NVIDIA Jetson Nano應用-運行OpenCV的Face Detection – 上篇
关注文章
 戴夫来自 DesignSpark
戴夫来自 DesignSpark
你觉得这篇文章怎么样? 帮助我们为您提供更好的内容。
戴夫来自 DesignSpark
Thank you! Your feedback has been received.
戴夫来自 DesignSpark
There was a problem submitting your feedback, please try again later.
戴夫来自 DesignSpark
你觉得这篇文章怎么样?
|
作者 |
張嘉鈞 |
|
難度 |
普通 |
|
材料表 |
Webcam X1 NVIDIA JetsonNano X1 |
所需設備與系統
我們使用的設備是Jetson Nano A02,系統為官方的 JetPack 4.4.1系統。
事前準備 ( 重新安裝OpenCV )
開始之前請先幫我安裝這個好用的第三方工具jetson_stats,可以監測Jetson 系列的設備使用狀況,安裝方法如下:
$ sudo -H pip install -U jetson-stats
$ sudo reboot
重開機過後可以先執行jtop來看是否能成功運行!其中 jtop可以監控即時的狀況、jetson_swap可以開啟swap空間、jetson_release可以查看Jetson Nano系統以及常用工具的版本等等:
$ jtop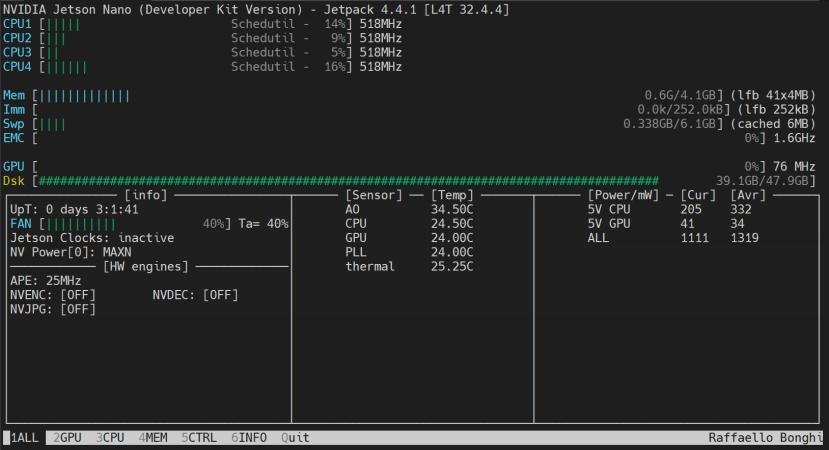
這次的內容主要是運行OpenCV,Jetson系列的Tegra系統已經支援OpenCV 4.4.1,不過我們這次會使用到OpenCV的深度學習模組(DNN) 需要使用到CUDA,然而Tegra預設的OpenCV是沒辦法使用CUDA的,我們可以透過jetson_release來查看OpenCV的版本以及是否能使用CUDA ( compiled CUDA):
$ jetson_release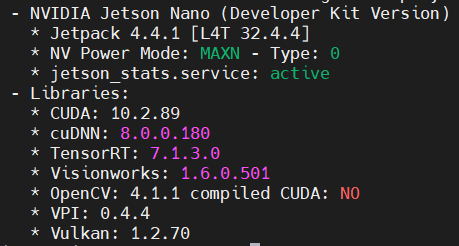
可以注意到 compiled CUDA的選項是 NO,所以我們需要耗費一點時間來重建OpenCV。
1、將 gdm3調整成 lightdm ( 可選 )
Gdm3就是常見的ubuntu介面,可以透過下列指令調整成lightdm介面,這是一個輕量化的圖形化介面:
$ sudo dpkg-reconfigure gdm3
透過jtop指令可以查看兩個介面的記憶體使用狀況,在MEM的欄位可以發現原本gdm3使用了大概1.1G左右的容量,轉成lightdm之後變成了0.7G左右:
$ jtop
2、給Jetson Nano更多swap空間
原本的swap空間僅有2GB,但我們可以透過jetson_swap來開啟swap空間:
$ sudo jetson_swap -d ~ -s 4 -a
3.檢查CUDA
原廠系統已經安裝好CUDA了,不過有時候還是會發生抓不到CUDA的問題,我們可以透過nvcc來檢查:
$ nvcc -V
如果找不到則需要手動新增到環境變數當中:
$ nano ~/.bashrc開啟 bashrc後新增下列指令:
export CUDA_HOME=/usr/local/cuda-10.0/
export LD_LIBRARY_PATH=/usr/local/cuda-10.0/lib64:$LD_LIBRARY_PATH
export PATH=${CUDA_HOME}bin:$PATH
存檔離開並且再執行”nvcc -V”,確認是否成功。
4、安裝相依套件
大部分的套件在安裝Jetson系列的原廠系統後都已經打包在裡面了,不過這邊還是全部都列出來以防萬一:
# reveal the CUDA location
$ sudo sh -c "echo '/usr/local/cuda/lib64' >> /etc/ld.so.conf.d/nvidia-tegra.conf" -y
$ sudo ldconfig -y
# third-party libraries
$ sudo apt-get install build-essential cmake git unzip pkg-config -y
$ sudo apt-get install libjpeg-dev libpng-dev libtiff-dev -y
$ sudo apt-get install libavcodec-dev libavformat-dev libswscale-dev -y
$ sudo apt-get install libgtk2.0-dev libcanberra-gtk* -y
$ sudo apt-get install python3-dev python3-numpy python3-pip -y
