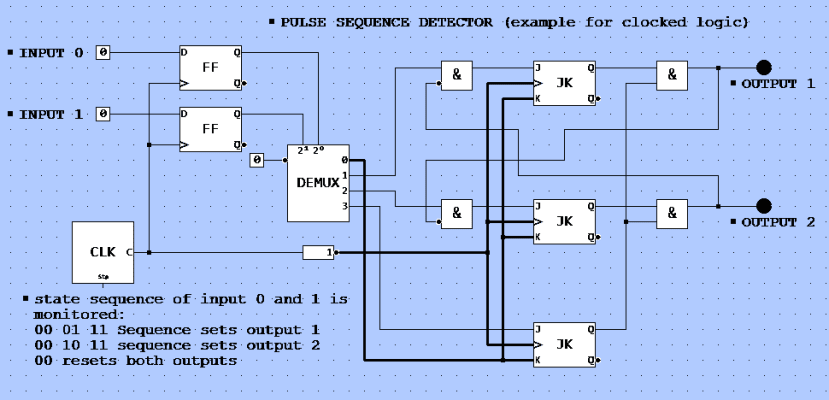
Pic. 2: Example of a clocked logic. You can simulate the logic using this link: http://simulator.io/board/Yc9tpDmfyO/3
A PLC works like such a clocked logic. A bunch of gates can be connected (output to inputs) by your PLC “program” to make this controller flexible (in the early PLCs there was indeed an array of logic blocks – therefore the name – whereas today a CPU does the job). But in the core there is always a cyclical operation: Get a snapshot of all inputs, calculate binary operations on the inputs, set all outputs. Thus the logical operations depend on inputs and defined “internal states” (buffered in logic circuits called “Flip-Flops”) which all need to be buffered in a kind of “snapshot-buffer” (“latch”) before the PLC performs binary calculations. The results are buffered again before they switch the outputs all at the same time (picture 3). This buffering of the so-called “process image” is essential to avoid misinterpretation.
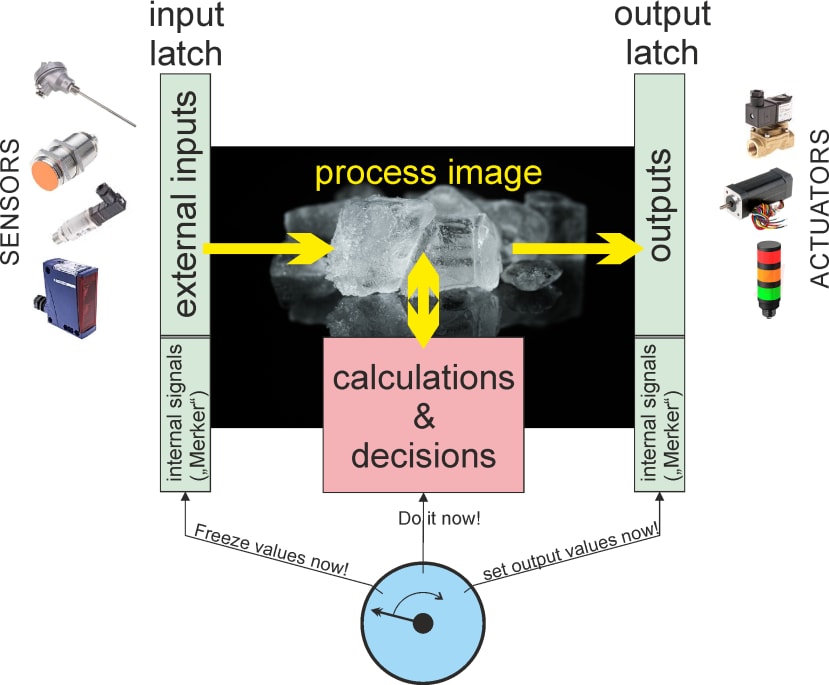
Pic. 3: Cyclical operation of a PLC using a "process image".
