NVIDIA CUDA核心GPU实做:Jetson Nano 运用TensorRT加速引擎 – 下篇
关注文章
 戴夫来自 DesignSpark
戴夫来自 DesignSpark
你觉得这篇文章怎么样? 帮助我们为您提供更好的内容。
戴夫来自 DesignSpark
Thank you! Your feedback has been received.
戴夫来自 DesignSpark
There was a problem submitting your feedback, please try again later.
戴夫来自 DesignSpark
你觉得这篇文章怎么样?
使用TensorRT运行ONNX
要来运行TensorRT了,来复习一下TensorRT的流程:
- ONNX parser:将模型转换成ONNX的模型格式。
- Builder:将模型导入TensorRT并且建构TensorRT的引擎。
- Engine:引擎会接收输入值并且进行Inference跟输出。
- Logger:负责记录用的,会接收各种引擎在Inference时的讯息。
第一个我们已经完成了,接下来的部分要建构TensorRT引擎,这个部分可以参考于NVIDIA的官网文件,主要程序如下,总共三个副函式build_engine、save_engine、load_engine,就如字面上的意思一样是建置、储存、载入,而log函式库是我自己写的用来显示状态以及计时:
import tensorrt as trt
from log import timer, logger
TRT_LOGGER = trt.Logger(trt.Logger.WARNING)
trt_runtime = trt.Runtime(TRT_LOGGER)
if __name__ == "__main__":
onnx_path = 'alexnet.onnx'
trt_path = 'alexnet.trt'
input_shape = [1, 224, 224, 3]
build_trt = timer('Parser ONNX & Build TensorRT Engine')
engine = build_engine(onnx_path, input_shape)
build_trt.end()
save_trt = timer('Save TensorRT Engine')
save_engine(engine, trt_path)
save_trt.end()
build_engine的程序代码,max_workspace是指GPU的使用暂存最大可到多少,因为TensorRT可以支持到Float Point 16,这次模式选择fp16,在建构引擎之前需要先解析 (Parser) ONNX模型,接着再使用build_cuda_engine来建构:
def build_engine(onnx_path, shape = [1,224,224,3]):
with trt.Builder(TRT_LOGGER) as builder, builder.create_network(1) as network, trt.OnnxParser(network, TRT_LOGGER) as parser:
builder.max_workspace_size = (256 << 20) # 256MiB
builder.fp16_mode = True # fp32_mode -> False
with open(onnx_path, 'rb') as model:
parser.parse(model.read())
engine = builder.build_cuda_engine(network)
return engine
save_engine的程序代码,储存的时候需要将引擎给串行化以供储存以及加载:
def save_engine(engine, engine_path):
buf = engine.serialize()
with open(engine_path, 'wb') as f:
f.write(buf)
load_engine的程序代码,主要在于要反串行化获得可运行的模型架构:
def load_engine(trt_runtime, engine_path):
with open(engine_path, 'rb') as f:
engine_data = f.read()
engine = trt_runtime.deserialize_cuda_engine(engine_data)
return engine
执行的结果如下,其实没有耗费很多时间:

可以看到已经有一个 “ Alexnet.trt “ 生成出来了,或许因为经过串行化处理,所以档案少了非常多的容量:

接下来就是重头戏了,使用TensorRT进行Inference,先导入函式库,这边要注意common是从 /usr/src/tensorrt/samples/python/common.py复制出来的,engine是刚刚建构引擎的程序,log是我另外写的用来计时跟显示,其中trt的logger跟runtime也都先定义好了方便之后的呼叫:
import tensorrt as trt
from PIL import Image
import torchvision.transforms as T
import numpy as np
import common
from engine import load_engine
from log import timer, logger
TRT_LOGGER = trt.Logger(trt.Logger.WARNING)
trt_runtime = trt.Runtime(TRT_LOGGER)
加载数据的副函式,这边需要转成numpy格式,因为trt的引擎只吃numpy:
def load_data(path):
trans = T.Compose([
T.Resize(256), T.CenterCrop(224), T.ToTensor()
])
img = Image.open(path)
img_tensor = trans(img).unsqueeze(0)
return np.array(img_tensor)
接着加载引擎并且分配内存,binding是存放input、output所要占用的空间大小,stream则是pycuda的东西 ( cuda.Stream() ),是cuda计算缺一不可的成员;这边将inputs的内容替换成我要inference的照片,.host的意思是input的内存空间。
# load trt engine
load_trt = timer("Load TRT Engine")
trt_path = 'alexnet.trt'
engine = load_engine(trt_runtime, trt_path)
load_trt.end()
# allocate buffers
inputs, outputs, bindings, stream = common.allocate_buffers(engine)
# load data
inputs[0].host = load_data('../test_photo.jpg')
推论的部分则是透过common.do_inference来进行,create_execution_context是必要的旦没有开源所以不太清楚里面的内容,:
# inference
infer_trt = timer("TRT Inference")
with engine.create_execution_context() as context:
trt_outputs = common.do_inference(context, bindings=bindings, inputs=inputs, outputs=outputs, stream=stream)
preds = trt_outputs[0]
infer_trt.end()
最后取得标签以及对应的信心指数:
# Get Labels
f = open('../imagenet_classes.txt')
t = [ i.replace('\n','') for i in f.readlines()]
logger(f"Result : {t[np.argmax(preds)]}")

接着稍微比较了所有的框架,但可能因为同时进行三种不同的框架,Jetson Nano负荷不来所以时间都被拉长了,但我们仍然可以从比例看的出来彼此之间的差距,PyTorch:ORT:TRT大约是7:2:1,代表运行PyTorch所耗费的时间是开启TRT引擎的7倍!
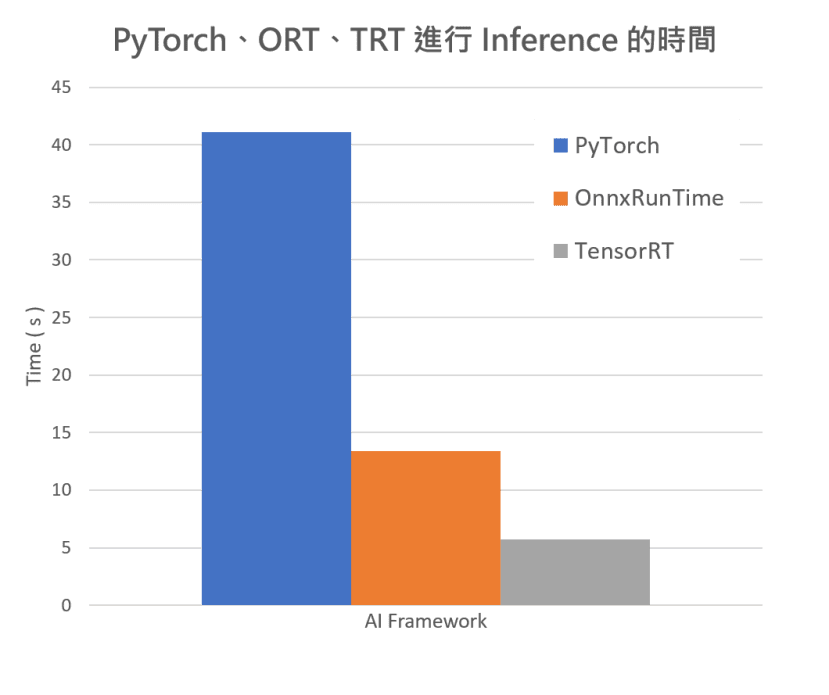
从下图可以看到蛮有趣的一点是理论上精度最高的是PyTorch的版本,结果在信心指数的部分却是最低的。

