Klassische Automatisierung trifft auf die fremde Welt der IT: Teil 1
Artikel folgen
 Dave von DesignSpark
Dave von DesignSpark
Wie finden Sie diesen Artikel? Helfen Sie uns, bessere Inhalte für Sie bereitzustellen.
Dave von DesignSpark
Vielen Dank! Ihr Feedback ist eingegangen.
Dave von DesignSpark
There was a problem submitting your feedback, please try again later.
Dave von DesignSpark
Was denken Sie über diesen Artikel?

Als ich in den Siebzigern mit EDV begann, war es ganz natürlich, die Hardware des Prozessors zu verstehen. Ich musste jedes einzelne Byte und seine RAM-Adresse auf einem Nummernblock eingeben. Wenn ein kB RAM gefüllt war, musste der Inhalt kontrolliert werden, indem man seine 7-Segment-Anzeige ein zweites Mal durchlas, bevor man die „Run“-Taste drücken konnte. Schalter und LEDs zu verbinden, war die normale Art, „Nutzern“ die Interaktion mit der Software zu ermöglichen. Es handelte sich also eindeutig um „Physical Computing“. Später habe ich in der Universität gelernt, wie man mit FORTRAN Berechnungen durchführt. Ich durfte den Computer nicht einmal anfassen. Wir mussten Löcher in Pappbögen (sogenannte „Lochkarten“) stanzen und ein „Operator“ gab diese Karten in den Computer ein, der mehr oder weniger aus einem Raum voller 19-Zoll-Schränke bestand. Am nächsten Tag konnten wir die Rechenergebnisse in Form von Ausdrucken oder Lochkarten einsammeln. Seitdem pendle ich zwischen diesen beiden Welten des Physical Computing und der klassischen IT. Sie sind sehr unterschiedlich und spezialisiert. Häufig verstehen die Experten der einen Welt nicht, worüber die Experten der anderen sprechen oder warum sie Schwierigkeiten in Problemen sehen, die in ihrer eigenen Welt nicht existieren.
Natürlich wurden die Tools und Regeln für diese beiden Computerthemen in der Vergangenheit unterschiedlich festgelegt, um ihre spezifischen Ziele zu erreichen. Und dies scheint eines der größten Hindernisse für die schnelle Entwicklung des IIoT („Industrielles Internet der Dinge“) zu sein. In dieser Artikelserie werde ich einige der Hauptunterschiede erläutern. Hoffentlich werden Sie erkennen, warum Safety und Security in der Automatisierungsbranche vor der Industrie 4.0 selten zusammentrafen oder warum der zyklische Betrieb eines Zustandsautomaten nicht die beste Architektur für ein Betriebssystem wie MS Windows ist. Vielleicht sind Sie eher ein Experte von der IT-Sorte und möchten wissen, was eine SPS-Architektur („speicherprogrammierbare Steuerung“) so einzigartig macht. Dann lesen Sie weiter…
Teil 1
Deterministische und probabilistische Systemarchitekturen im Vergleich
In der Automatisierungsbranche sind „Dinge“ die Domäne der klassischen Ingenieure. Sie entwickeln integrierte Systeme oder programmieren SPS („speicherprogrammierbare Steuerung“), um komplexe Maschinen für Fertigungsprozesse zu steuern. Ihre Systemarchitektur zielt auf maximale Zuverlässigkeit ab und ist oft so reduziert wie möglich. Die Dinge müssen dieselben Aufgaben zuverlässig wieder und wieder ausführen, oftmals ohne jegliche Interaktion mit Menschen. So genannte HMIs (Mensch-Maschine-Schnittstellen) ermöglichen die Überwachung und Anpassung von Prozesswerten durch Menschen, sind jedoch kein Kernbestandteil der zentralen Steuerungsalgorithmen. Ich werde versuchen, Ihnen einen Eindruck davon zu vermitteln, wie sich diese Art von Architektur entwickelt hat.

Abb. 1: Einfacher Logikschaltkreis. Die LED leuchtet auf, wenn beide Tasten gedrückt werden.
Zu Beginn wurde Physical Computing durch die Kombination von binären Logikgattern durchgeführt. Wie in Abbildung 1 zu sehen, gab es zwei Schalter (z. B. binäre Sensoren wie Lichtschranken). Wenn beide geschlossen werden, leuchtet eine LED auf. Überlegen Sie sich nun eine Möglichkeit, eine Schaltfolge durch solche Logikgatter zu überwachen. Das Ergebnis ist eine „getaktete Logik“, die in Zyklen arbeitet (Abb. 2).
