Blockchain Primer – Part 2
Follow article
 Dave from DesignSpark
Dave from DesignSpark
How do you feel about this article? Help us to provide better content for you.
Dave from DesignSpark
Thank you! Your feedback has been received.
Dave from DesignSpark
There was a problem submitting your feedback, please try again later.
Dave from DesignSpark
What do you think of this article?
In part 1, we looked at the construction of basic blocks and how they are linked together to form an immutable ledger. In this part, we will look at how blockchain functions in the wild, as part of a co-operating network.

Nodes
One of the key inherent properties of blockchain technology is that it is decentralised. There is no central authority running dedicated servers to host the blockchain. Instead, it's based on consensus between users on a distributed peer-to-peer (P2P) network.
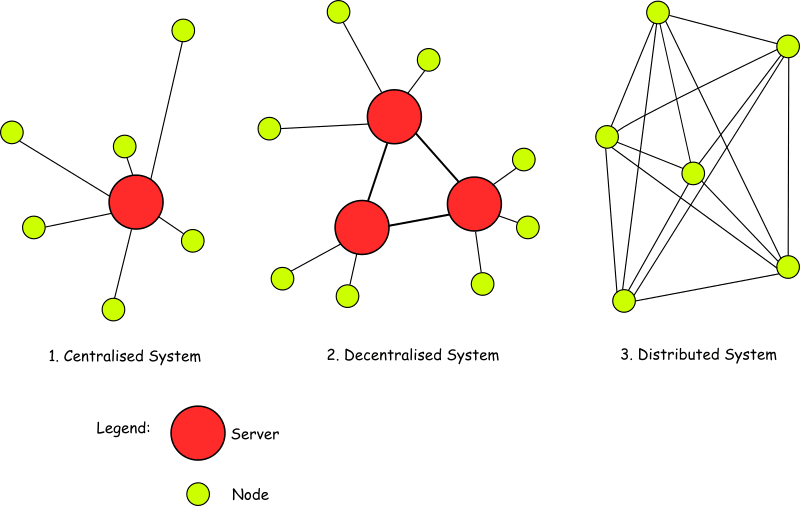
In general, every participant in this network is a node; but not all nodes are created equal. Depending on the implementation, there can be numerous types of node. However, most implementations will feature two types in some form or other:
Full nodes: These act as servers in the blockchain network and will host a copy of the full blockchain in a local database, which leads to them sometimes being referred to as ‘full archival’ nodes. The main tasks of these nodes include maintaining the consensus between other nodes and verifying transactions. These will usually be the nodes that can add blocks to the network. How they do that depends on the consensus protocol being used.
Light (or Lightweight) nodes: This could be a ‘pruned’ full node, which will store blocks from the beginning and add them as usual but once the chain reaches a pre-set size, the node deletes the oldest blocks, retaining only their headers and placement in the chain. As pruned nodes are still considered to be full nodes, they can usually verify transactions and be involved in the consensus.
Alternatively, a true lightweight node interacts with the blockchain by relying on full nodes to provide it with the necessary information. As it doesn’t store a copy of the chain, it must query the current status for the last block and broadcast transactions for processing. Both these methods allow nodes with limited resources to be part of a blockchain ecosystem.
Other node types that you may hear about include Master Nodes and Authority Nodes.
A Master Node’s sole purpose is to validate and record blocks: they cannot add blocks and exist to help secure the network.
If a network uses Authority Nodes, there will be a limited number of them (defined by the network developer) that act as full nodes. All other nodes will be light nodes. This partial centralisation can speed up the system by reducing the time it takes to reach consensus.
Consensus Protocols
One of the problems that must be tackled by any distributed system of peers is the question of who gets to write data, or perhaps more importantly who doesn’t get to write data. The rules by which a blockchain network operates and confirms the validity of information written in blocks is called “consensus”. In blockchain networks, we need to be able to validate a block or a chain of blocks for data integrity at any given time but especially when new blocks arrive from other nodes and we have to decide if we can accept them. It is critical to gain consensus across the network to maintain data integrity and mitigate against potential attackers spamming the network with junk blocks.
The two most fully developed approaches to tackling this problem are known as Proof-of-Work (PoW) and Proof-of-Stake (PoS). Both have advantages but carry disadvantages too.