$ sudo apt-get install libxvidcore-dev libx264-dev libgtk-3-dev -y
$ sudo apt-get install libtbb2 libtbb-dev libdc1394-22-dev -y
$ sudo apt-get install gstreamer1.0-tools libv4l-dev v4l-utils -y
$ sudo apt-get install libgstreamer1.0-dev libgstreamer-plugins-base1.0-dev -y
$ sudo apt-get install libavresample-dev libvorbis-dev libxine2-dev -y
$ sudo apt-get install libfaac-dev libmp3lame-dev libtheora-dev -y
$ sudo apt-get install libopencore-amrnb-dev libopencore-amrwb-dev -y
$ sudo apt-get install libopenblas-dev libatlas-base-dev libblas-dev -y
$ sudo apt-get install liblapack-dev libeigen3-dev gfortran -y
$ sudo apt-get install libhdf5-dev protobuf-compiler -y
$ sudo apt-get install libprotobuf-dev libgoogle-glog-dev libgflags-dev -y
5、從來源建置OpenCV
我們可以到OpenCV Release當中去找想要的版本,可以從下圖看到4.5.2跟3.4.14是OpenCV官網所推薦的,那我們就直接嘗試安裝最新的版本看看,因為最新版的DNN模組(深度學習)支援了更多元的神經網路層。

a、移動到家目錄並下載OpenCV來源包病解壓縮:
$ cd ~
$ wget -O opencv.zip https://github.com/opencv/opencv/archive/4.5.2.zip
$ wget -O opencv_contrib.zip https://github.com/opencv/opencv_contrib/archive/4.5.2.zip
$ unzip opencv.zip && unzip opencv_contrib.zip
b、改目錄名稱並刪除壓縮檔:
$ mv opencv-4.5.2 opencv
$ mv opencv_contrib-4.5.2 opencv_contrib
# clean up the zip files
$ rm opencv.zip && rm opencv_contrib.zip
C、建立一個資料夾存放所有建構完的函式庫:
$ cd ~/opencv
$ mkdir build && cd build
d、產生CMake配置檔案,-D將給予特定參數,這些參數將會宣告OpenCV建構的位置、方法等等的:
$ cmake -D CMAKE_BUILD_TYPE=RELEASE \
-D CMAKE_INSTALL_PREFIX=/usr \
-D OPENCV_EXTRA_MODULES_PATH=~/opencv_contrib/modules \
-D EIGEN_INCLUDE_PATH=/usr/include/eigen3 \
-D WITH_OPENCL=OFF \
-D WITH_CUDA=ON \
-D CUDA_ARCH_BIN=5.3 \
-D CUDA_ARCH_PTX="" \
-D WITH_CUDNN=ON \
-D WITH_CUBLAS=ON \
-D ENABLE_FAST_MATH=ON \
-D CUDA_FAST_MATH=ON \
-D OPENCV_DNN_CUDA=ON \
-D ENABLE_NEON=ON \
-D WITH_QT=OFF \
-D WITH_OPENMP=ON \
-D WITH_OPENGL=ON \
-D BUILD_TIFF=ON \
-D WITH_FFMPEG=ON \
-D WITH_GSTREAMER=ON \
-D WITH_TBB=ON \
-D BUILD_TBB=ON \
-D BUILD_TESTS=OFF \
-D WITH_EIGEN=ON \
-D WITH_V4L=ON \
-D WITH_LIBV4L=ON \
-D OPENCV_ENABLE_NONFREE=ON \
-D INSTALL_C_EXAMPLES=OFF \
-D INSTALL_PYTHON_EXAMPLES=OFF \
-D BUILD_opencv_python3=TRUE \
-D OPENCV_GENERATE_PKGCONFIG=ON \
-D BUILD_EXAMPLES=OFF ..
