Jetson AGX Orin and Riva Accelerate Embedded Speech AI
Follow article
 Dave from DesignSpark
Dave from DesignSpark
How do you feel about this article? Help us to provide better content for you.
Dave from DesignSpark
Thank you! Your feedback has been received.
Dave from DesignSpark
There was a problem submitting your feedback, please try again later.
Dave from DesignSpark
What do you think of this article?
Embedded AI powerhouse and versatile SDK accelerate speech applications.
In this article we take a look at NVIDIA Riva, “a GPU-accelerated SDK for building Speech AI applications that are customized for your use case and deliver real-time performance”, running examples on a Jetson AGX Orin (253-9662) which we had previously installed Jetpack SDK on.
Introduction
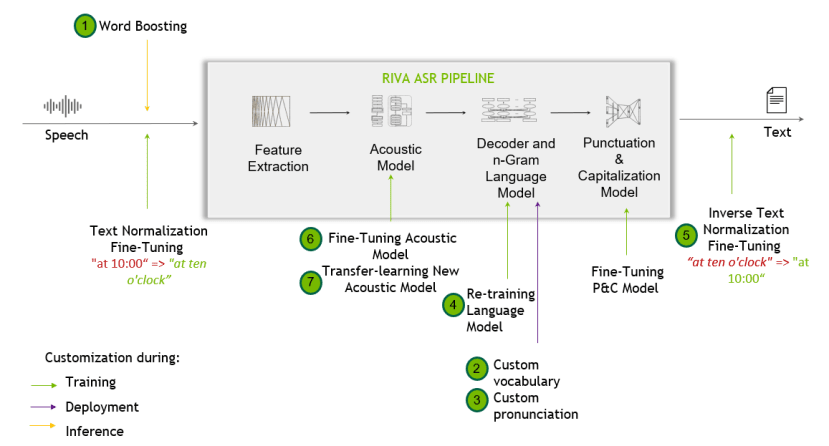
Riva speech recognition pipeline and possible customisations.
Artificial intelligence continues to have a profound impact across many areas of technology and by no means least in speech applications, where it enables far more accurate automatic speech recognition and more natural speech synthesis, to name but two. And as with most AI application domains, speech AI really shines and brings significant performance gains when targeted to hardware acceleration, rather than simply running on a general purpose processor (GPP).
It should come as no surprise therefore that NVIDIA have invested heavily in speech AI and an example of this is with NVIDIA Riva, “a GPU-accelerated speech and translation AI software development kit for building and deploying fully customizable, real-time AI pipelines that deliver world-class accuracy in all clouds, on premises, at the edge, and on embedded devices”.
Together NVIDIA Jetson Orin and NVDIA Riva provide an eminently compact solution, which combines powerful embedded compute with GPU acceleration and plentiful I/O, plus sophisticated and yet easy-to-use speech AI enablement. Applications for which include communications, building automation, smart factories, transportation and assistive technology, amongst many others.
In this article, we’ll be covering the installation of the NVIDIA Riva Quick Start, which thanks to Docker and NVIDIA GPU Cloud makes it quick and easy to deploy a Riva environment complete with support for automatic speech recognition (ASR), natural language processing (NLP), text-to-speech (TTS), and natural machine translation (NMT). As part of which we’ll be running demos for ASR and TTS, which provide highly accurate transcription and natural-sounding voice synthesis.
Setup
Since it was a number of months since we last used the NVIDIA AGX Orin, we decided to start by upgrading the installed operating system packages with:
$ sudo apt update && sudo apt dist-upgradeThe documentation states that we need to have Jetpack version 5.1 or 5.1.1 installed and upon checking the version after the O/S upgrade, we discovered that we had in fact version 5.1.2. Hoping that this wouldn’t be an issue and that perhaps the docs just needed updating, we proceeded anyway.
Next, we needed to ensure that we had all the CPU cores activated and both CPU and GPU are clocked at maximum frequency, which we did with the following command:
$ sudo nvpmodel -m 0Docker
As instructed, we modified /etc/docker/daemon.json to add a line specifying nvidia as the default Docker runtime, after which the file contents were as shown below.