PyTorch使用TensorRT最简单的方式
torch2trt套件
接下来来介绍一下这个套件,可以只用少少的程序代码将PyTorch的模型转换成trt的模型,对于torch的爱好者来说实在是太棒了:
安装方法如下,这边我是采用我的映像档并且开启torch虚拟环境:
$ git clone https://github.com/NVIDIA-AI-IOT/torch2trt
$ cd torch2trt
$ workon torch
(torch) $ python3 setup.py install
torch2trt 将 PyTorch的模型转换成tensorrt
使用方法如下,透过torch2trt就可以直接转换,一样需要宣告输入的维度大小;接着也可以使用pytorch的方式进行储存;导入则需要使用TRTModule:
import torch
from torch2trt import torch2trt
from torchvision.models.alexnet import alexnet
# Load Alexnet Model
model = alexnet(pretrained=True).eval().cuda()
# TRT Model
x = torch.ones((1, 3, 224, 224)).cuda()
model_trt = torch2trt(model, [x])
# Save Model
alexnet_trt_pth = 'alexnet_trt.pth'
torch.save(model_trt.state_dict(), alexnet_trt_pth)
# Load Model
from torch2trt import TRTModule
model_trt = TRTModule()
model_trt.load_state_dict( torch.load('alexnet_trt.pth'))
完整程序代码如下:
import torch
from torch2trt import torch2trt
from torchvision import transforms as T
from torchvision.models.alexnet import alexnet
import time
# Use to print info and timing
from print_log import log
# Load Model
alexnet_pth = 'alexnet.pth'
load_model = log("Load Model...")
model = alexnet(pretrained=True).eval().cuda()
torch.save(model.state_dict(), alexnet_pth, _use_new_zipfile_serialization=False)
load_model.end()
# TRT Model
convert_model = log("Convert Model...")
x = torch.ones((1, 3, 224, 224)).cuda()
model_trt = torch2trt(model, [x])
convert_model.end()
# Save Model
alexnet_trt_pth = 'alexnet_trt.pth'
save_model = log("Saving TRT...")
torch.save(model_trt.state_dict(), alexnet_trt_pth)
save_model.end()
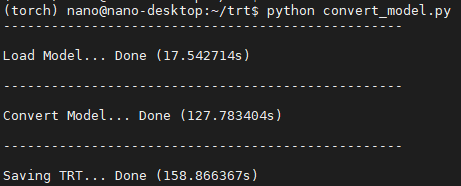
在 JetsonNano上的运作结果如下,转换的时间为127秒左右,储存的时间为160秒左右,基本上时间会因各个装置不同而改变,执行完之后就会看到多了两个档案 alexnet以及alexnet_trt:
接着我稍微改动了Github的范例,使用自己的猫咪照片来当作预测数据,首先加载模型、数据、卷标文件:
import torch
import torch.nn as nn
from torchvision import transforms as T
from torchvision.models.alexnet import alexnet
from torch2trt import torch2trt
from torch2trt import TRTModule
import os
import cv2
import PIL.Image as Image
import time
# Use to print info and timing
from print_log import log
def load_model():
model_log = log('Load {} ... '.format('alexnet & tensorrt'))
model = alexnet().eval().cuda()
model.load_state_dict(torch.load('alexnet.pth'))
model_trt = TRTModule()
model_trt.load_state_dict(torch.load('alexnet_trt.pth'))
model_log.end()
return (model, model_trt)
def load_data(img_path):
data_log = log('Load data ...')
img_pil = Image.open(img_path)
trans = T.Compose([T.Resize(256),T.CenterCrop(224), T.ToTensor()])
data_log.end()
return trans(img_pil).unsqueeze(0).cuda()
def load_label(label_path):
f = open( label_path, 'r')
return f.readlines()
接着先写好了inference的过程:
def infer(trg_model, trg_label, trg_tensor, info = 'Normal Model'):
softmax = nn.Softmax(dim=0)
infer_log = log('[{}] Start Inference ...'.format(info))
with torch.no_grad():
predict = trg_model(trg_tensor)[0]
predict_softmax = softmax(predict)
infer_log.end()
label = trg_label[torch.argmax(predict_softmax)].replace('\n',' ')
value = torch.max(predict_softmax)
return ( label, value)
最后就是整个运作的流程了:
if __name__ == "__main__":
# Load Model
model, model_trt = load_model()
# Input Data
img_path = 'test_photo.jpg'
img_tensor = load_data(img_path)
# Label
label_path = 'imagenet_classes.txt'
labels = load_label(label_path)
# Predict : Normal
label, val = infer(model, labels, img_tensor, "Normal AlexNet")
print('\nResult: {} {}\n'.format(label, val))
# Predict : TensorRT
label_trt, val_trt = infer(model_trt, labels, img_tensor, "TensorRT AlexNet")
print('\nResult: {} {}\n'.format(label_trt, val_trt))
获得的结果如下:

