在NVIDIA Jetson Nano上实现JetBot AI自驾车项目-03回避障碍篇(上)
关注文章
 戴夫来自 DesignSpark
戴夫来自 DesignSpark
你觉得这篇文章怎么样? 帮助我们为您提供更好的内容。
戴夫来自 DesignSpark
Thank you! Your feedback has been received.
戴夫来自 DesignSpark
There was a problem submitting your feedback, please try again later.
戴夫来自 DesignSpark
你觉得这篇文章怎么样?

|
作者 |
郭俊廷 |
|
難度 |
普通 |
上次介绍了如何让JetBot基本移动功能可以在网页上操控JetBot移动,并且使用游戏杆控制JetBot移动,拍照等等功能。
这次开始会使用JetBot摄影机让JetBot达成避开障碍物的功能。
JetBot的避障效果是使用深度学习来达成的,经过数据搜集、训练模型之后,执行程序才会有避障的效果。根据你标记的卷标来判断JetBot透过摄影机看到的画面该避开障碍物还是继续行走。
首先来看看我们训练好的成果是如何呢?
当我们看到绿色的场地直走,看到三角锥或白色的墙壁就会左转。
接着介绍深度学习
所谓的深度学习是机器学习中的一种,它是以神经网络为架构对数据进行特征学习的算法。机器学习则是从过往数据和经验中学习并找到其运行规则,而人工智能则是包含所有机器学习和深度学习的范畴,只要是让机器展现人类的智慧可以感知、推理、交流、学习、行动。
下图是人工智能、机器学习、深度学习的关系图。

机器学习可以分成四大分类:
监督式学习Supervised learning
非监督式学习Unsupervised learning
自监督式学习Self-supervised learning
增强式学习Reinforcement learning
监督式学习是有标准答案、标注 (Annotation),所有数据都有卷标过,每个卷标提供机器相对应的值来让机器学习输出时判断误差使用。 Ex. ig、fb广告推荐
非监督式学习是无标准答案 Ex: 分群、找关联、编码、异常检测
自监督式学习则是自己根据历史数据产生答案,对部分数据进行卷标,计算机只透过有卷标的数据找出特征并对其它的数据进行分类。
增强式学习是观察后,选择最大化奖励的行动。
而我们的JetBot使用的是监督式学习,把搜集到的数据标注到相对应的类别,执行相对应的动作。
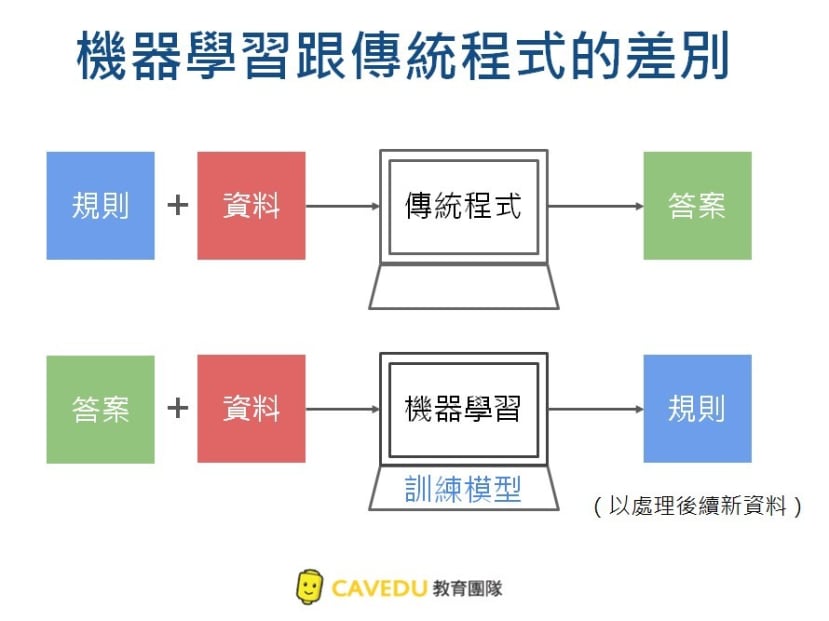
机器学习跟一般传统程序学习的差别在哪里呢?
传统程序是使用规则加上数据经过程序后得出答案的
机器学习是先有答案加上数据经过训练模型后产生规则来处理后续新的数据
使用深度学习通用的神经网络模型建立流程可以分为九个步骤
Step 1. 定义问题
Step 2. 建立数据集
Step 3. 选择评量的成功准则
Step 4. 根据资料量决定验证方法
Step 5. 数据预处理
Step 6. 建立并训练模型
Step 7. 开发出Overfitting的模型
Step 8. 粗胚的精雕细琢 - 调整参数使其变成通用模型
Step 9. 应用
JetBot把避障使用的神经网络模型精简分为三大步骤
Data Collection 资料搜集
Train Model 训练模型
Live Demo 应用范例
接着我们一一介绍这三大步骤如何操作使用,本篇先教大家如何数据搜集,以及数据搜集的一些小技巧。
在以下路径"Home > Notebooks >collision_avoidance"可以看到以下三个档案,如下图的红框处所示。

避障文件夹的档案位置
注意:
如果你是接续前一个项目继续执行此项目,执行完前一个档案的功能之后记得关闭kernel和使用窗口,才不会发生摄影机被占用等错误讯息。(相关教学请参考在"在NVIDIA Jetson Nano上实现JetBot AI自驾车项目-02控制移动篇"之说明)
二、Data Collection资料搜集
首先点选左边的路径"Home > Notebooks >collision_avoidance > data_collection.ipynb",就能打开以下的JupyterLab的Collision Avoidance - Data Collection画面。