{
"runtimes": {
"nvidia": {
"path": "nvidia-container-runtime",
"runtimeArgs": []
}
},
"default-runtime": "nvidia"
}Following which it was necessary to restart the Docker service with:
$ sudo systemctl restart dockerTwo turnkey deployment models are available, local Docker and Kubernetes. However, since we are using an NVIDIA-embedded platform, we must use the former. The latter could be used if we had discrete PCIe GPUs installed into one or more servers.
NGC CLI
The scripts for local deployment need to be downloaded and we can either do this manually or use the NVIDIA GPU Cloud Command Line Interface (NGC CLI). We decided to go with the latter and since this is not installed by default, we installed it as per the instructions. In short, downloading the NGC CLI ZIP, verifying this, extracting the contents and setting up the path.
Creating an NVIDIA GPU Cloud API key for use with NGC CLI.
Note that it is important that the ngc config set step is completed and for this, it will be necessary to enter an API key which is generated via the NVIDIA GPU Cloud portal. If this is not done, the next step will fail as the CLI tool is unable to authenticate to NGC. For more details, see the video.
Riva scripts
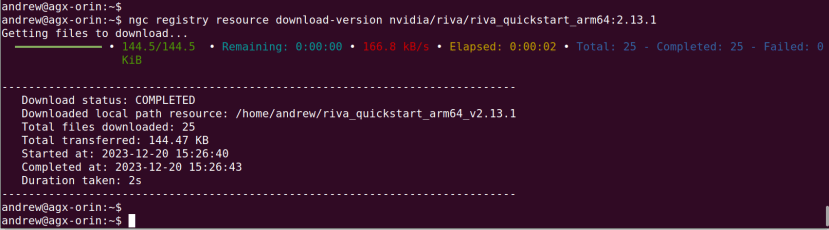
At this point we now had the NGC CLI installed and could use this to install the Riva scripts:
$ ngc registry resource download-version nvidia/riva/riva_quickstart_arm64:2.13.1Following which the scripts were downloaded to ~/riva_quickstart_arm64_v2.13.1.
Configuration
We were now ready to configure the Riva quickstart environment, which we did by editing its configuration script.
$ cd riva_quickstart_arm64_v2.13.1
$ vi config.shEditors other than vi may be used of course.

There are various different options which may be configured, including which Riva services are enabled and by default this will be all four.
Reading forum posts it appeared to be suggested that with embedded platforms (Jetson), it may be best to enable only those Riva services which are needed; while Jetson AGX Orin is the most powerful NVIDIA Jetson platform at the time of writing, packing an awful lot of CUDA acceleration into a relatively small package, there are obviously far more powerful NVIDIA discrete PCIe GPUs which may be used with Riva. Hence to start with we only enabled ASR.
Remember that these are demos and typical embedded applications are likely to only run one or two such services, e.g. ASR and/or TTS.
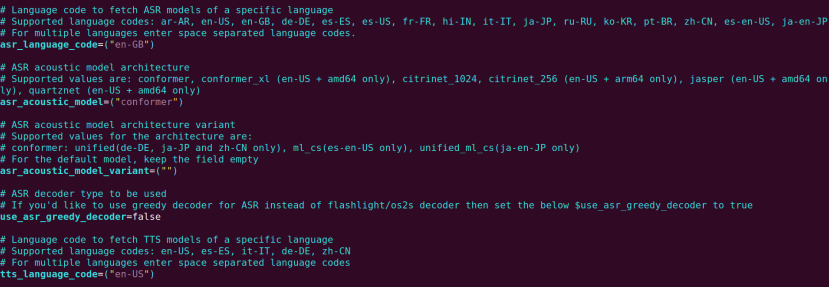
Other key configuration parameters include the ASR and TTS models for specific languages, which in the case of the former we changed from en-US to en-GB.
Startup
Any audio devices which we planned to use had to be connected before Riva services are started.
With the Riva quickstart configured we could now initialise this with:
$ bash riva_init.sh
However, this resulted in an error, due to our user not being a member of the docker group. This step seems to be missing from the instructions, but can be easily remedied with:
$ sudo usermod -a -G docker $USERThen logging out and back in again to pick up the group.