Any sequence needs a clock to detect “before” and “after”. But clocking a signal (input) means to “sample” it. The clock rate turns out to be a sample rate and as Nyquist has mathematically shown you can only reliably detect any signal which is not shorter than double the sample rate. Take the example of picture 2: If an object moves through both light beams, this always results in a sequence “00 – 01 – 11 – 10 – 00” or “00 – 10 – 11 – 01 – 00” depending on the direction of the transition. The clock period should be shorter than half the time between two of the states to detect such a sequence. Sampling the two light barriers at different times would make the detection very complicated if not impossible. To calculate a minimum clock rate you expect simultaneously sampled signals.
Nyquist for dummies
C.E. Shannon introduced the term „Nyquist frequency“ in signal theory when he worked on “time-discrete systems”- don’t worry it only sounds complicated. When we look at a digital signal it becomes quite easy to understand:
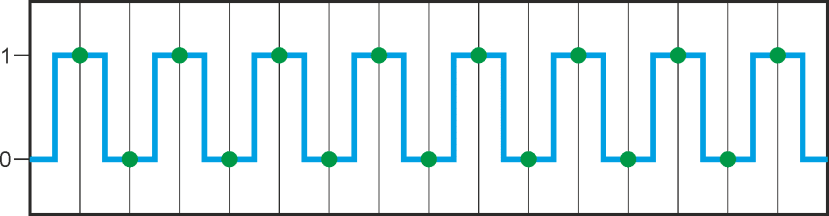
Let’s say we have a square wave toggling between the two digital values “0” and “1”. Your machine cannot continuously watch that signal but needs to cyclically pick the actual value (“sample” it). If you look at the timeline of the signal and the “sample points” you will understand that you need to sample at least twice per square wave period to reliably detect the two states of the square wave. So the “sample frequency” (sometimes also called “sample rate”) must be twice as high as the signal frequency.
In other words: The highest signal frequency which can be reliably processed is ½ the sampling frequency. This highest signal frequency allowed as input to your system is called the “Nyquist-frequency”.
Signal frequency barely okay:
Signal frequency too high => “signal aliasing”(red dot):
This sequential concept of sampling a process image, doing calculations on the buffered input values and buffering results until the end of computation before simultaneously switching the outputs is essential for a highly predictable system. Later it was adopted by embedded controllers which use FSM (“finite state machines”). Each cycle of the FSM starts with a defined state and may end in a transition into a different state depending on signal states. You could reduce the concept of such Controllers to a simple task: “Cyclically switching states (and outputs) according to input and internal states”. Such a controller works completely predictably and reliably (“deterministic”) because at design time you need to know every possible state it can have as well as the state transition rules.
EN 61131 is one of the central norms following this architecture and was established to define the behaviour of controllers in the automation industry. It also defines programming languages like Ladder Diagram (LD), Function Block Diagram (FBD), Sequential Function Chart (SFC) or Instruction List (IL) which reflect the historical electronic roots of the PLC technology (e.g. “ladder” is very close to the circuit diagram of a digital logic).
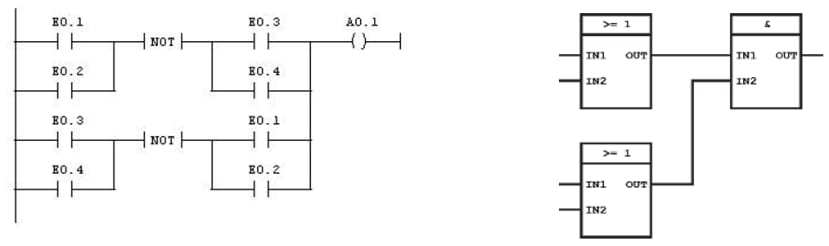
Pic. 4: Examples of PLC programs in LD (left) and FDB (right).
To get such “Things” connected to the cloud means entering a different world with different aims and rules: The classical world of IT. You often find a separation in so-called “backends” (with databases to store and retrieve mass data collections effectively) and frontends (mostly PC based applications with a highly interactive GUI). You could even say that data-human interaction is the base of classical IT, whereas sensor-actuator interaction is the domain of controllers in automation. Therefore the system architecture of IT is often optimised for maximum efficiency, re-usability, usability, and comfort. Smart user interfaces (UIs), object-based programming languages and multi-tasking operating systems do fit well to these aims.
