使用长短期记忆模型(LSTM)预测天气
关注文章
 戴夫来自 DesignSpark
戴夫来自 DesignSpark
你觉得这篇文章怎么样? 帮助我们为您提供更好的内容。
戴夫来自 DesignSpark
Thank you! Your feedback has been received.
戴夫来自 DesignSpark
There was a problem submitting your feedback, please try again later.
戴夫来自 DesignSpark
你觉得这篇文章怎么样?
| 作者 | Dan 罗杰瑞 |
| 难度 | 中等 |
| 所需时间 | 2小时 |
由于我们已经讨论过如何使用像是Raspberry Pi之类的嵌入式系统来收集传感器数据,因此我们想介绍一种如何使用数据通过深度学习进行预测的方法。尤其是如果我们的数据库或存储库中已经有大量数据的话,这是一个非常有用的主题。
在执行此项目时,我们使用了以下规格:
- 操作系统: Windows 10
- GPU: Nvidia GTX1070
- RAM: 32GB
这些规格对于这个应用已经绰绰有余。但是,我们建议使用带有GPU的计算机来运行此项目,以便您可以立即看到结果。否则,训练模型的等待时间可能会花费一些时间。另一方面,这是该项目所需的库:
- keras 2.2.4
- matplotlib 2.1.1
- numpy 1.17.4
- opencv-python 3.4.3.18
- tensorflow-gpu 1.11.0
- scikit-image 0.15.0
- scikit-learn 0.19.1
- scipy 1.1.0
如同我们以往的建议,在完成项目教程之前,请先安装库。也请注意这些库可能不是最新版本,因此这个程序可能不适用于较早或较晚版本的库。
原理
我们要在此项目中使用的神经网络架构基于长短期记忆模型(LSTM)。它是一种人工循環神经网络,主要用于时间序列数据的预测。 LSTM包含一个由输入、输出和遗忘阀组成的单元。典型的LSTM单细胞如下所示:
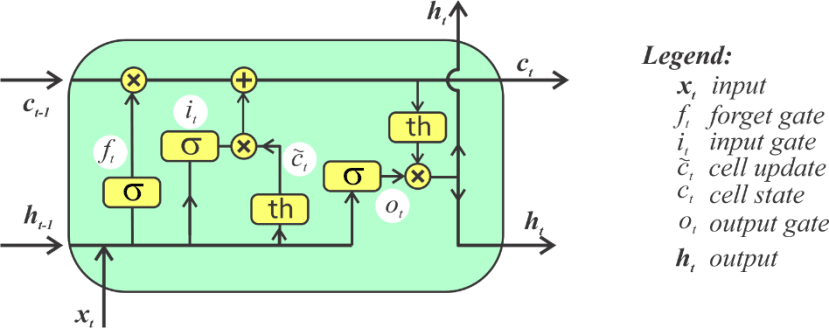
資料來源:https://bhrnjica.net/2019/04/08/in-depth-lstm-implementation-using-cntk-on-net-platform/
作为简要说明,LSTM细胞的输入是数据x的时间序列集,它经历了多个sigmoid activation阀,每个阀计算一个确定的函数以计算细胞状态。我们提供的只是LSTM工作原理非常简要的解释,有关LSTM的更多信息,最好参加一门深度学习课程以进一步理解这些概念。
软件
在学习了有关LSTM的一些知识之后,我们想了解如何将LSTM实施到程序中。要阅读本教程,请参考我们存储库中的LSTM_demo.py。
https://github.com/danrustia11/WeatherLSTM
打开演示程序后,您可以看到以下源代码:
1)首先,我们要调用运行该程序所需的库。除此之外,我们想调用一些数据条件函数。与其他LSTM演示相比,我们想在这里展示使用整理过的输入数据执行LSTM预测的重要性。正如人们所期望的那样,LSTM并不是预测的完美解决方案。如果从数据中发现的模式很少,那么LSTM仍然无法预测您的数据。因此,我们要先对数据进行条件处理。除此之外,我们希望通过设置随机数生成器来使结果可再现。

2)接下来,我们只想调用该程序所需的其他库。特别是我们希望包括正规化函数以准备数据进行训练。正规化对于提高模型效率非常重要。

3)在这里,您可以设置n_timestamp,即要用作预测输入的时间戳数(在本例中为天数)。因为我们要在进行预测之前考虑模型应检查多少数据所以这很重要。这取决于要应用在哪个方面,假设我们要进行天气预报,那么我们可能至少需要一周的数据才能预测第二天的数据。
我们这里也有训练天数train_days,这样可以确保模型根据历史数据学习几种模式,testing_days是我们要预测的天数。对于训练,我们有n_epochs,即训练所需的回合数。由于我们能够事先测试该程序,因此大约25个epoch就足以训练模型而不会过度拟合。
最后,我们有filter_on变量,用于激活数据过滤器。