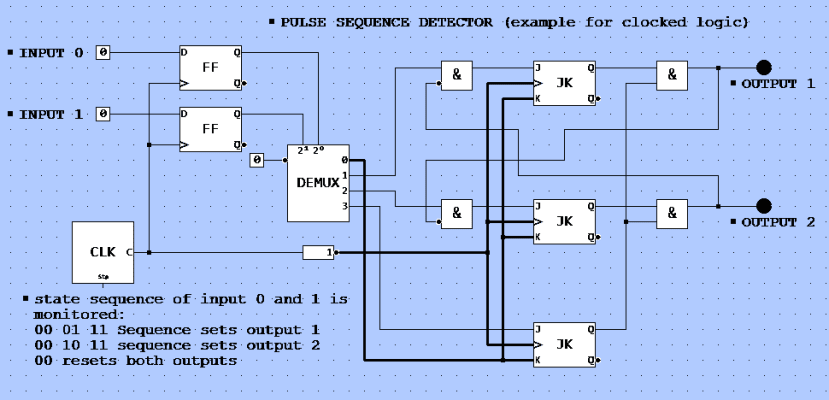
Abb. 2: Beispiel für eine getaktete Logik. Sie können die Logik über diesen Link simulieren:http://simulator.io/board/Yc9tpDmfyO/3
Eine SPS funktioniert wie eine solche getaktete Logik. Von Ihrem SPS-„Programm“ können mehrere Gatter verbunden werden (Ausgänge an Eingänge), um diese Steuereinheit flexibel zu machen (in den frühen SPS gab es tatsächlich eine Reihe von Logikblöcken – daher der Name – während heute ein Prozessor diese Aufgabe übernimmt). Im Kern steht jedoch immer ein zyklischer Betrieb: Abruf einer „Momentaufnahme“ aller Eingänge, Berechnung binärer Operationen auf deren Grundlage und Einstellung aller Ausgänge. Daher sind die Logikoperationen von Eingängen und definierten „internen Zuständen“ (gepuffert in Logikschaltkreisen namens „Flipflops“) abhängig, die alle in einer Art „Momentaufnahmepuffer“ („Latch“) gepuffert werden müssen, bevor die SPS binäre Berechnungen durchführt. Die Ergebnisse werden erneut gepuffert, bevor sie alle Ausgänge gleichzeitig umschalten (Abb. 3). Diese Pufferung des sogenannten „Prozessabbilds“ ist entscheidend, um Fehlinterpretationen zu vermeiden.
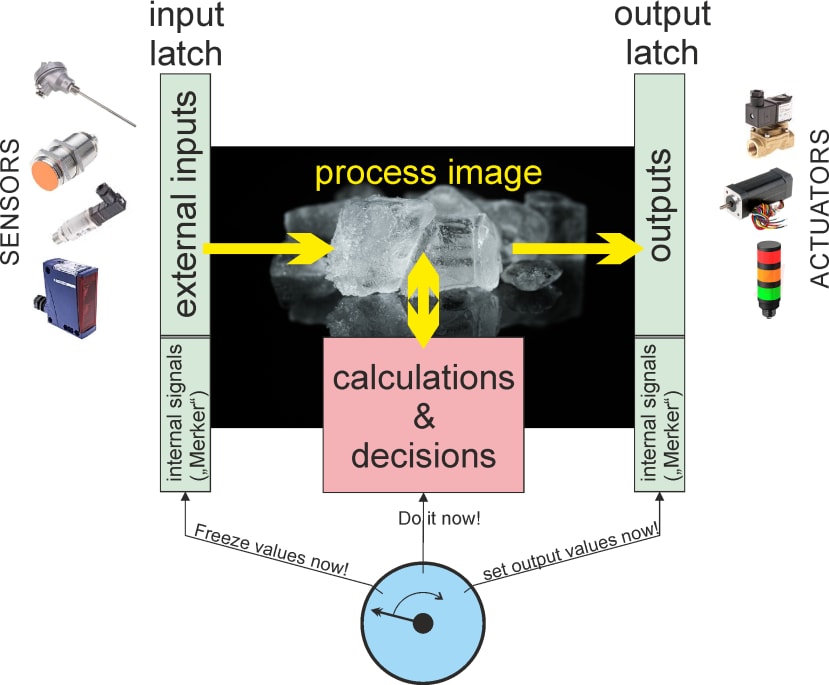
Abb. 3: Zyklischer Betrieb einer SPS mit einem „Prozessabbild“.
Jede Sequenz benötigt eine Uhr, um „vorher“ und „nachher“ zu unterscheiden. Das Signal (Eingang) zu takten, bedeutet jedoch, dass es „abgetastet“ werden muss. Die Taktrate ist also eine Abtastrate und wie Nyquist mathematisch bewiesen hat, kann man nur solche Signale zuverlässig erkennen, die nicht kürzer als das Doppelte der Abtastrate sind. Nehmen wir das Beispiel aus Abbildung 2: Wenn sich ein Objekt durch beide Lichtstrahlen bewegt, ergibt sich je nach Bewegungsrichtung immer die Reihenfolge „00 – 01 – 11 – 10 – 00“ oder „00 – 10 – 11 – 01 – 00“. Die Taktlänge sollte kürzer sein als die Hälfte der Zeit zwischen zwei Statuswerten, um eine solche Sequenz zu erkennen. Wenn die beiden Lichtschranken zu unterschiedlichen Zeiten abgetastet würden, wäre die Erkennung äußerst kompliziert oder gar unmöglich. Um eine minimale Taktrate zu berechnen, werden gleichzeitig abgetastete Signale vorausgesetzt.