Following which the initialise step completed without error and we could launch the riva-speech Docker container with:
$ bash riva_start.sh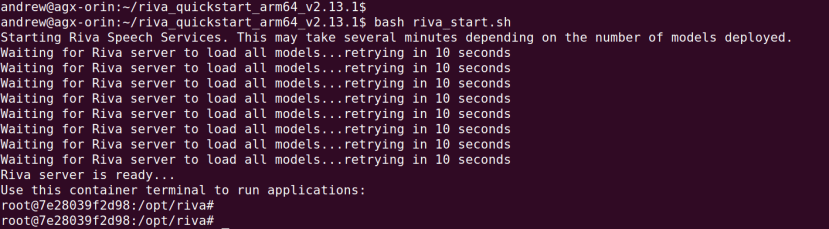
After a short delay, services start and we drop into a shell inside the Docker container.
Demonstration
Automatic speech recognition
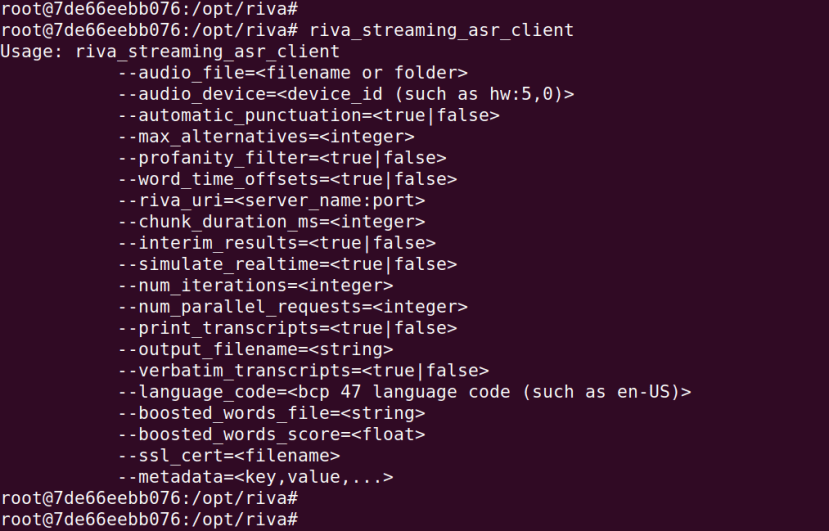
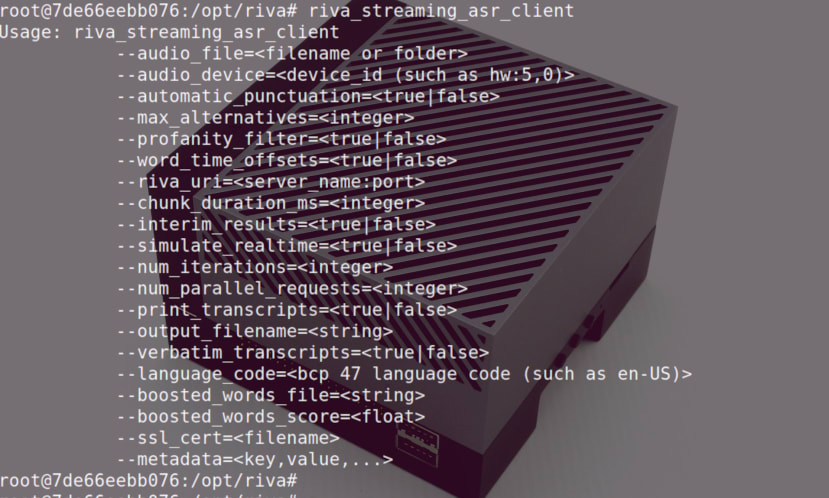
Once inside the container we can run the riva_streaming_asr_client command to see what options this takes. The container image includes demo WAV files that we could pass to the client, but it was decided that using a microphone instead would be much more interesting.
