Pytorch深度學習框架X NVIDIA JetsonNano應用-YOLOv5辨識台灣即時路況 (繁體)
关注文章
 戴夫来自 DesignSpark
戴夫来自 DesignSpark
你觉得这篇文章怎么样? 帮助我们为您提供更好的内容。
戴夫来自 DesignSpark
Thank you! Your feedback has been received.
戴夫来自 DesignSpark
There was a problem submitting your feedback, please try again later.
戴夫来自 DesignSpark
你觉得这篇文章怎么样?
|
作者 |
嘉鈞 |
|
難度 |
理論困難,實作普通 |
|
材料表 |
|
前景提要
當時YOLOv4出了沒多久YOLOv5就悄然推出了,但是你可以發現v5其實不是v4的團隊 (Alexey Bochkovskiy, Chien-Yao Wang, Hong-Yuan Mark Liao) 所做,更不是YOLO之父 (Joseph Redmon) 所做,而是一間名為Ultralytics LLC的公司所開發 ( 之前一直有發布關於YOLO轉成PyTorch的Github ),在YOLOv5發布之前也沒發布論文來佐證YOLOv5,很多人對它的存在感到懷疑也鬧出很大的風波。不過它是基於PyTorch實現,架構與YOLOv3、v4的DarkNet環境截然不同,對於再修改跟開發上比較簡單,接著就跟我一起利用Jetson Nano來完成YOLOv5的實作吧!
如果你想了解更多可以看看Ultralytics LLC出面說明YOLOv4與YOLOv5差異-https://blog.roboflow.com/yolov4-versus-yolov5/,而Ultralytics也有推出基於YOLO的APP ( 僅限IOS ),現在也更新到YOLOv5了。

訓練環境
先前都直接用原生的系統來裝套件,有時候不同的專案會需要不同的版本,為了將其獨立開來建議是使用虛擬環境來安裝比較合適。今天會稍微介紹一下虛擬環境的部分,我在Windows上常會使用Anaconda而Jetson Nano上因為Anaconda不支援aarch64 (Arm64) 的核心所以要另外編譯,非常麻煩!所以我直接使用Virtualenv ( 另一個輕便的虛擬環境套件)。
安裝 virtualenv以及virtualenvwrapper:
$ sudo pip3 install virtualenv virtualenvwrapper修改環境變數:
$ nano ~/.bashrc
export WORKON_HOME=$HOME/.virtualenvs
export VIRTUALENVWRAPPER_PYTHON=/usr/bin/python3
export /usr/local/bin/virtualenvwrapper.sh
建置虛擬環境:
$ mkvirtualenv yolov5開啟虛擬環境:
$ workon yolov5可以看到前面會多一個括弧(env_name)就是你目前的環境名稱:
接下來先安裝git,因為要下載YOLOv5:
$ sudo apt-get install git-all -y下載YOLOv5 的Github:
$ git clone https://github.com/ultralytics/yolov5.git接著安裝所需套件,可以先打開requirements.txt來看看所需套件,不管是Raspberry Pi 還是 Jetson系列,安裝PyTorch或OpenCV都有特定的方式或來源,所以我在嘗試別人的Github時都會分別開來安裝。

