
 戴夫来自 DesignSpark
戴夫来自 DesignSpark
你觉得这篇文章怎么样? 帮助我们为您提供更好的内容。
戴夫来自 DesignSpark
Thank you! Your feedback has been received.
戴夫来自 DesignSpark
There was a problem submitting your feedback, please try again later.
戴夫来自 DesignSpark
你觉得这篇文章怎么样?
在日常生活中, 深度学习变得更加重要。我解锁我们的手机和街道上的智能 Led 都展示了在图像识别方面实现 AI 的例子。互联网上有很多关于 AI 的开源, 包括手写的数字识别, 以及我们如何构建自己的数据集?在本文中, 我将和您分享一个应用程序 Neural Network Console。
本文将分为4个部分,第一部分是数据集的编写,第二部分是构建网络模型,第三部分是创建数据集,最后是如何评估模型。
让我们先观看视频并设置网络概念。
https://v.qq.com/x/page/f08873ryilr.html
手势的神经网络模型

以下是每个块的基本概念。
图片包括3种颜色,红色,蓝色和绿色。 它们都被分成具有不同梯度的层,编号为0到255。

本文我们将选择红色层作为演示。

Input,神经网络输入层,指定输入大小。
MulScalar是一个将值乘以输入的函数。
ImageAugmentation随机改变输入图像。
Convolution Ox,y,m = Σ_i,j,n Wi,j,n,m Ix+i,y+j,n + bm (二维卷积) (其中O是输出; 我是投入; i,j是内核大小; x,y,n是输入索引; m是输出映射(OutMaps属性),W是内核权重,b是每个 kernel的偏差项)每个KernelShape都是我们想要卷积的窗口大小。 例如,5 * 5 png可以设置为2 * 2的kernalshape。
https://v.qq.com/x/page/q0887bb2ykm.html
Relu是一种激活函数,可以找出线性区域。
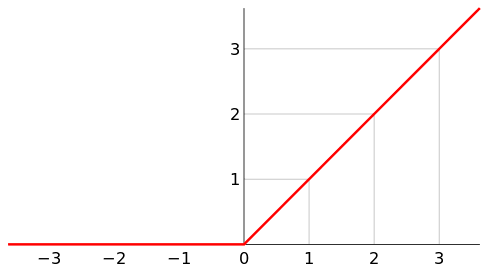
MaxPooling输出本地输入的最大值。
此maxPooling使用2x2下采样方法,该方法可减小图像的大小并获得表示信号的最大参数。 下图显示了4x4红色下层样品到2x2。

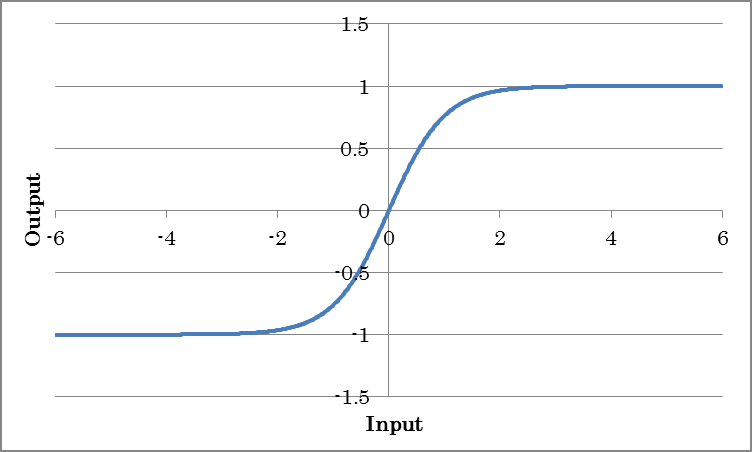
Tanh是一个激活函数,可以找出线性区域。
AFFINE
微调更好的图像比例以进行识别。
例如,当前数据是图片的四分之一,在应用仿射之后,图片将对矩阵中的每个数据乘以4,并且给出与原始数据集类似的比率以用于重新定位。

Softmax显示潜在结果列表的概率分布。
Softmax输出Softmax的输入。 当您想要获取分类问题中的概率或输出值从0.0到1.0(总计为1.0)时,可以使用此选项。
通过模型传递后的数据将给出一个权重,在将权重乘以点积后,我们用算法 ox=exp(ix) / Σ_jexp(ij) 发送结果然后我们将获得与数据成正比的概率 重量。

https://v.qq.com/x/page/i0887e4o3ps.html
下一部分将是创建数据集。
未来发展
Neural network console 可以识别脸部吗? 可以! 使用这个应用程序作为起步是有趣的。
输入不同的数据集并生成各种结果。
评论