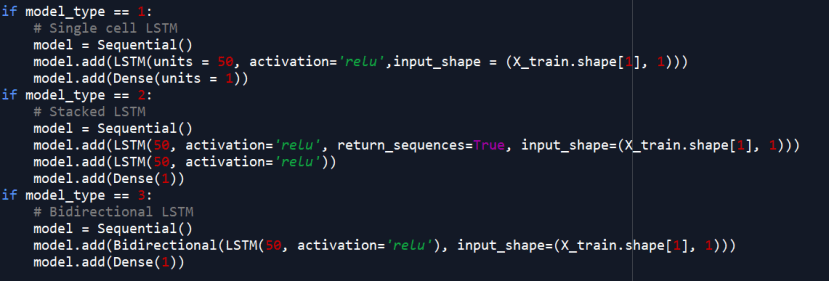
4)我们要在这里选择模型类型,我们要使用两个LSTM细胞堆叠在一起的堆叠模型。

5)我们的数据来自下方网址。我们将使用台湾环境保护局提供的台湾宜兰县的每日环境温度。

6)这边我们对数据集执行中值过滤和高斯过滤。

7)接下来,我们要根据之前设置的变量设置训练和测试数据集。

8)此处将数据标准化,范围是0到1。

9)我们的数据是根据之前宣告的分割时间戳数。

这意味着我们使用n_timestamps来预测第二天。预测程序运行n_timestamps的移动窗口(moving window)以进行预测
10)现在我们要使用Keras建构LSTM模型。
11)我们从这里开始模型训练。如果您无法运行训练程序,那么减少batch size可能是一个不错的解决方案。

12)之后我们希望基于测试数据集来预测数据,我们还希望根据正规化过程将数据转换回其原始值。

13)最后,我们要显示预测结果,包括原始数据、n个预测天数和前75天。
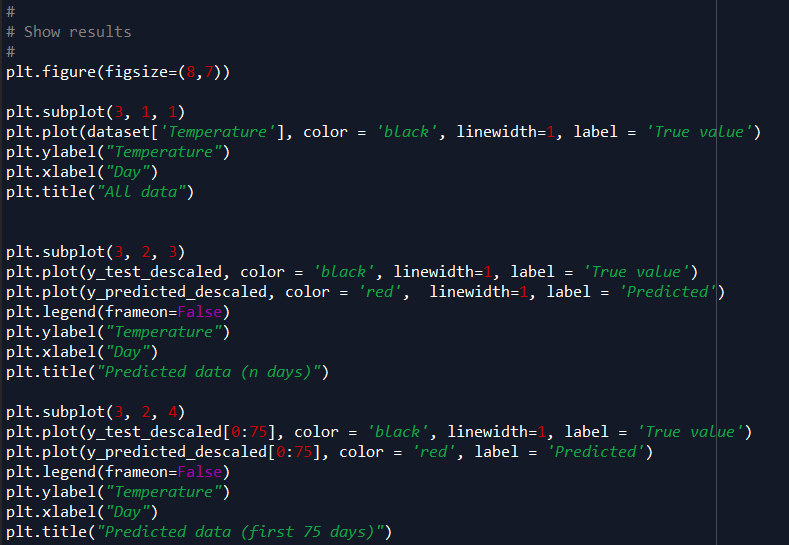
使用这些代码显示训练曲线、残差图和散点图,作为结果的参考我们还将MSE和r2包括在内。

結果
如果您使用我们的默认参数,可以看到以下结果:
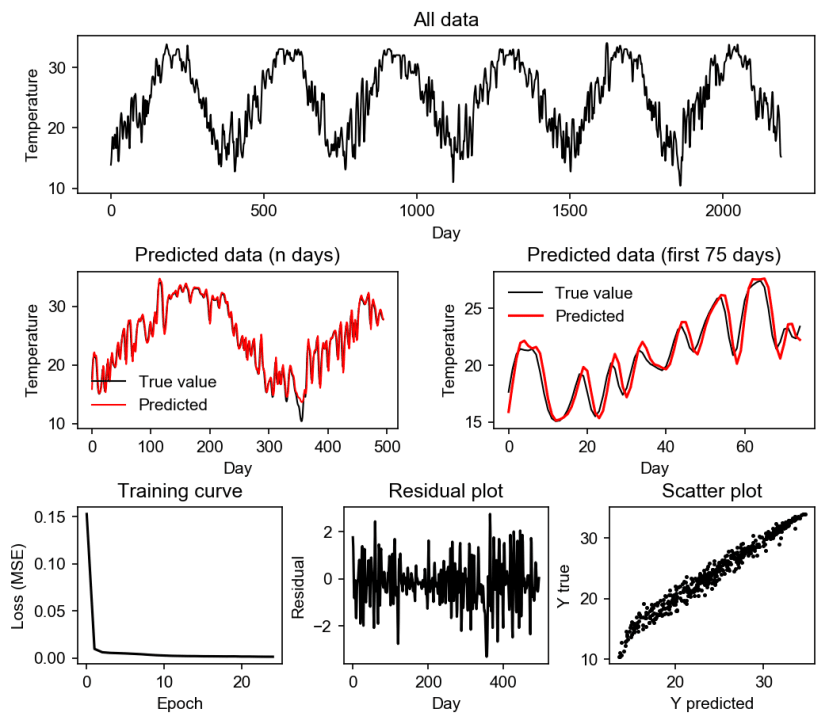
图1.堆栈式LSTM预测结果,使用10个输入天的过滤器。
从结果可以看出,我们的模型预测是成功的,但是从预测的天数(n天)可以看出,错误通常是由于数据的意外上升或下降(例如在350-360天),不过在前75天模型可以正确地遵循数据模式。
但是为了尝试调整LSTM模型,我们也使用不同的参数运行程序:

从表中可以看出,与其他类型相比,堆叠式LSTM的性能最佳,还可以看到单细胞在输入100天后效果很好,但是我们发现这种设置在计算上消耗过大,双向LSTM在输入天数较多的情况下也表现较差。
最后,我们想证明调节数据对执行LSTM来说确实很重要,常理来讲预测的准确率并不会达到99.9%,而且我们在这个专案中只是想预测温度,而不是像火山爆发这类的事件。为了证明我们的观点,以下是未经过滤的结果:
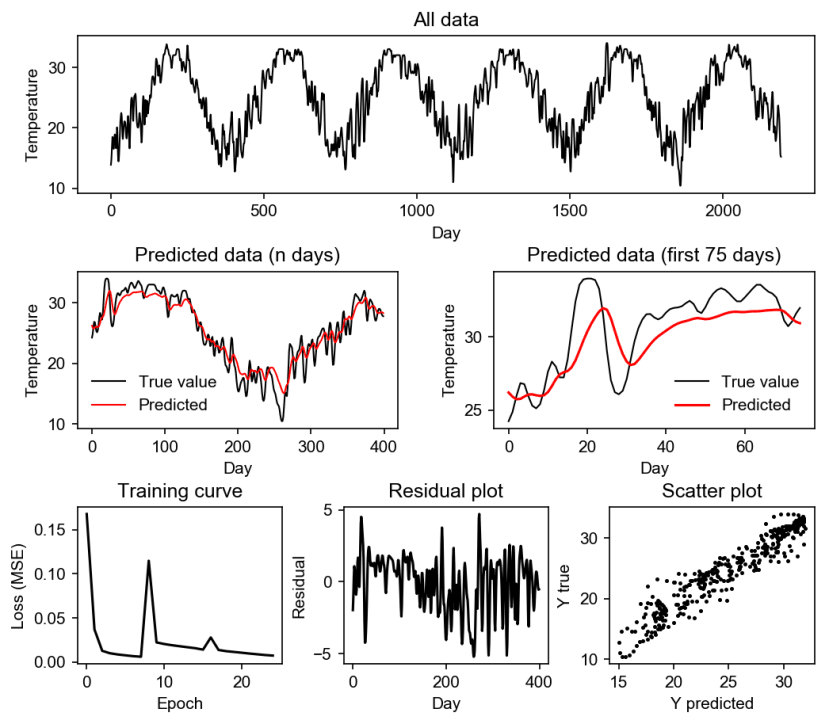
图2. 堆栈式LSTM预测结果,没有使用10个输入天的过滤器。
我们可以看到,如果没有使用过滤器,则LSTM模型只能遵循该模式,但误差幅度更大。结果仍然是会产生的,有点合理但是不是太精确。以下是对结果进行定量比较的表格:
總結
在这个项目中,我们发现LSTM是预测数据的好工具,但是从这里我们可以看到使用LSTM可以学到一些经验。首先,更多的输入天数并不真正意味着该模型将更加准确,除此之外,数据调节可能有助于使模型更准确,最后,即使我们没有显示,LSTM也需要一定数量的数据才能实际应用。从这些经验中,我们可以想象LSTM实际应用在预测股票、天气、趋势等方面。
Github:
https://github.com/danrustia11/WeatherLSTM
參考資料:
https://colah.github.io/posts/2015-08-Understanding-LSTMs/
https://www.kdnuggets.com/2018/11/keras-long-short-term-memory-lstm-model-predict-stock-prices.html
https://bhrnjica.net/2019/04/08/in-depth-lstm-implementation-using-cntk-on-net-platform/