NVIDIA線上課程:深度影像串流-DeepStream實作解說,使用網路影像串流進行深度學習辨識
关注文章
 戴夫来自 DesignSpark
戴夫来自 DesignSpark
你觉得这篇文章怎么样? 帮助我们为您提供更好的内容。
戴夫来自 DesignSpark
Thank you! Your feedback has been received.
戴夫来自 DesignSpark
There was a problem submitting your feedback, please try again later.
戴夫来自 DesignSpark
你觉得这篇文章怎么样?
Deep Stream
在過去的專案中,我們常常在使用網路攝影機或一般的USB攝影機來做影像辨識,自己在建構模型或開發專案的時候是否有更強大以及更簡單的開發工具?NVIDIA都知道大家的困難,所以它整合了一套工具叫做「DeepStream」,透過AI來分析串流媒體的資訊,讓使用者可以更清楚環境資訊,文中有提到像是城市街道上的交通跟行人;醫院病人的安全跟健康;工廠中機器加工的狀態,這些都可以透過DeepStream這套工具來開發。
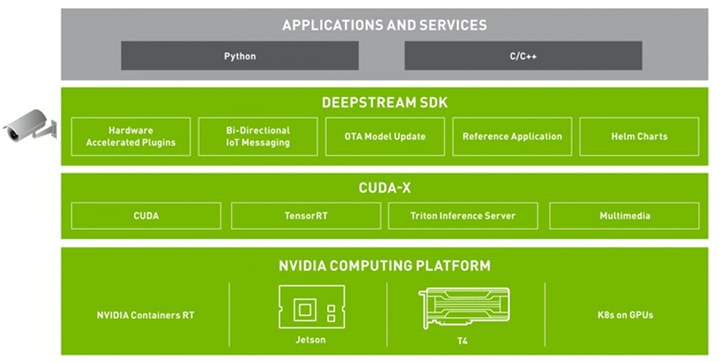
DeepStream開發上較常見是Python但是底層是由C/C++所建構而成,他們為了讓使用者更容易入門,也提供了許多能夠參考的應用,可以到該github去看看https://github.com/NVIDIA-AI-IOT/deepstream_python_apps。
在DeepStream中比較特別的部分除了提供安全的認證機制之外還有就是導入了TensorRT,目的是為了讓資料量減少,這個部份我們將會在特別寫一篇相關的技術給大家。接下來是DeepStream的架構圖:

從這張圖就可以看出整個運作的流程,從攝影機端獲得了影像之後先進行編碼跟基本的影像前處理,進行批次處理以及深度神經網路的inference,VIZ是視覺化的意思,神經網路模型運算結束後可能會有BoundingBox、Segmentation、Label需要顯示在影像上面,最後輸出的時候有提供各種儲存方法,像是繼續使用RTSP輸出或是儲存到電腦等等的。
至於分隔線以下的表示用到的工具以及技術,接下來稍微介紹一下各插件的功能,這個對於想取得DeepStream學習證明的人非常有幫助:
- 編碼:使用的插件為Gst-nvvideo4linux2,技術名稱叫做NVDEC
- 圖像前處理:Gst-nvdewarper用於改善魚眼鏡頭或全景相機;Gst-nvvideoconvert負責顏色格式轉換,以上用的硬體是GPU、VIC ( vision image compositor )。
- 批次處理:Gst-nvstreammux,讓DeepStream能獲得最佳推理。
- 在DNN的部分,提供了兩種進行Inference的方法,第一種是在本地端進行TensorRT的Inference,使用的方法是GST-nvinfer;第二種是在NVIDIA提供的雲端推論平台Triton,而用這個Triton技術的話是GST-nvinferserver。
- 推論完可能還會牽扯到是否追蹤物件來進行第二次的圖片分類,而這邊有提供Gst-nvtracker來處理這塊,從高效能到高精度都可以做選擇。
- 接著是可視化工具Gst-nvdsosd。
- 最後輸出的時候,Gst-nvmsgconv是為了將數據上傳到雲端上,需要做點格式轉換來減輕負載,Gst-nvmsgbroker則是為了建立跟雲端的連結。

上方的圖是一個針對inference流程做解釋,在批次處理到第二段的分類器這些都是屬於神經網路的範疇,這裡強調的是可以不只是做一次物件辨識,還可以透過tracker以及Secondary Classifier來進行N次辨識,最後輸出一樣可以放在EDGE端跟CLOUD端。
使用JetsonNano運作DeepStream範例
深刻了解DeepStream之後我們就可以開始進行實作了,以下實作內容大部分與NVIDIA課程內容相同,並且我們使用Jetson Nano 4G版本來運作。
準備Jetson Nano
下載DLI的映像檔:https://developer.download.nvidia.com/training/nano/dsnano_v1-0-0_20GB_200131A.zip,並且透過Etcher燒錄安裝並且遠端連線,可以參考此篇文章 (https://blog.cavedu.com/2019/04/03/jetson-nano-installsystem/ ),燒錄後Linux系統預設帳號密碼為「dlinano」,接著可以將MicroUSB接到您的電腦。
連線至Jupyter Lab
NVIDIA提供的DLI映像檔已經幫我們安裝好Jupyter Lab的功能,我們可以透過內網或外網遠端連線至Jetson Nano,只要取得虛擬IP的位址,如果是透過MicroUSB連接統一都是192.168.55.1,而透過WIFI遠端就會不太一樣,像我的裝置是192.168.12.152,要注意不論是哪一個IP位置都要加上埠號8888,使用方法是在IP的後方加上冒號與連接埠號,這樣才能連動到Jupyter Lab。