像是這邊可以看到Cython、Numpy都在安裝PyTorch的時候會一起安裝,而OpenCV因為原生就有所以用Link的方式就可以了,所以我們先來處理比較特別的OpenCV跟PyTorch。
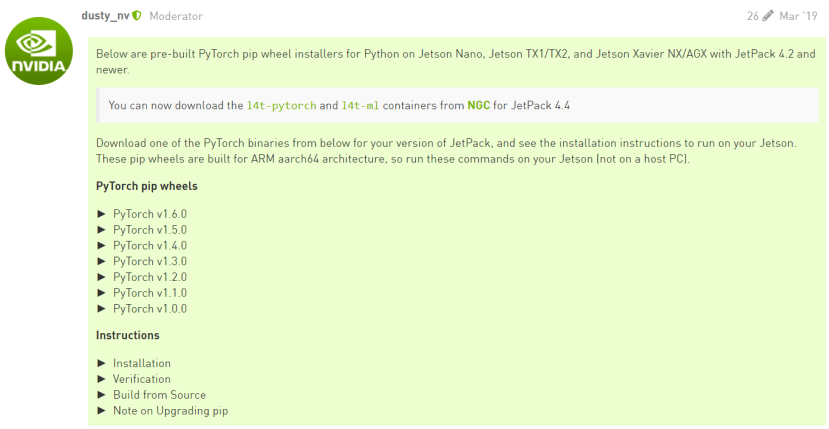
這是官方提供的教學PyTorch for Jetson - version 1.6.0 now available,首先在YOLOv5提出的安裝套件可以看到建議是1.6以上,目前只有JetPack4.4才能支援PyTorch 1.6哦!請特別注意自己的JetPack版本:

安裝PyTorch:
$ wget https://nvidia.box.com/shared/static/9eptse6jyly1ggt9axbja2yrmj6pbarc.whl -O torch-1.6.0-cp36-cp36m-linux_aarch64.whl
$ sudo apt-get install python3-pip libopenblas-base libopenmpi-dev
$ pip3 install Cython
$ pip3 install numpy torch-1.6.0-cp36-cp36m-linux_aarch64.whl
安裝torchvision:
$ sudo apt-get install libjpeg-dev zlib1g-dev
$ git clone --branch v0.7.0 https://github.com/pytorch/vision torchvision
$ cd torchvision
$ export BUILD_VERSION=0.7.0
$ sudo python setup.py install
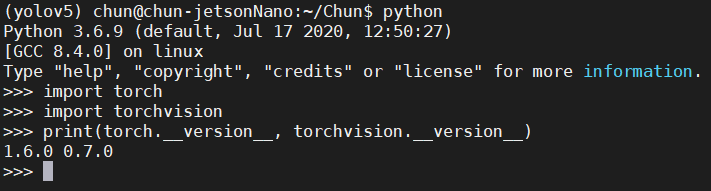
這部分大概10分鐘內能搞定,可以透過導入函式庫查看版本來確認是否安裝成功:
接著要找到原生的OpenCV位置:
$ sudo find / -name cv2
尋找 .so 檔案,大家應該都一樣會在 /usr/lib/python3.6/dist-packages/cv2/python-3.6/ 裡面:

接著就要建立連結,使用ln 指令:
$ ln -s /usr/lib/python3.6/dist-packages/cv2/python-3.6/cv2.cpython-36m-aarch64-linux-gnu.so ~/.virtualenvs/{your env}/cv2.cpython-36m-aarch64-linux-gnu.so
確認是否安裝成功:

剩下還沒安裝的套件整理一下會變成下面
$ pip3 install matplotlib pillow pyyaml tensorboard tqdm scipy其中scipy可能原本就有了,由於它安裝要好一陣子所以我建議如果有先執行看看,不行再安裝。
執行YOLOv5的範例程式
使用Github範例程式 detect.py,範例程式主要會用到的引數
|
--source |
圖片、影片目錄或是 0 開啟攝影機 |
|
--iou_thred |
信心指數的閥值,雖然低一些可框出越多東西但準確度就不敢保證 |
|
--weights |
權重,有s、m、l、x之分 |
我們可以下載訓練好的weights,可以利用作者的download_weight.sh來下載,他需要用到util資料夾的程式所以我有移動到上一層目錄,嫌麻煩的當然也可以直接到他的GoogleDrive下載。
$ cd weights/
$ mv download_weights.sh ..
$ cd ..