JupyterLab的Collision Avoidance - Data Collection画面
以下是Data Collection资料搜集执流程图,根据流程图我们要先决定资料搜集时的场地背景跟灯光,还有决定甚么是障碍物甚么是可自由行走的分类,搜集数据拍照分类时的时间会比较快数据的辨识率也会比较准确。

以下是Data Collection资料搜集执流程图
在范例说明中提到:
要解决最重要的问题之一是防止JetBot进入危险的状态!我们称这种行为为避免碰撞。
尝试使用深度学习和一个非常通用的传感器:相机来解决问题。
采取避免碰撞的方法是在机器人周围创建一个虚拟的“安全气泡”,在此安全气泡内,机器人可以绕圈旋转而不会撞到任何物体。
执行此操作的方法如下:
首先我们将JetBot放置在违反其“安全气泡”的场景中,并将这些场景拍照并添加分类为blocked。
之后我们手动将机器人放置在可以安全向前移动的场景中,并为这些场景拍照并添加分类为free。
因为是使用照片来训练模型的关系,我们在搜集数据和实际执行所使用的场景跟光源请在同一场景并使用同样的光源,不然执行起来的效果会很差。
我们使用场景如下:绿色的地板为(free)
三角锥、其他障碍物、白色墙壁背景为(blocked)
首先执行第1个区块,该区块的程序先创建一个224x224像素摄影机的画面实时显示在画面上。

第2个区块,建立一个dataset文件夹里面有blocked跟free两个文件夹,用来储存等等要拍照分类的照片。

第3个区块会建立一个增加free类别跟增加blocked类别的按钮,并显示该类别有几张照片的数量。此时只是建立组件而以按下去并无任何反应。

第4个区块将定义并链接按下free跟blocked按钮所执行的动作,按下add free跟add blocked按钮会使用uuid1的命名格式储存jpg档到相对应的文件夹。
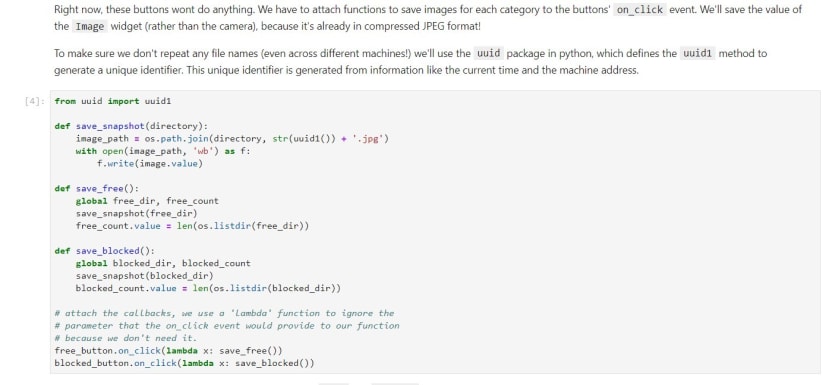
第5个区块,显示目前摄影机看到的画面,并显示add free、add blocked类别的按钮跟相片数量的窗口,此时按下去即会储存照片到相对应的文件夹。

如下图所示,目前摄影机看到的画面是有三角锥的画面,应该使用blocked类别,按下add blocked的按钮之后会在dataset文件夹里面的blocked文件夹里新增一张照片(如图的红框所示)

拍好的照片可以直接在JupyterLab点选照片文件名开启查看,如发现照片拍得不好或是分类错误可直接点选该档案右键选择Delete删除该档案。

接着重复执行搜集数据分类的动作,根据档案上的说明每个类别至少需要100张照片,尝试不同拍照的方向、不同拍照的光源、尝试各种物体/碰撞类型。
根据我们的场景blocked类别的拍照技巧为拍摄单一障碍物在正前方(各色测试)、单一障碍物在左侧、单一障碍物在右侧、双障碍物在正前方、双障碍物在两侧、手或脚遮住等等情况。
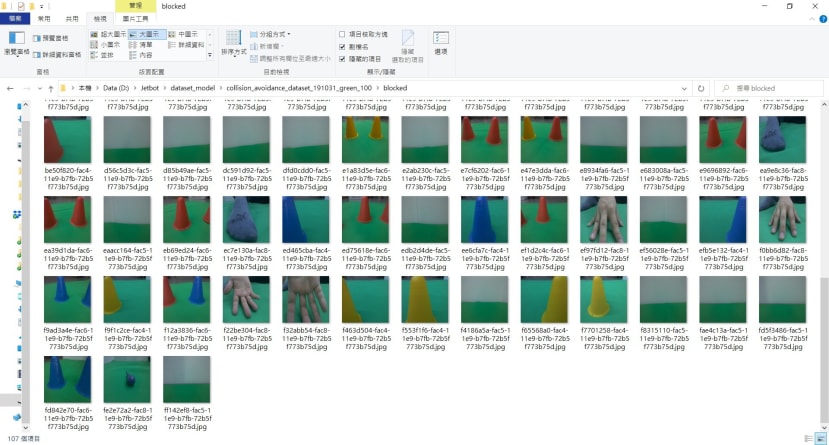
blocked文件夹的照片内容
free类别的照片则是拍摄各种光影角度跟位置来增加照片。

free文件夹的照片内容
第6个区块,可以把我们搜集到的数据压缩成zip档,预设压缩成dataset.zip为档名,可以根据您执行的日期或场景来决定该zip档的命名方式,这样下次想使用不同的情境的场地不同的障碍物才容易分辨。
更改以下指令dataset.zip的名称来更改要压缩的档名。
!zip -r -q dataset.zip dataset
以上障碍回避篇(上)-资料搜集的讲解到这边告一段落,各位有没有顺利的搜集好资料呢?下一篇要接着讲解如何训练模型并把模型应用到范例上。接着我们会继续介绍更多JetBot相关的范例,有兴趣的人欢迎继续关注我们!