輸入帳號密碼後的畫面如下,我們要使用的程式碼會放在 ~/Notebooks資料夾中:
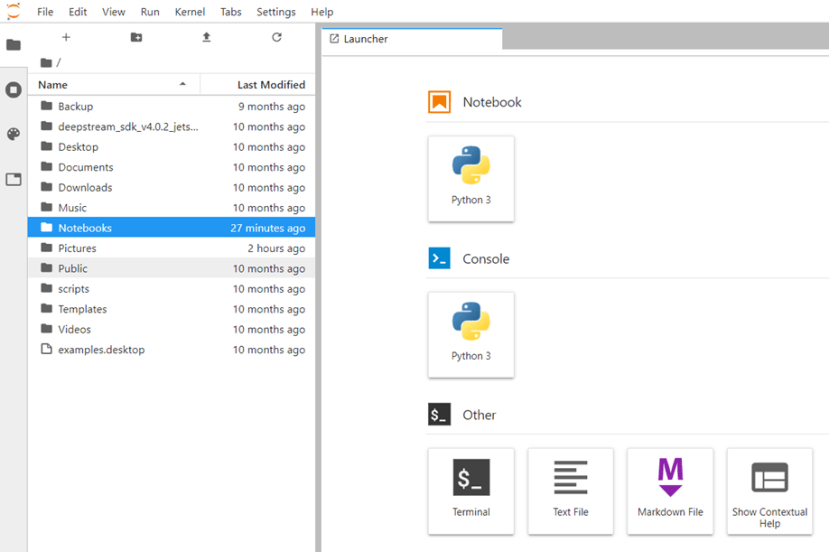
進入該資料夾後會看到NVIDIA提供的六個範例,
第一個是能夠偵測串流影像中的物件 ( 人、車等等 );
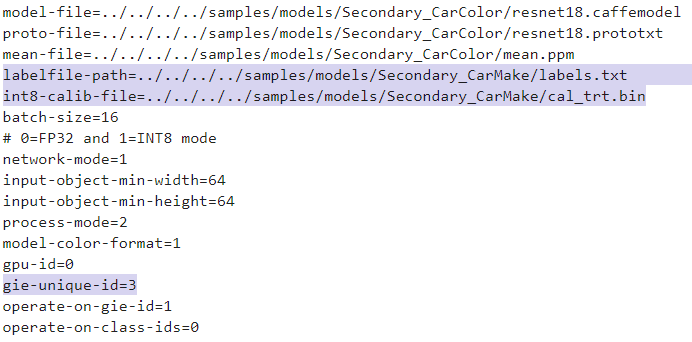
第二個是透過多個網路對串流影像進行辨識,除了能夠辨識物件之外還能得到車子的品牌/顏色等資訊;
第三個是多個串流影像的做法;
第四個則是輸出成影片,包含Bounding Box;
第五個則是透過Webcam來做即時影像辨識。