執行成功你將會看到與我類似的畫面。
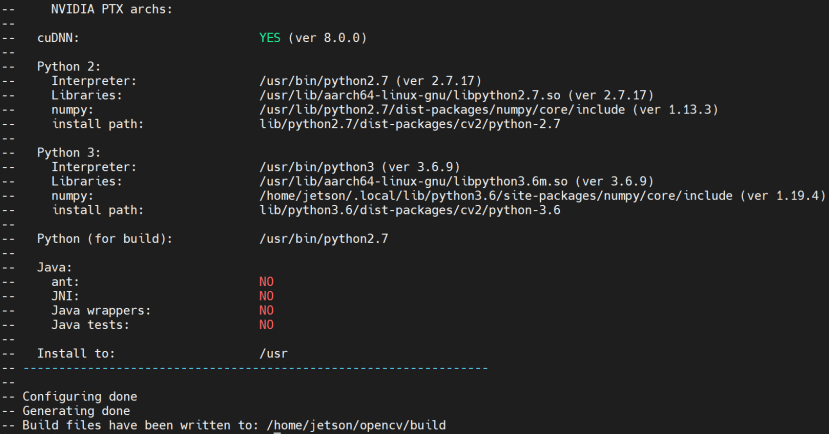
e、進行建構,這邊可以透過 -j 設定要用幾個核心運行 make:
$ make -j4
f、刪除舊有的OpenCV:
$ sudo rm -r /usr/include/opencv4/opencv2
$ sudo make install
$ sudo ldconfig
# cleaning (frees 300 MB)
$ make clean
$ sudo apt-get update
g、清除OpenCV 來源包:
$ sudo rm -rf ~/opencv
$ sudo rm -rf ~/opencv_contrib
h、檢查OpenCV
透過jetson_release 可以注意到 complied CUDA的選項已經變成 YES了:
$ jetson_release
接著可以使用python3導入OpenCV看看:
$ python3 -c "import cv2;print(cv2.__version__)"
7、撰寫一個簡單的測試程式
快速地來寫一個即時影像顯示的程式來檢驗OpenCV是否能成功運行吧!
a、新建python檔案並進行編輯:
$ cd ~
$ nano cv_test.py
b、複製貼上下列程式:
import cv2
cap = cv2.VideoCapture(0) # USB CAMERA INDEX: 0
while(True):
ret, frame = cap.read() # GET FRAME
cv2.imshow("cv real-time capture", frame) # SHOW FRAME
if cv2.waitKey(1)==ord('q'): # PRESS q TO EXIT
break
cv2.destroyAllWindows()
cap.release()
c、執行程式:
$ python3 cv_test.pyOpenCV的人臉辨識
OpenCV的人臉辨識有兩種方法,在3.X版本以前經常會使用Cascade Classifier,但後面開始都比較推薦使用Deep Learning來解決,OpenCV現在也都整合了各大AI框架,像是常見的TensorFlow、PyTorch、Caffe等甚至YOLO也有支援了,但看程式還是支援TensorFlow、Caffe比較多,接下來我們就來執行看看舊版常用的物件偵測Cascade Classifier以及後來追上的DNN的吧!