Nyquist für DummiesE. Shannon führte den Begriff „Nyquist-Frequenz“ in der Signaltheorie ein, als er an „zeitdiskreten Systemen“ arbeitete – keine Sorge, es klingt komplizierter als es ist. Wenn wir uns ein digitales Signal ansehen, ist es leicht zu verstehen: Signalfrequenz zu hoch => „Signal-Aliasing“ (roter Punkt): |
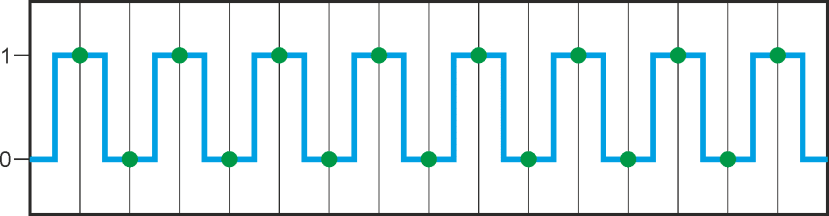
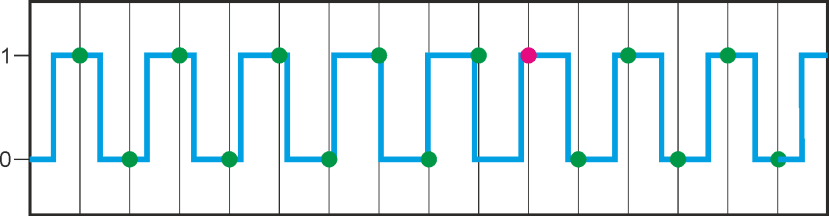
Dieses sequenzielle Konzept der Abtastung eines Prozessabbilds, der Durchführung von Berechnungen auf Grundlage der gepufferten Eingangswerte und der Pufferung der Ergebnisse bis zum Ende der Berechnung, bevor die Ausgänge gleichzeitig umgeschaltet werden, ist für ein äußerst vorhersehbares System von entscheidender Bedeutung. Es wurde später auch von integrierten Controllern übernommen, die Zustandsautomaten verwenden. Jeder Zyklus des Zustandsautomaten beginnt mit einem definierten Zustand und kann je nach Signalstatus mit dem Umschalten in einen anderen Zustand enden. Man kann das Konzept solcher Controller auf eine einfache Aufgabe reduzieren: die „zyklische Umschaltung des Status (und des Ausgangs) gemäß den Eingangs- und internen Zuständen“. Ein solcher Controller funktioniert absolut vorhersehbar und zuverlässig („deterministisch“), da zum Entwurfszeitpunkt jeder mögliche Zustand sowie die Statusübergangsregeln bekannt sein müssen.
Die EN 61131 ist eine der zentralen Normen, die dieser Architektur folgen, und wurde eingeführt, um die Verhaltensweise von Controllern in der Automatisierungsbranche zu definieren. Sie definiert zudem Programmiersprachen wie Kontaktplan (KOP), Funktionsblockdiagramm (FBD), sequentielles Funktionsdiagramm (SFC) oder Instruktionsliste (IL), die die historischen elektronischen Wurzeln der SPS-Technologie widerspiegeln (z. B. ist „Kontaktplan“ sehr eng an das Schaltbild einer digitalen Logik angelehnt).
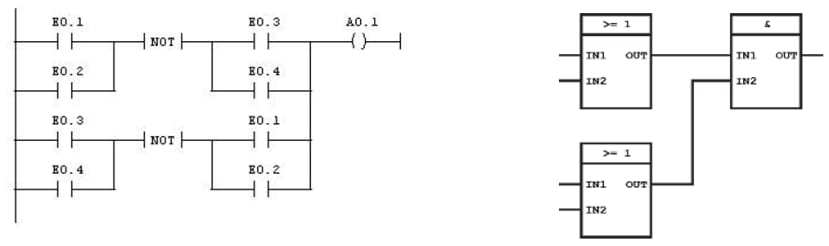
Abb. 4: Beispiele für SPS-Programme in KOP (links) und FDB (rechts).