安裝 & 使用 VLC
VLC是一個常見的媒體撥放器,而在Windows端下載VLC目的是要連動到JetsonNano的影像畫面,因為JupyterLab無法開啟JetsonNano的視窗所以影像相關需要透過網路傳到VLC上,安裝方法可以直接上官方網站進行下載安裝。
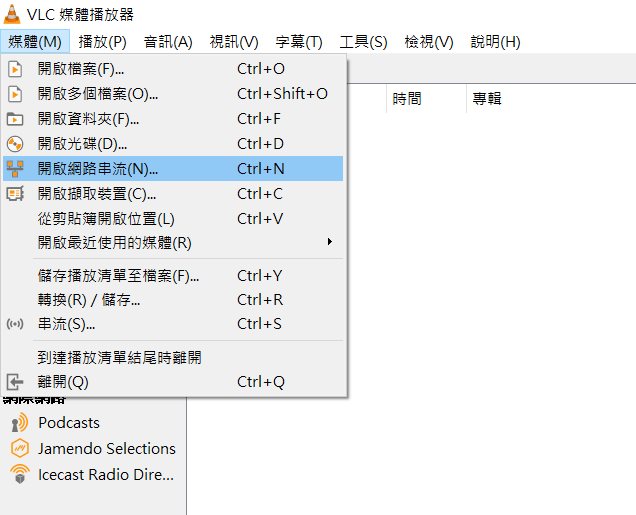
開啟VLC之後,在媒體的選項中可以開啟網路串流,開啟後需要輸入{IP_Adress}:8554/ds-test,接下來就只要執行程式即可看到輸出的畫面:
01_ObjDetection.ipynb
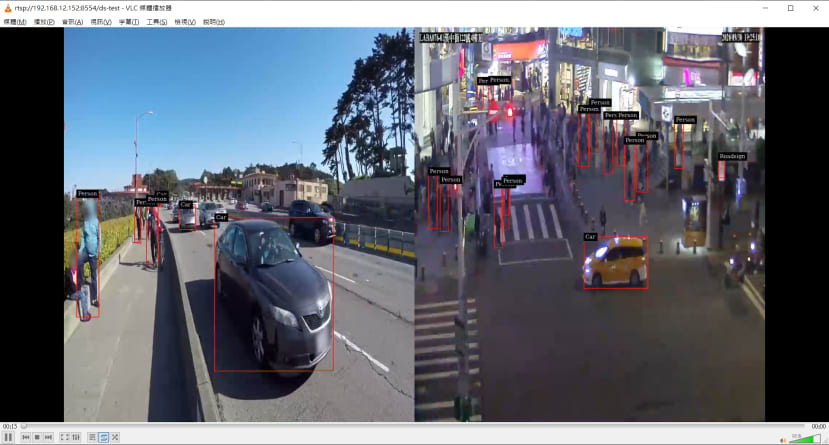
這個範例是透過Nvidia提供的模型嘗試在串流影像中進行即時的物件偵測,它能辨識的物件總共有四種1. Vehicles 2. Bicycles 3. Persons 4. Roadsigns。
實行程式的方法很簡單,只需make它提供的資料夾,並且執行欲串流的影片即可,這邊要注意的是它只吃h264的編碼格式,如果是.mp4還需轉成.264才行,這裡讓我困惑的點是我當初也是透過h264的編碼格式輸出成mp4,結果它也是不能吃…可能是兩種副檔名提供的某些資訊不太相同~下圖為我執行西門町路況影像的結果:

在實作的部分,官方提供了兩個練習給大家操作,第一個是更改Bounding Box的項目,原本四個種類都會被標註,現在它希望更改成只標註腳踏車、汽車,而你只需要更動dstest1_pgie_config.txt的部分,將其改成對應標籤數字,對於不必要出現的項目只要將threshold更改為1即可。
|
[class-attrs-all] threshold=0.2 eps=0.2 group-threshold=1 |
[class-attrs-1] threshold=0.2 eps=0.2 … |
 |
 |
第二個實作則是改變影像上面的標籤顯示,在左上方可以看到有顯示計算的數值,這部分的話就要去修改deepstream_test1_app.c的檔案,過程比較繁雜一點。
1.定義巨集,可以想像就是給予一個變數定值

2.新增變數

3.新增判斷並且增加上述變數的數值
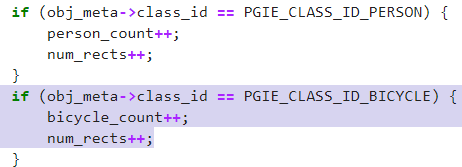
4.改變顯示的內容
5.執行結果
 |
 |
02_MultipleNetworks.ipynb

它會在偵測到物件之後進行裁切接著在透過別的模型來進行更進一步的分類,相當有趣的一個範例,流程相當容易理解,進行第一次的物件辨識之後會透過tracker將該物件擷取出來進行第二次、第三次等地輔助辨識。

下圖為運行的結果:

稍微學會怎麼去更改這個程式吧!主要分為四個階段:
1.Define


2.Instantiate



3.bin/link


4.Configure
5.執行結果

6.還有第三個範例是「車子的種類」,讀者們可以自己去嘗試看看。
03_MultiStream.ipynb
04_VideoFileOutput.ipynb
檔案輸出的部分就不多說了,整體操作很簡單,主要在探討如何輸出、輸出的畫面調整、輸出的檔案格式。
05_DiffNetworks.ipynb
它除了內建的模型之外還提供了fasterRCNN、SSD、YOLO的模型,使用之前需要先進行下載,每個資料夾/ deepstream_sdk_v4.0.2_jetson/sources/objectDetector/ 中都有ReadMe可以查看。

06_DSWebcam.ipynb
當然最基本的開啟攝影機也不會少,透過USB外接網路攝影機並且執行該程式便可以進行即時的影像辨識,在下面影片中卡頓較嚴重的原因除了本身inference的延遲之外也有可能是因為網路延遲所導致,這邊大家就參考看看,實際速度還是因人而異,那這個部分當然也可以使用其他模型來運作。
結語
整體而言對於DeepStream提供的一些功能還是相當強大的,因為在串流影像的部分你不只需要注意AI模型的好壞,你還需要注意相當多的資料傳輸與網路問題,NVIDIA將這塊做好之後開發者當然就少去相當多的煩惱了,剩下的就是如何熟悉跟習慣這些工具的用法,下一篇我將會帶大家認識TensorRT,以及又該如何去使用它。