$ bash download_weights.sh
接著可以執行detec.py,我們先使用官網提供的範例圖來測試:
$ python detect.py --source inference/images/ --weights weights/yolov5s.pt運行結果如下:

對兩張圖片進行推論,耗費時間為18秒:
 |
 |
 |
 |
還可以接上相機做即時影像偵測:

比較各模型差異
這邊我們拿YOLOv3跟YOLOv5來做比較,可以注意到v3-tiny雖然秒數最少但運行結果不盡理想;然後v5-s目前看起來秒數少,框出來的物品多準確度也蠻高的;v5-l 、v3-spp準確度高但是也會框到一些錯誤的物品。

拿YOLOv5來應用在即時路況影像
對於Jetson 系列的開發版相當多人會拿來做自駕車專案,而YOLO所訓練的coco_2017數據集也能用於偵測人、車,所以我們先直接拿pre-trained model來實際運行看看,第一步是要取得到即時路況影像,這樣類型的影像直接用手機路就太過時了,所以我們來玩點不一樣的,我們可以到到下列這個網站獲取「即時影像監視器」
https://tw.live/這個網站有各式各樣的台灣路況可以查看,而這些都是即時影像。

仔細看了一下西門町的路口監視器畫面比較清晰也人多,所以最後我選擇西門町的即時影像,接下來就要考慮一個大問題了~我該如何將直播影片給下載下來!
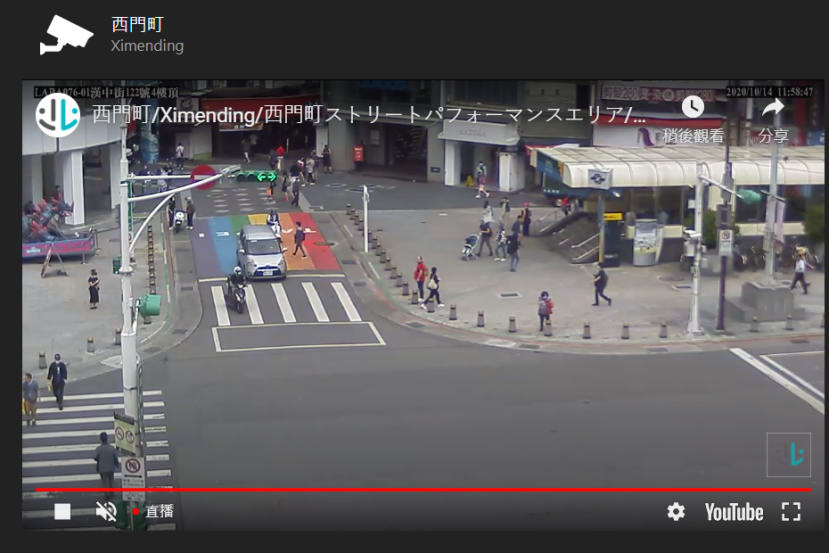
其實你可以發現它從Youtube直播影片連動過來的,所以我寫了這支程式用來擷取Youtube影像直播,主要利用pafy跟vlc來下載mp4影片,並且利用moviepy來剪輯預設秒數,首先先安裝相關套件:
$ pip install pafy youtube-dl python-vlc moviepy因為moviepy跟影片有關要安裝相關的編碼格式,Windows本身就有了但是Linux需要額外安裝,透過pip安裝在虛擬環境中是行不通的,目前安裝在本身的環境:
$ sudo apt install ffmpeg接著就是主要程式的部分:
def capture_video(opt):
f_name = 'org.mp4' # 下載影片名稱
o_name = opt.output # 裁剪影片名稱
sec = opt.second # 欲保留秒數
video = pafy.new(opt.url) # 取得Youtube影片
r_list = video.allstreams # 取得串流來源列表
print_div()
for i,j in enumerate(r_list): print( '[ {} ] {} {}'.format(i,j.title,j))
idx = input('\nChoose the resolution : ')
if idx:
### 選擇串流來源
trg = r_list[int(idx)]
print_div('您選擇的解析度是: %s'%(trg))
### 下載串流
vlcInstance = vlc.Instance()
player = vlcInstance.media_player_new() # 創建一個新的MediaPlayer實例
media = vlcInstance.media_new(trg.url) # 創建一個新的Media實例
media.get_mrl()
media.add_option(f"sout=file/ts:{f_name}") # 將媒體直接儲存
player.set_media(media) # 設置media_player將使用的媒體
player.play() # 播放媒體
time.sleep(1) # 等待資訊跑完
### 進度條、擷取影片
clock(sec) # 播放 sec 秒 同時運行 進度條
cut_video(f_name, sec, o_name) # 裁切影片,因為停n秒長度不一定是n
### 關閉資源
player.stop() # 關閉撥放器以及釋放媒體
其餘副函式,大部分是美觀用,像是用來取得終端機視窗大小以及打印分隔符號等,在clock的部分費了些心思寫了類似tqdm的進度條,最後cut_video就是剪取影片,從第0秒到第n秒:
### 取得terminal視窗大小
def get_cmd_size():
import shutil
col, line = shutil.get_terminal_size()
return col, line
### 打印分隔用
def print_div(text=None):
col,line = get_cmd_size()
col = col-1
if text == None:
print('-'*col)
else:
print('-'*col)
print(text)
print('-'*col)
### 計時、進度條
def clock(sec, sign = '#'):
col, line = get_cmd_size()
col_ = col - 42
bar_bg = ' '*(col_)
print_div()
for i in range(sec+1):
bar_idx = (col_//sec*(i+1))
bar = ''
for t in range(col_): bar += sign if t <= bar_idx else bar_bg[t]
percent = int(100/sec*(i))
end = '\n' if i==sec else '\r'
print('Download Stream Video [{:02}/{:02}s] [{}] ({:02}%)'.format(i, sec, bar, percent), end=end)
time.sleep(1)
### 擷取特定秒數並儲存
def cut_video(name, sec, save_name):
print_div()
print('Cutting Video Used Moviepy\n')
ffmpeg_extract_subclip(name, 0, sec, targetname=save_name)
print_div(f'save file {save_name}')
為了使用更方便,我增加了argparse命令列選項,「-u」為Youtube連結;「-o」為輸出影片名稱;「-s」為輸出影片秒數:
if __name__=='__main__':