執行範例程式 ( Quick Reference )
我們先來快速執行一下範例程式,我們將在下一篇針對兩者進行較詳細的介紹
Cascade Classifier 辨識人臉
要執行Cascade Classifier的程式可以到剛剛重新建構OpenCV的資料夾當中尋找,執行 ~/opencv/samples/python/facedetect.py即可進行即時的人臉辨識,在原廠提供的cascade classifier模型有很多種選項可以選擇,預設的是haarcascade_frontalface_alt.xml以及haarcascade_eye.xml。

我們來執行看看範例吧:
$ cd ~/opencv/samples/python/
$ python3 facedetect.py

透過DNN模組辨識人臉
如果想要嘗試使用Deep Neural Network ( 深度神經網路 ) 的方式可以至~/opencv/samples/dnn/ 找到相關的程式,
1、下載模型
首先要先下載模型,需要透過download_models.py來下載模型,我很認真的研究了一下到底要輸入那些參數才能正確下載,後來發現只要輸入錯誤的模型名稱就會提示了:
$ python3 download_models.py test
下載人臉辨識模型 opencv_fd至face_detector資料夾當中:
$ python3 download_models.py --save_dir face_detector/ opencv_fd
2、找到對應配置檔
而這些模型使用的時候需要搭配對應的配置檔案使用但是我們這次要運行的opencv_fd的配置檔已經在face_detector資料夾當中,比較需要注意的地方是不同的框架模型對應到不同的配置檔,其中Caffe的版本有兩個版本可以選擇:
|
Caffe |
TensorFlow |
|
|
Model |
opencv_face_detector.caffemodel res10_300x300_ssd_iter_140000_fp16.caffemodel |
opencv_face_detector_uint8.pb |
|
Config |
deploy.prototxt |
opencv_face_detector.pbtxt |
3、執行人臉辨識程式
由於人臉辨識是透過物件偵測的程式來執行,所以我們執行的程式為object_detection.py,需要給予model跟config的位置:
$ python3 object_detection.py --model face_detector/opencv_face_detector_uint8.pb --config face_detector/opencv_face_detector.pbtxt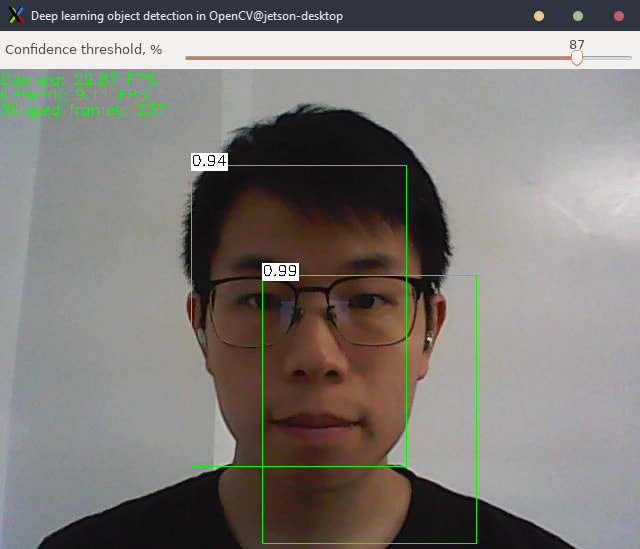
OpenCV預設的模型是Caffe的:
$ python3 object_detection.py --model face_detector/ face_detector/opencv_face_detector.caffemodel --config face_detector/deploy.prototxtOpenCV還提供了另外一個Caffe 模型:
$ python3 object_detection.py --model face_detector/res10_300x300_ssd_iter_140000_fp16.caffemodel --config face_detector/deploy.prototxt可以發現其實三種的模型的效能差不多,以FPS的角度來看由快到慢分別是opencv_face_detector.caffemodel、opencv_face_detector_uint8.pb、res10_300x300_ssd_iter_140000_fp16.caffemodel,其中fp16數據精度最大所以最慢,少了0.06左右的FPS,不過準確度可以發現類似的畫面他辨識度最高。
結論
恭喜各位完成OpenCV重新安裝並且嘗試執行過Open

CV的人臉辨識範例,接著我們將會更深入探討一些基本原理以及API的使用。
相关文章
In OpenCV 4.x, please don't use the HAAR cascade detector to detect faces! There are better and more accurate methods
Python 使用 OpenCV、Dlib 實作即時人臉偵測程式教學