NVIDIA Jetson Nano使用Tensor RT加速YOLOv4神經網路推論
关注文章
 戴夫来自 DesignSpark
戴夫来自 DesignSpark
你觉得这篇文章怎么样? 帮助我们为您提供更好的内容。
戴夫来自 DesignSpark
Thank you! Your feedback has been received.
戴夫来自 DesignSpark
There was a problem submitting your feedback, please try again later.
戴夫来自 DesignSpark
你觉得这篇文章怎么样?
|
作者 |
張嘉鈞 |
|
難度 |
普通 |
|
材料表 |
YOLOv4

這邊我們就不會對YOLOv4的技術進行介紹,大致上可以了解YOLOv4是由很多強大的技巧所組成,是現階段教育界、商業都很常用到的一個技術。如果一一描述需要兩篇的文章,而網路上很多介紹很詳細的文章,大家可以直接去搜尋、查看;本篇著重在Github實作以及介紹TensorRT加速的方法給大家。
如何使用YOLOv4
首先要先建置darknet的環境,先下載darknet的github:
$ git clone https://github.com/AlexeyAB/darknet.git
$ cd darknet
接著需要修改一下Makefile,在官方的github當中有提到Jetson TX1/TX2的修改方法,Jetson Nano也是比照辦理,前面的參數設定完了,往下搜尋到ARCH的部分,需要將其修改成compute_53:
GPU=1
CUDNN=1
CUDNN_HALF=1
OPENCV=1
AVX=0
OPENMP=1
LIBSO=1
ZED_CAMERA=0
ZED_CAMERA_v2_8=0
......
USE_CPP=0
DEBUG=0
ARCH= -gencode arch=compute_53,code=[sm_53,compute_53]
接著就可以進行build的動作了:
$ make如果Build darknet的時候出現找不到nvcc的問題,如下圖:

可以在Makefile當中的NVCC後面新增絕對位置:

接著重新make一次如果沒有錯誤訊息就代表Build好了!
使用YOLOv4進行推論
我們需要先下載YOLOv4的權重來用
wget https://github.com/AlexeyAB/darknet/releases/download/darknet_yolo_v3_optimal/yolov4.weights \
-q --show-progress --no-clobber
基本的推論方法有三種:圖片、影片、攝影機 ( 即時影像 ),我們一一來介紹使用方法!主要執行除了darknet的執行檔之外還需要給予 模式、資料集、配置檔:
./darknet detector test ./cfg/coco.data ./cfg/yolov4.cfg ./yolov4.weights可以使用 --help來幫助查看:
./darknet detector --help
如果要開啟圖片的話需使用 test模式,他會在執行之後要你輸入圖片的位置,不過這邊要注意的是按任意建離開後,圖片不會幫你儲存:
./darknet detector test cfg/coco.data cfg/yolov4.cfg yolov4.weights -thresh 0.25

如果想要指定圖片並且將結果儲存下來則可以增加 -ext_output 的選項,執行完會儲存成 prediction.jpg,這邊我用另一張圖片當示範 ( Ximending.jfif ):
./darknet detector test cfg/coco.data cfg/yolov4.cfg yolov4.weights -ext_output Taiwan.jfif

如果要使用影片或攝影機的話則是透過 demo 的指令來操作,這邊如果用 -ext_output會直接覆蓋掉原本的,我希望可以另存成別的檔案則需要用到 -output_filename來執行:
./darknet detector demo cfg/coco.data cfg/yolov4.cfg yolov4.weights sample.mp4 -out_filename sample_.mp4
使用攝影機進行影像即時辨識需要在後面參數導入 -c:
$ ./darknet detector demo cfg/coco.data \
cfg/yolov4.cfg \
yolov4.weights \
-c 0
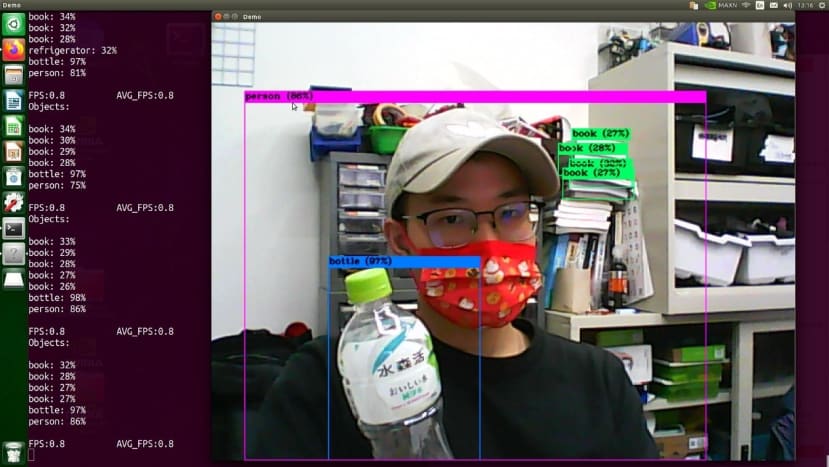
可以看到FPS大概會在0.8左右 ( 於終端機畫面上 ),有明顯的延遲感,但是辨識的結果還算可以。
修改輸入維度大小
我們也可以直接修改輸入輸出的圖片大小,我用簡單一點的語法來操作,複製一個yolov4.cfg並命名為yolov4-416.cfg,並直接用nano去修改輸入大小成416,這邊使用&&的意思是讓前一個指令完成之後再接續下一個指令:
$ cp cfg/yolov4.cfg cfg/yolov4-416.cfg && nano cfg/yolov4-416.cfg
在下方的圖片可以看到,縮小圖片之後FPS就直接提高了許多,從0.8升到了1.5;注意!這個示範只是提供了可以修改輸入大小的方法,因為有時候你用的圖片或影片大小不同就需要稍微修改一下;官方較推薦的大小是608以上,縮小圖片可能會導致辨識結果變差:

使用結構更小的YOLO ( Yolov4-Tiny )
下一種加快速度的方法是使用yolov4-tiny.weights,一個更小型的yolov4,這邊的小型指的是神經網路模型的結構,一般我們都會使用在運算能力相較於顯示卡低的裝置上 ( 例如 : 邊緣裝置 ),實作的部分,我們先將該權重下載下來:
$ wget https://github.com/AlexeyAB/darknet/releases/download/darknet_yolo_v4_pre/yolov4-tiny.weights接著使用攝影機來開啟,注意這邊的config (cfg) 檔案需要更改成 yolov4-tiny.cfg,因為yolov4跟yolov4-tiny的架構有所不同,config檔案當中所提供的就是神經網路的結構:
$ ./darknet detector demo cfg/coco.data \
cfg/yolov4-tiny.cfg \
yolov4-tiny.weights \
-c 0
可以看到FPS已經來到了14,延遲感明顯降低許多:

使用TensorRT引擎加速
接下來是TensorRT的版本,稍微簡短介紹一下Tensor RT ( 以下簡稱 TRT ),它是一個加速引擎可以運用在有CUDA核心的NVIDIA顯示卡當中,如果要使用TRT引擎加速需要先將神經網路模型轉換成ONNX的格式才行。
下載、安裝環境
坊間利用Yolov4做了很多應用,而轉換這塊也已經有人完成了,所以我們直接使用網路上提供的Github來實現即可:
$ git clone https://github.com/jkjung-avt/tensorrt_demos.git下載下來之後可以直接到ssd資料夾中執行 install_pycuda.sh:
$ cd ${HOME}/project/tensorrt_demos/ssd
$ ./install_pycuda.sh如果顯示nvcc not found的話則需要手動修改 install_pycuda的檔案,我們需要將cuda的絕對位置存放到環境變數當中:
透過nano編輯器開啟並且將iffi中間的內容修改如下,原本的內容記得要註解掉:
$ nano ./install_pycuda.sh
安裝完之後應該會顯示 finished processing dependencies,也可以使用pip3 list去查看pycuda是否有安裝成功:

接著需要安裝onnx,一開始先安裝相依套件,接著在安裝onnx 1.4.1版本:
$ sudo apt-get install protobuf-compiler libprotoc-dev
$ sudo pip3 install onnx==1.4.1都完成之後我們需要先將相關的程式build起來:
$ cd ${HOME}/project/tensorrt_demos/plugins
$ make

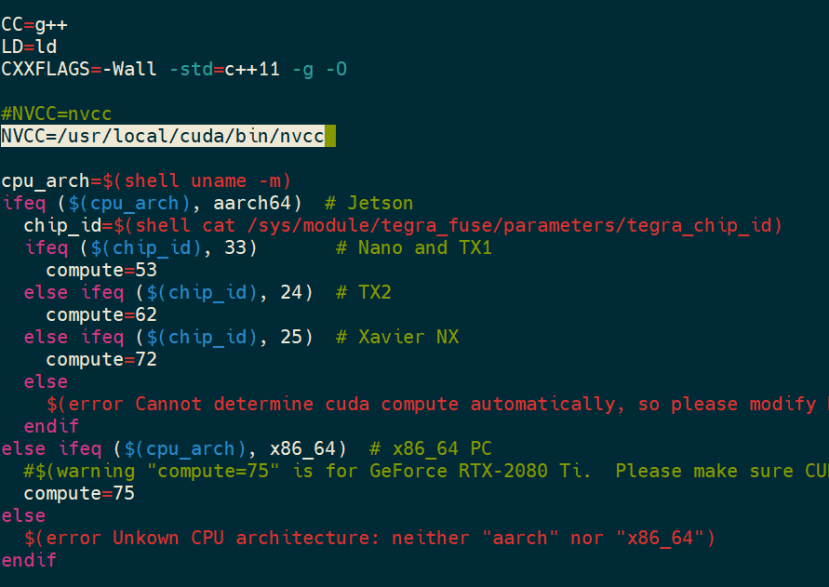
可以注意到又有nvcc的問題了,這時候一樣需要修改Makefile來解決,將原本的NVCC=nvcc修改成NVCC=/usr/local/cuda/bin/nvcc即可:
下載並轉換yolo模型
接著需要下載模型的權重,你將會看到它下載了yolo3跟yolo4的三種不同版本,並且直接放在當前資料夾當中,這邊可以注意到下載的模型與剛剛的YOLOv4相同,所以其實也是可以直接用複製的方式或是直接寫絕對位置進行轉換:
$ cd ${HOME}/project/tensorrt_demos/yolo
$ ./download_yolo.sh