Um solche „Dinge“ mit der Cloud zu verbinden, muss eine andere Welt mit unterschiedlichen Zielen und Regeln betreten werden: die klassische Welt der IT. Häufig findet man hier eine Trennung der sogenannten „Backends“ (mit Datenbanken zum effektiven Speichern und Abrufen von Massendatensammlungen) und „Frontends“ (hauptsächlich PC-basierte Anwendungen mit einer hochgradig interaktiven GUI). Man könnte sogar sagen, dass die Interaktion zwischen Daten und Menschen die Grundlage der klassischen IT darstellt, während die Interaktion zwischen Sensoren und Aktoren in der Automatisierung die Domäne der Controller ist. Daher ist die Systemarchitektur in der IT oft für maximale Effizienz, Wiederverwendbarkeit, Nutzerfreundlichkeit und größtmöglichen Komfort optimiert. Intelligente Benutzeroberflächen (UIs), objektbasierte Programmiersprachen und Multitasking-Betriebssysteme passen gut zu diesen Zielen.
Zyklische Betriebssoftware wäre eine Verschwendung von Ressourcen. IT-Systeme verwenden häufiger ein ereignisbasiertes Konzept: Sie klicken auf eine virtuelle Schaltfläche, was ein „Ereignis“ in der Software veranlasst. Dieses Ereignis löst alle verknüpften Prozesse aus. Hintergrundprozesse (oft als „Daemons“ bezeichnet) überwachen die Maus kontinuierlich, um einen Klick zu erkennen oder andere Aufgaben auszuführen. Diese Daemons arbeiten größtenteils unabhängig und asynchron. Andere Prozesse können sie abonnieren, um Nachrichten zu erhalten, wenn bestimmte Ereignisse auftreten. Es werden also „Dienste“ von Backend-Prozessen angeboten. Diese Prozesse stellen ihre Dienste für Client-Prozesse bereit.
Während eine SPS in der Automatisierung einen Schalter zyklisch fragt, ob er geschlossen ist, würde ein Betriebssystem wie Linux das folgende Szenario organisieren: Der Tastaturdienst sendet eine Nachricht, sobald eine Taste gedrückt wird. Jede Anwendungssoftware, die diese Nachricht abonniert hat, erhält sie mit minimaler Verzögerung und kann darauf reagieren oder auch nicht. Die Kommunikation zwischen einem Dienst und einem Client erfolgt in der Regel auf Nachrichten- und Ereignisbasis. Sie verwendet genau definierte Schnittstellen, die die einzige Abhängigkeit zwischen ihnen darstellen. Da sie ansonsten voneinander unabhängig sind, können Dienst- und Clientprozesse auf verschiedenen Systemen laufen, was häufig auch der Fall ist (z. B. „Backend“- und „Frontend“-Systeme). Solche Server-Client-Strukturen ermöglichen eine verteilte und hochgradig skalierbare Architektur. Ein moderner Cloud-Anbieter wie AWS bietet über tausend Dienste und Millionen von Clients können diese gleichzeitig über das Internet nutzen.
Diese Art von Architektur ist also alles andere als zustandsbasiert: Die Arbeit mit vielen unabhängigen und asynchronen Prozessen führt zu einem weniger vorhersehbaren System. Die Anzahl der möglichen Zustände ist in der Regel zu hoch, um vollständig bekannt zu sein und bei der Entwicklung berücksichtigt zu werden. Andererseits sind solche Systeme aufgrund der Skalierbarkeit und der objektorientierten Designprinzipien bei der Arbeit mit Massendaten nahezu unbegrenzt. In vielerlei Hinsicht sind sie uns selbst sehr ähnlich: multitaskingfähig, hochgradig interaktiv, kommunikationsfreudig und anpassungsfähig auf Kosten von Zuverlässigkeit und Geschwindigkeit. Kein Wunder, dass die IT dafür prädestiniert ist, mit Menschen zu interagieren (GUI). Kein Wunder, dass die Kommunikation zwischen den Systemen eine viel „sozialere Note“ hat (wir werden dies in Teil 2 genauer betrachten). Und kein Wunder, dass „probabilistisches Computing“ (mit statistischen Methoden für Entscheidungen) maschinelles Lernen und KI (künstliche Intelligenz) ermöglicht.
Abb. 5: IIoT – hier trifft Automatisierung auf IT.
Wenn Automatisierungsingenieure ihr deterministisches Zuhause mit dieser fantastischen neuen probabilistischen Welt verbinden möchten, müssen sie verstehen, dass sie auf diesen „menschlichen“ Eigenschaften basiert. Die Verbindung der Cloud mit realen Maschinen bringt andererseits neue Risiken mit sich und IT-Techniker müssen die Grundlage zuverlässig funktionierender Automatisierung verstehen.
In Kürze verfügbar
In Teil 2 geht es um Feldbusse im Vergleich zu Internetprotokollen, in Teil 3 um Safety und Security und zu guter Letzt in Teil 4 um Open-Source versus Schutz von IP.
Kommentare