Proof of Work
PoW (aka ‘CPU cost function’) was conceived by Cynthia Dwork and Moni Naor in 1993 and is simply setting a puzzle so that the first node to solve the puzzle gets to add the next block. An essential feature of the puzzle is that it must be relatively hard to solve but simple to verify that the solution has been found.
If you read part 1 of this primer, you probably won’t be surprised to learn that the puzzles are often based on solving hash function challenges that can only be solved by brute force methods but are then easy to verify. The act of puzzle solving is commonly referred to as ‘mining’.
As an example of the kind of puzzle that might be set, consider a block that looks like this:
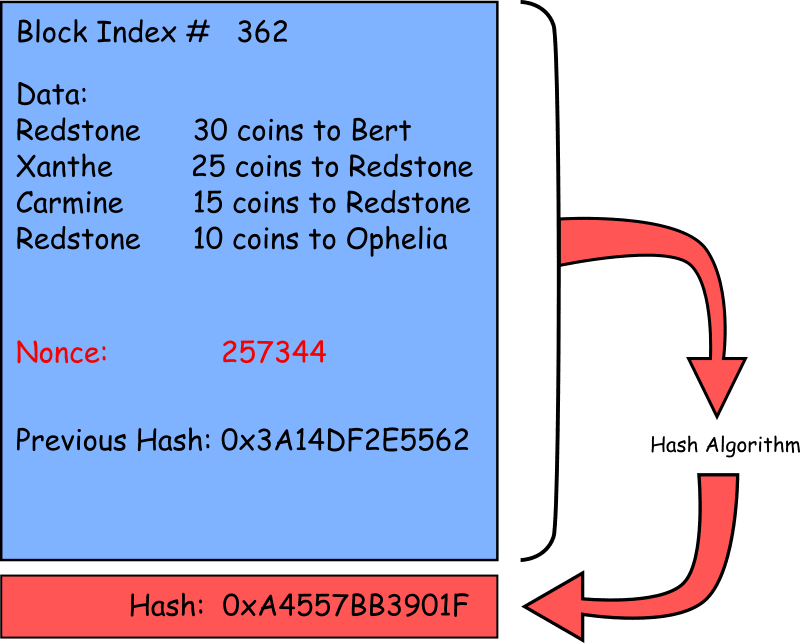
Most of the contents of the block are fixed: the block index, the data and the previous hash are all values that must remain unchanged – that’s why we’re adding them to a blockchain in the first place! If we run these values through a hash algorithm we will always get the same hash value.
The only way to manipulate the hash value for the block is to include an entity that we can change. In this case, it is the Nonce, or ‘number used once’. Any change to this number will give us a completely different hash value and we will not be able to predict what that hash value will be.
The puzzle for the miner to solve is to find a nonce that will create a hash value below an arbitrary target value. For example, find a hexadecimal hash value that has four leading zeros i.e. the 16 leading bits are all zeros.
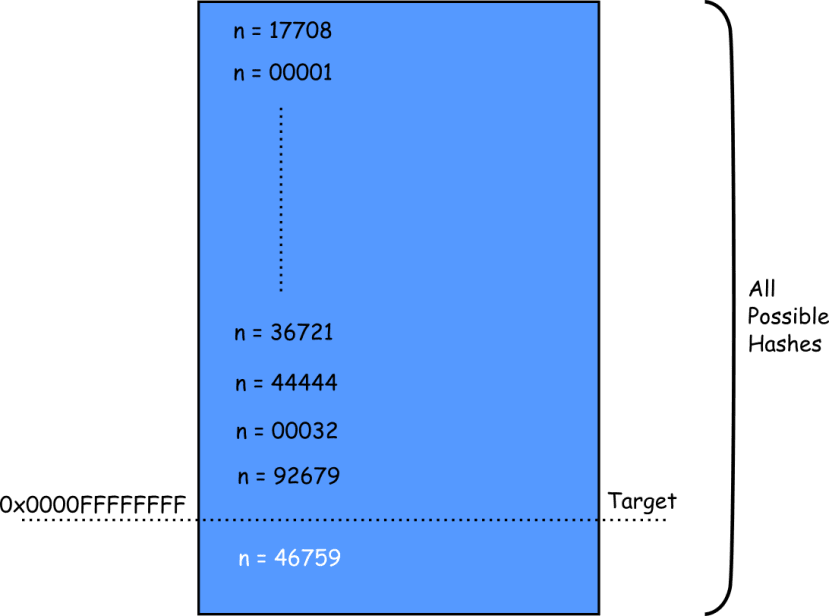
There is no other way to solve this puzzle than by brute force: trying every combination of nonce from zero up until you get a hash that meets the requirement. The more leading zeros that are required, the harder the puzzle is to solve. Each bit added doubles the average solution time. However, once you have the nonce, it is really easy for the system to verify.