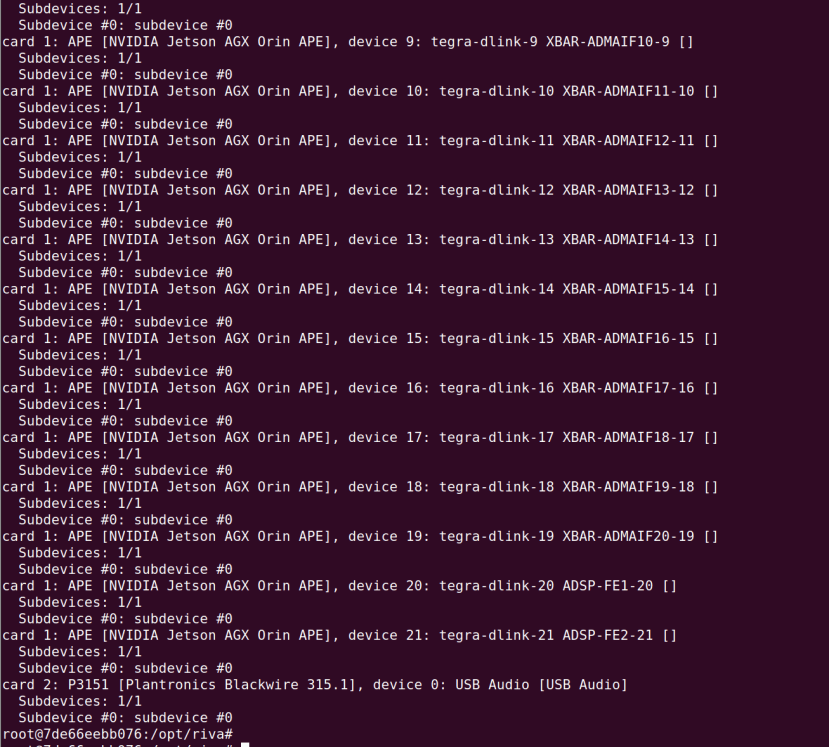
The audio devices were listed with aplay -l. We wanted to use the USB headset which was plugged in and this enumerated as device #2, subdevice #0. To specify this and en-GB as the language, we ran:
# riva_streaming_asr_client --language_code=en-GB --audio_device=plughw:2,0
The above video shows ASR transcribing audio in real-time, with the author speaking naturally and achieving highly accurate results. As the process is terminated we are then presented with the final transcript, along with start and end timestamps and a confidence for each word.
Text-to-speech
We next turned our attention to TTS and unfortunately, en-GB is not supported by the demo, so we had to configure en-US for this. However, UK English voice support would presumably just be a matter of having a suitably trained language model and the Riva documentation has notes on training a custom voice, which can be achieved using the Riva custom voice recoder and at least 30 minutes of high-quality data for training is recommended.
We found that TTS managed to pronounce “AI” and “SDK” correctly, but didn’t manage as well with “AGX”, which is perhaps understandable and Riva ASR can be customised to extend the default vocabulary, amongst other things.
However, a quick fix was to spell out “A G X” and so the text string we ended up passing to riva_tts_client was “Hello, DesignSpark community. This is a speech synthesizer, powered by NVIDIA Riva Speech AI SDK, running on an NVIDIA Jetson A G X Orin." We also decided to time the command to see just how long it would take to synthesize this text. The resulting command was:
# time riva_tts_client --voice_name=English-US.Female-1 --text="Hello, DesignSpark community. This is a speech synthesizer, powered by NVIDIA Riva Speech AI SDK, running on an NVIDIA Jetson A G X Orin." --audio_file=/opt/riva/wav/ds-demo2.wav
Rather impressively, it took well under a second to generate a WAV file with the synthesized voice — and the result sounded pretty great!
Closing remarks
In this article, we’ve seen how quickly we can get up and running with NVIDIA Riva speech AI on a Jetson embedded platform, and the impressive performance provided by automatic speech recognition and text-to-speech voice synthesis. However, we’ve barely scratched the surface of what’s possible with Riva, which also includes speech-to-speech and speech-to-text translation, custom voice synthesis and more, plus complete sample applications.
Comments