parser = argparse.ArgumentParser()
parser.add_argument('-u', '--url', help='youtube url')
parser.add_argument('-o', '--output', type=str, default='sample.mp4' , help='save file path\name')
parser.add_argument('-s', '--second',type=int, default=10 , help='video length')
opt = parser.parse_args()
capture_video(opt)
執行結果:
$ python capture_livestream.py -u 'https://www.youtube.com/watch?v=iVpOdRU0r9s&feature=emb_title&ab_channel=%E8%87%BA%E5%8C%97%E5%B8%82%E6%94%BF%E5%BA%9CTaipeiCityGovernment' -o test.mp4 -s 10
接著可以直接執行範例程式來運行看看:
$ python detect.py --source test.mp4 --weights yolov5s.pt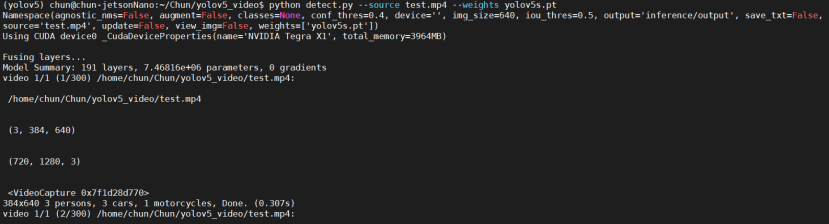
結果如下:

使用Jetson Nano運行平均0.165秒一幀,10秒的影片總共耗費83秒完成,這邊提供運行完的影片給大家參考:
個人覺得這樣的影片無法評估Nano效能是好是壞,所以我修改了一下範例程式將它變成即時影像辨識的方式,程式中稍微計算了FPS大概在5左右,一個順暢的影片FPS至少要在30以上,所以可以看到有些許的卡頓,當然我用遠端也有可能造成更多的Delay:
修改的內容相當簡單,就是將原本要讀取照片或影片的部分擷取出來,改成只有照片,並且在一開始讀檔的方式改成用OpenCV讀取影像,最終修改後的程式如下:
import argparse
import os
import platform
import shutil
import time
from pathlib import Path
import numpy as np
import cv2
import torch
import torch.backends.cudnn as cudnn
from numpy import random
from models.experimental import attempt_load
from utils.datasets import LoadStreams, LoadImages
from utils.general import (
check_img_size, non_max_suppression, apply_classifier, scale_coords,
xyxy2xywh, plot_one_box, strip_optimizer, set_logging)
from utils.torch_utils import select_device, load_classifier, time_synchronized
# Image process
###############################################################################
def img_preprocess(img0, img_size=640):
# Padded resize
img = letterbox(img0, new_shape=img_size)[0]
# Convert
img = img[:, :, ::-1].transpose(2, 0, 1) # BGR to RGB, to 3x416x416
img = np.ascontiguousarray(img)
# cv2.imwrite(path + '.letterbox.jpg', 255 * img.transpose((1, 2, 0))[:, :, ::-1]) # save letterbox image
return img, img0
# Get target size
###############################################################################
def letterbox(img, new_shape=(640, 640), color=(114, 114, 114), auto=True, scaleFill=False, scaleup=True):
# Resize image to a 32-pixel-multiple rectangle https://github.com/ultralytics/yolov3/issues/232
shape = img.shape[:2] # current shape [height, width]
if isinstance(new_shape, int):
new_shape = (new_shape, new_shape)
# Scale ratio (new / old)
r = min(new_shape[0] / shape[0], new_shape[1] / shape[1])
if not scaleup: # only scale down, do not scale up (for better test mAP)
r = min(r, 1.0)
# Compute padding
ratio = r, r # width, height ratios
new_unpad = int(round(shape[1] * r)), int(round(shape[0] * r))
dw, dh = new_shape[1] - new_unpad[0], new_shape[0] - new_unpad[1] # wh padding
if auto: # minimum rectangle
dw, dh = np.mod(dw, 64), np.mod(dh, 64) # wh padding
elif scaleFill: # stretch
dw, dh = 0.0, 0.0
new_unpad = (new_shape[1], new_shape[0])