Cyclical operating software would be a waste of resources. IT systems more often use an event-based concept: You click on a virtual button which triggers an “event” inside the software. This event triggers all linked processes. Background processes (often referred to as “daemons”) continually monitor the mouse to detect a click or perform other jobs. These daemons work mostly independently and asynchronously. Other processes can subscribe to get messages whenever certain events occur. So there are “services” offered by backend processes. Such processes provide their services to client processes.
While a PLC in automation would cyclically ask a switch if it is closed, an operating system like Linux would organise the following scenario: The keyboard service sends a message as soon as a key is pressed. Any application software which has subscribed to this message will receive it with a minimal delay and may or may not react to it. The communication between a service and a client usually is message and event-based. It uses well-defined interfaces which is the only dependency between them. Because the rest is independent service and client processes can run on different systems, and they often do so (e.g. “backend” and “frontend” systems). Such server-client structures easily allow a distributed and highly scalable architecture. A modern cloud provider like AWS does provide over a thousand services, and millions of clients can use them simultaneously over the internet.
So this type of architecture is anything else but “finite state”: Working with many independent and asynchronous processes result in a less predictable system. The amount of possible states is typically too high to be entirely known and considered at design time. On the other hand, because of scalability and the object-oriented design principles, such systems are nearly unlimited when working with mass data. In many ways, they are much more like we: multi-tasking, highly interactive, communication friendly and adaptive at the expense of reliability and velocity. No wonder that IT is predestined to interact with humans (GUI). No wonder that communication between systems has a much more “social touch” (we will have a look at this in part 2). And no wonder that “probabilistic computing” (using statistical methods for decisions) allows for machine learning and AI (artificial intelligence).
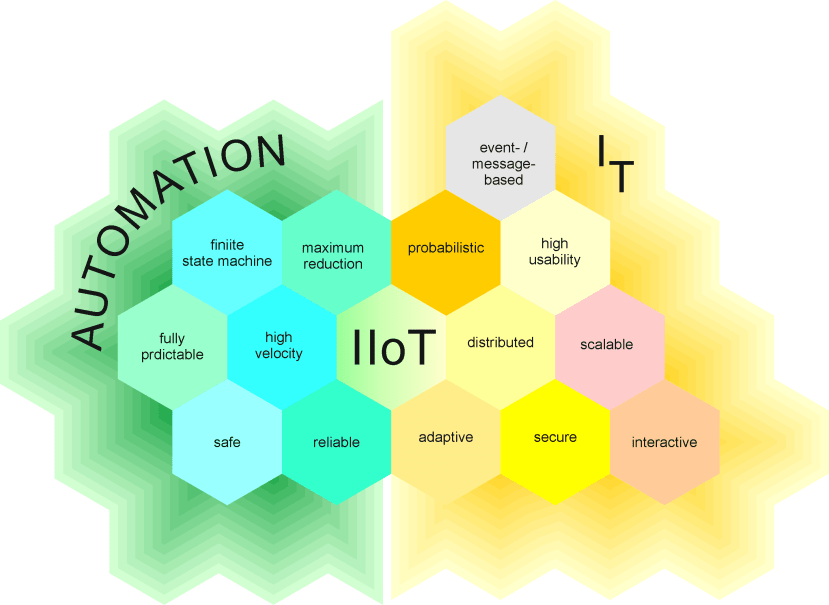
Pic. 5: IIoT – where automation meets IT.
If automation engineers want to join their deterministic home with this fantastic new probabilistic world, they need to understand that it is based on these “human” qualities. Connecting the cloud to real-world machines, on the other hand, does introduce new risks and IT engineers need to understand the base of reliable working automation.
Coming soon
Part 2 is about field busses versus internet protocols, part 3 is about safety and security, and the final part 4 will talk about opensource versus protection of IP.
Comments