接着我们来尝试运作对象辨识的范例吧!我第一个想到的就是torchvision中常见的对象辨识fasterrcnn,但是他转换成trt过程问题很多,从这点也看的出来trt的支持度还没有非常高,常常因为一些没支持的层而无法转换这时候你就要自己去重新定义,对于新手而言实在是非常辛苦,所以Fasterrcnn这部分我就先跳过了,转战YOLOv5去尝试运行TensorRT看看。
YOLOv5使用TensorRT引擎方式
其实排除上述介绍的简单方式,正规的方式应该是先转成ONNX再转成TensorRT,其中yolov5就有提供转换成ONNX的方式
1. 转换成 ONNX格式再导入TensorRT ( 仅到汇出 )
这边我们直接使用YOLOv5来跑范例,先下载YOLOv5的Github并且开启虚拟环境,如果你是使用自己的环境则可以透过安装YOLOv5相依套件来完成:
$ git clone https://github.com/ultralytics/yolov5
$ cd yolov5
$ workon yolov5
Nano 上安装ONNX、coremltools:
$ sudo apt-get install protobuf-compiler libprotoc-div
$ pip install onnx
$ pip install coremltools==4.0
进行ONNX的转换:
$ source ~/.bashrc
$ workon yolov5
(yolov5) $ python models/export.py

预设是yolov5s.pt,执行完之后可以发现多了yolov5s.onnx以及yolov5.torchscript.pt,接着就可以使用ONNX的方法去导入使用,不过在yolo系列很少人会这样做,主要是因为yolo有自定义的层,可能会导致trt无法转换,但是也因为yolo已经很出名了,所以转换的部分已经有人整合得很好,可以直接拿来使用。
2. 使用tensorrtx直接转换 ( 可执行 )
YOLOv5有提供直接从.pt转成trt的方式,这时候就要参考另外一个github了 https://github.com/wang-xinyu/tensorrtx,里面有个yolov5的文件夹,按照ReadMe进行即可完成转换并且进行inferece:
1.复制两个Github并复制py到yolov5文件夹,运行gen_wts.py来生成yolov5s.wpt,这个是让TensorRT引擎运行的权重文件。
(yolov5) $ git clone https://github.com/wang-xinyu/tensorrtx.git
(yolov5) $ git clone https://github.com/ultralytics/yolov5.git
(yolov5) $ cd yolov5
(yolov5) $ cp yolov5s.pt weights/
(yolov5) $ cp ~/tensorrtx/yolov5/gen_wts.py .
(yolov5) $ python gen_wts.py
2.由于tensorrt引擎是基于C++,所以常常会使用cmake来建构成执行档。
(yolov5) $ cd ~/tensorrtx/yolov5
(yolov5) $ cp ~/yolov5/yolov5s.wts .
(yolov5) $ mkdir build
(yolov5) $ cd build
(yolov5) $ cmake ..
(yolov5) $ make
(yolov5) $ sudo ./yolov5 -s // serialize model to plan file i.e. 'yolov5s.engine'

建构完之后就可以直接透过下列指令执行,会输出图档 _bus.jpg、_zidane.jpg:
(yolov5) $ sudo ./yolov5 -d ~yolov5/data/images 
接下来还可以使用Python来进行Inference,需安装tensorrt跟pycuda:
(yolov5) $ pip install pycuda
(yolov5) $ python yolov5_trt.py
执行结果如下:

接着使用原生的yolov5进行inference,耗费时间约为0.549s、0.244s:

不晓得为什么跑了那么多范例,yolov5的速度没有提升反而下降,这个部分还需要研究一下…如果广大读者们知道的话麻烦在留言告诉我~
结语
从图片分类的范例来看的话,TensorRT还是非常的厉害的!但是目前支持度还是不太高,入门的难易度很高,所以如果有要使用自己的模型要好好研究一番,但如果是用GPU模型并且是直接使用常见模型的话TensorRT绝对一个大趋势,毕竟加速的效果真的不错。
參考資料
What is the difference between tflite and tensorRT?
TensorRT-Optimization-Principle
Speeding up Deep Learning Inference Using TensorFlow, ONNX, and TensorRT