ratio = new_shape[1] / shape[1], new_shape[0] / shape[0] # width, height ratios
dw /= 2 # divide padding into 2 sides
dh /= 2
if shape[::-1] != new_unpad: # resize
img = cv2.resize(img, new_unpad, interpolation=cv2.INTER_LINEAR)
top, bottom = int(round(dh - 0.1)), int(round(dh + 0.1))
left, right = int(round(dw - 0.1)), int(round(dw + 0.1))
img = cv2.copyMakeBorder(img, top, bottom, left, right, cv2.BORDER_CONSTANT, value=color) # add border
return img, ratio, (dw, dh)
def print_div(text):
print(text, '\n')
print('='*40,'\n')
# Detect func
###############################################################################
def detect(save_img=False):
print_div('INTIL')
out, source, weights, view_img, save_txt, imgsz = \
opt.output, opt.source, opt.weights, opt.view_img, opt.save_txt, opt.img_size
# Initialize
print_div('GET DEVICE')
set_logging()
device = select_device(opt.device)
half = device.type != 'cpu' # half precision only supported on CUDA
# Load model
print_div('LOAD MODEL')
model = attempt_load(weights, map_location=device) # load FP32 model
imgsz = check_img_size(imgsz, s=model.stride.max()) # check img_size
if half:
model.half() # to FP16
# Second-stage classifier
print_div('LOAD MODEL_CLASSIFIER')
classify = False
if classify:
modelc = load_classifier(name='resnet101', n=2) # initialize
modelc.load_state_dict(torch.load('weights/resnet101.pt', map_location=device)['model']) # load weights
modelc.to(device).eval()
# Get names and colors
print_div('SET LABEL COLOR')
names = model.module.names if hasattr(model, 'module') else model.names
colors = [[random.randint(0, 255) for _ in range(3)] for _ in range(len(names))]
# Run inference
###############################################################################
print_div("RUN INFERENCE")
img = torch.zeros((1, 3, imgsz, imgsz), device=device) # init img
_ = model(img.half() if half else img) if device.type != 'cpu' else None # run once
video_path = source
cap = cv2.VideoCapture(video_path)
print_div('Start Play VIDEO')
while cap.isOpened():
ret, frame = cap.read()
t0 = time.time()
if not ret:
print_div('No Frame')
break
fps_t1 = time.time()
img, img0 = img_preprocess(frame) # img: Resize , img0:Orginal
img = torch.from_numpy(img).to(device)
img = img.half() if half else img.float() # uint8 to fp16/32
img /= 255.0 # 0 - 255 to 0.0 - 1.0
if img.ndimension() == 3:
img = img.unsqueeze(0)
# Inference
t1 = time_synchronized()
pred = model(img, augment=opt.augment)[0]
# Apply NMS : 取得每項預測的數值
pred = non_max_suppression(pred, opt.conf_thres, opt.iou_thres, classes=opt.classes, agnostic=opt.agnostic_nms)
t2 = time_synchronized()
# Apply Classifier : 取得該數值的LAbel
if classify:
pred = apply_classifier(pred, modelc, img, img0)
# Draw Box
for i, det in enumerate(pred):
s = '%gx%g ' % img.shape[2:] # print string
gn = torch.tensor(img0.shape)[[1, 0, 1, 0]] # normalization gain whwh