The first miner to produce a nonce that is verified by the system will get to write the block onto the chain.
This example mechanism is similar to the original Hashcash PoW system proposed as a denial-of-service countermeasure and is also used by some cryptocurrencies, including Bitcoin, as part of their mining algorithm.
The significant downside to this form of consensus protocol is the increasing amount of computing power (and hence energy) that is required to run a blockchain in this way. For example, the Bitcoin protocol is designed so that it will take an average of 10 minutes to solve. As more mining nodes join the network, the difficulty of the puzzle is varied to keep the solution time the same.
As of 2018, computers on the Bitcoin network were calculating 343 Petahashes (3.43 x 1017) per second which (according to written testimony to the US Senate) is sucking up nearly 1% of global electricity production! You can keep track of Bitcoin’s energy consumption here.
Proof of Stake
An alternative approach to consensus is Proof-of-Stake (PoS). In this scheme, the next node to create a block is chosen through a pre-defined combination of random selection, size of token holding (e.g. amount of cryptocurrency and also known as the ‘stake’) and length of time the stake has been held.
If the selection was simply on stake size, then the same user would always be chosen creating a defacto centralisation, as the user with the ‘prime stake’ would have a permanent advantage. They would always be the one to create the next block.
This is where the randomisation comes in. Generally speaking, we want the probability of being the creator of the next block (known as a ‘forger’ or ‘minter’ rather than a ‘miner’) to be proportional to the relative size of the stake.
For example, consider a cryptocurrency that we will call Redstones. In the pool of potential forgers, we have Xanthe who holds 800 Redstones, Bert who has 600 Redstones, Carmine who has 400 Redstones and Ophelia who has 200 Redstones. For each block to be written, Xanthe has a 40% chance of being chosen, Bert has a 30% chance, Carmine has a 20% chance and Ophelia has a 10% chance.
This does remove the large power consumption element of PoW consensus protocols, but we do have another set of problems that need mitigating by further validation mechanisms.
The first is malicious intent by one or more large stakeholders, who could sow chaos by virtue of being given the highest amount of opportunity to write and validate blocks. This opens the door to numerous attack methods, including Bribe Attacks.
There is also the problem of the blockchain-implementation founders having such large stakes at the outset that they have veto power over the rest of the network and the associated problem of stake hoarding which makes it impossible for others to acquire stakes and in a currency could mean that there is very little free currency to go round.
One solution to these problems is combining randomisation with ‘coin age’, which is the product of number of coins multiplied by number of days the coins have been held. To be eligible to write a block, a node’s coins must have been held for 30 days. Larger and older token sets will have a higher probability of signing a block, up to a ceiling of 90 days: after this point, the maximum probability has been reached and cannot go any higher. However, if a stake of tokens is selected to write a block, the stake returns to a zero-day age and must wait 30 days before it can become eligible to write again. This is the basic system used by Peercoin.
Another solution that is gaining traction is:
Delegated Proof of Stake
This is a system that uses Authority nodes, which tend to be referred to a ‘delegates’. These systems will tend to use real-time voting in conjunction with ‘reputation’ to decide who the fixed number of delegates are at any given time.
Active delegates must be voted for by token holders, whose voting weight is determined by the amount of base token they hold. In some implementations, delegates must deposit funds into a time-locked account which can be confiscated in cases of malfeasance.
If the reputation of a delegate falls below a certain level, they will be replaced by a back-up delegate who will take over proposing and validating blocks from the dropped delegate.
Summary
In this part, we have looked at the different types of blockchain node you may run into and some different protocols that can be used to get consensus across the nodes of a peer-to-peer network. I have deliberately left out most of the pro/con arguments for each type of consensus protocol as many are pretty esoteric and can lead down extended rabbit holes. The arguments are ongoing and can get quite heated between different camps, without being all that edifying to someone trying to decide if blockchain suits their application.
In the final part of this series, we will look at Byzantine fault tolerance and how systems cope with large scale errors.