最後可以執行 yolo_to_onnx.py 將yolo的權重檔轉換成onnx檔案,接著再編譯成TRT可用的模型,在onnx_to_tensorrt.py我會建議使用 -v 來看到進度,不然看著畫面沒動靜會有點緊張:
$ python3 yolo_to_onnx.py -m yolov4-416
$ python3 onnx_to_tensorrt.py -m yolov4-416 -v
轉換ONNX大約耗費15分鐘,會儲存成yolov4-416.onnx,接著轉換TRT大概也是差不多的時間,最後會儲存成yolov4-416.trt。
使用TRT運行YOLOv4-416
這邊我們使用 --usb 代表使用USB攝影機, --model則是選擇特定模型:
$ cd ${HOME}/project/tensorrt_demos
$ python3 trt_yolo.py --usb 0 --model yolov4-416

左上角有顯示FPS數值,實測下來大約都會在 4.2~4.5之間,我們這次使用的是416維度,相較沒有使用TensorRT引擎的Darknet ( FPS 1.5),快了將近3倍。
剛剛輸入的部分使用usb攝影機,而作者很貼心地都寫得很完善了,在utils/camera.py的部分可以看到輸入的內容選項,也可以直接使用 --help來查看:

這裡有提供圖片( --image )、影像 ( --video )、重複影片 ( --video_lopping )、網路攝影機 ( --usb ) 等都可以使用。
使用TRT運行YOLOv4-Tiny-416
接下來為了追求更快的速度,我們當然要來實測一下tiny版本的:
$ python3 yolo_to_onnx.py -m yolov4-tiny-416
$ python3 onnx_to_tensorrt.py -m yolov4-tiny -416 -v
$ cd ${HOME}/project/tensorrt_demos
$ python3 trt_yolo.py --usb 0 --model yolov4-tiny-416
使用tiny的話FPS來到18.05,基本上已經有不錯的效果了!不過因為是tiny所以辨識的成效沒有預期中的好:

使用TensorRT運行模型比較表
此表從jkjung-avt/tensorrt_demos的github當中移植過來,其中mAP是常用評估物件偵測的演算法,在yolov3的部分 tiny雖然有不錯的FPS但是mAP相較yolov4卻是差了不少,目前我認為yolov4-tiny-416以FPS實測18左右、mAP約0.38的狀況算是較能夠接受的範圍:
|
TensorRT engine |
mAP @ |
mAP @ |
FPS on Nano |
|
yolov3-tiny-288 (FP16) |
0.077 |
0.158 |
35.8 |
|
yolov3-tiny-416 (FP16) |
0.096 |
0.202 |
25.5 |
|
yolov3-288 (FP16) |
0.331 |
0.601 |
8.16 |
|
yolov3-416 (FP16) |
0.373 |
0.664 |
4.93 |
|
yolov3-608 (FP16) |
0.376 |
0.665 |
2.53 |
|
yolov3-spp-288 (FP16) |
0.339 |
0.594 |
8.16 |
|
yolov3-spp-416 (FP16) |
0.391 |
0.664 |
4.82 |
|
yolov3-spp-608 (FP16) |
0.410 |
0.685 |
2.49 |
|
yolov4-tiny-288 (FP16) |
0.179 |
0.344 |
36.6 |
|
yolov4-tiny-416 (FP16) |
0.196 |
0.387 |
25.5 |
|
yolov4-288 (FP16) |
0.376 |
0.591 |
7.93 |
|
yolov4-416 (FP16) |
0.459 |
0.700 |
4.62 |
|
yolov4-608 (FP16) |
0.488 |
0.736 |
2.35 |
|
yolov4-csp-256 (FP16) |
0.336 |
0.502 |
12.8 |
|
yolov4-csp-512 (FP16) |
0.436 |
0.630 |
4.26 |
|
yolov4x-mish-320 (FP16) |
0.400 |
0.581 |
4.79 |
|
yolov4x-mish-640 (FP16) |
0.470 |
0.668 |
1.46 |
結語
今天帶大家稍微深入一點的了解了YOLOv4的Github,也帶大家認識了使用TensorRT針對模型進行加速的部分,相信大家應該都很快就上手了!接下來我想帶大家解析 darknet.py 並且嘗試修改成更淺顯易懂的程式碼。
评论