if det is not None and len(det):
# Rescale boxes from img_size to im0 size
det[:, :4] = scale_coords(img.shape[2:], det[:, :4], img0.shape).round()
# Print results
for c in det[:, -1].unique():
n = (det[:, -1] == c).sum() # detections per class
s += '%g %ss, ' % (n, names[int(c)]) # add to string
# Write results
for *xyxy, conf, cls in reversed(det):
label = '%s %.2f' % (names[int(cls)], conf)
plot_one_box(xyxy, img0, label=label, color=colors[int(cls)], line_thickness=3)
# Print Results(inference + NMS)
print_div('%sDone. (%.3fs)' % (s, t2 - t1))
# Draw Image
x, y, w, h = (img0.shape[1]//4), 25, (img0.shape[1]//2), 30
cv2.rectangle(img0, (x, 10),(x+w, y+h), (0,0,0), -1)
rescale = 0.5
re_img0 = (int(img0.shape[1]*rescale) ,int(img0.shape[0]*rescale))
cv2.putText(img0, '{} | inference: {:.4f}s | fps: {:.4f}'.format(opt.weights[0], t2-t1, 1/(time.time()-t0)),(x+20, y+20),cv2.FONT_HERSHEY_SIMPLEX,1,(0,0,255),2)
cv2.imshow('Stream_Detected', cv2.resize(img0, re_img0) )
key = cv2.waitKey(1)
if key == ord('q'): break
# After break
cap.release()
cv2.destroyAllWindows()
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--weights', nargs='+', type=str, default='yolov5s.pt', help='model.pt path(s)')
parser.add_argument('--source', type=str, default='inference/images', help='source') # file/folder, 0 for webcam
parser.add_argument('--output', type=str, default='inference/output', help='output folder') # output folder
parser.add_argument('--img-size', type=int, default=640, help='inference size (pixels)')
parser.add_argument('--conf-thres', type=float, default=0.4, help='object confidence threshold')
parser.add_argument('--iou-thres', type=float, default=0.5, help='IOU threshold for NMS')
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--view-img', action='store_true', help='display results')
parser.add_argument('--save-txt', action='store_true', help='save results to *.txt')
parser.add_argument('--classes', nargs='+', type=int, help='filter by class: --class 0, or --class 0 2 3')
parser.add_argument('--agnostic-nms', action='store_true', help='class-agnostic NMS')
parser.add_argument('--augment', action='store_true', help='augmented inference')
parser.add_argument('--update', action='store_true', help='update all models')
opt = parser.parse_args()
print(opt)
with torch.no_grad():
if opt.update: # update all models (to fix SourceChangeWarning)
for opt.weights in ['yolov5s.pt', 'yolov5m.pt', 'yolov5l.pt', 'yolov5x.pt']:
detect()
strip_optimizer(opt.weights)
else:
detect()
結語
YOLOv5縱使不是正統、最快的YOLO但是基於PyTorch實做的YOLO讓我們修改更加的方便,以往在DarkNet上運行現在只要裝好PyTorch基本就可以執行,檔案大小也差非常多,邊緣裝置的負擔也不會太大!大家可以去體驗看看YOLOv5的方便性、輕便性,下一篇文章中我會教大家如何使用YOLOv5來訓練自己的數據!
相關文章
在Jetson Nano (TX1/TX2)上使用Anaconda与PyTorch 1.1.0
https://zhuanlan.zhihu.com/p/64868319
YOLOv5 github
评论