Intel景深攝影機Python程式詳解2-於NVIDIA Jetson Nano執行RealSense D435 範例
关注文章
 戴夫来自 DesignSpark
戴夫来自 DesignSpark
你觉得这篇文章怎么样? 帮助我们为您提供更好的内容。
戴夫来自 DesignSpark
Thank you! Your feedback has been received.
戴夫来自 DesignSpark
There was a problem submitting your feedback, please try again later.
戴夫来自 DesignSpark
你觉得这篇文章怎么样?
| 作者 | 張嘉鈞 |
| 難度 | 普通 |
| 材料表 | Intel RealSense D435 X1 NVIDIA Jetson Nano X1 |
目錄
對齊RGB跟Depth畫面並去除背景 ( align-depth2color.py ) 2
解決掉幀問題 ( frame_queue_example.py ) 2
讀取預錄好的深度影像方式 ( read_bag_example.py ) 3
對齊RGB跟Depth畫面並去除背景 ( align-depth2color.py )
這個範例呈現如何將一公尺以外的內容進行去背,此範例的核心價值在於深度影像跟彩色影像如何對齊,對齊後又該使用什麼方式去除背景。
首先,先導入函式庫與宣告 RealSense物件 ( pipeline ) 與定義串流物件 ( config ):
# 導入函式庫
import pyrealsense2 as rs
import numpy as np
import cv2
# 建立一個context物件存放所有 RealSense 的處理函示
pipeline = rs.pipeline()
# 配置串流物件
config = rs.config()
接著可以透過wrapper去確認接上去的設備是L500系列還是D400系列,進而去調整RGB攝影機的解析度,最後定義完就可以開啟影像串流,細部的介紹可以參閱上篇程式詳解之內容:
# 可以透過下列程式取得設備資訊
# 透過 resolve 確認第一個可用的設備
pipeline_wrapper = rs.pipeline_wrapper(pipeline)
pipeline_profile = config.resolve(pipeline_wrapper)
# 取得該設備資訊
device = pipeline_profile.get_device()
device_product_line = str(device.get_info(rs.camera_info.product_line))
# 建立「深度」影像串流
config.enable_stream(rs.stream.depth, 640, 480, rs.format.z16, 30) # uint 16
# 建立「彩色」影像串流
# 由於 L500 系列的彩色攝影機解析度維 960 x 540 所以才需要取得設備資訊
if device_product_line == 'L500':
config.enable_stream(rs.stream.color, 960, 540, rs.format.bgr8, 30)
else:
config.enable_stream(rs.stream.color, 640, 480, rs.format.bgr8, 30)
# 開啟影像串流
profile = pipeline.start(config)
再來就是我們這次範例的重頭戲了 – 對齊,這邊要對齊的不僅是影像也有深度資訊,RealSense感測器獲得的深度資訊如何轉換成實際的公尺單位?深度影像跟RGB影像如何進行畫面對齊?
首先,先來處理深度單位的轉換,我們先取得深度感測器的物件,透過get_depth_scale取得到「RealSense的深度資訊與實際公尺單位的轉換比例」,接著我們要求一公尺以外的資訊要進行去背,所以定義了 clipping_distance_in_meters,但現在定義的是公尺單位需要轉換成深度資訊,所以這邊會再除以剛剛透過get_depth_scale取得到的數值,這樣就能成功轉換成對應的RealSense深度數值了:
# 取得深度感測器物件
depth_sensor = profile.get_device().first_depth_sensor()
# 取得深度感測器的 深度資訊與實際公尺之間的 映射尺度
# get_depth_scale -> Retrieves mapping between the units of the depth image and meters
depth_scale = depth_sensor.get_depth_scale()
print("Depth Scale is: " , depth_scale)
# 宣告多少公尺以內的資訊要顯示
clipping_distance_in_meters = 1 #1 meter
# 將 公尺資訊 轉換成 RealSense 的 深度單位
clipping_distance = clipping_distance_in_meters / depth_scale
緊接著就要來處理深度影像跟彩色影像的對齊,當初在opencv_viewer那個範例我們為了顯示在一起會使用cv2.resize的方式,但是並不是最好的做法 ( 圖片會被壓縮變形 ),pyrealsense提供的對齊方式是align,我們可以透過 rs.align()去處理深度影像需要對齊的內容,這邊就是以彩色影像 ( rs.stream.color )為基礎進行對齊,最後可以使用 process() 來實現對齊的動作,後續會再說明:
# 建立 對齊 物件 ( 以 color 為基準 )
align_to = rs.stream.color
# rs.align 讓 深度圖像 跟 其他圖像 對齊
align = rs.align(align_to)
# 使用 process 來實現剛剛宣告的 align 對齊功能
# aligned_frames = align.process(frames)
上面定義完之後就可以進行即時影像的擷取與處理了,一樣透過 wait_for_frames等待最新的複合式影像物件( frames) 包含彩色影像跟深度影像,接著直接使用 align.process 將深度影像對齊彩色影像:
# 串流迴圈
try:
while True:
# 等待最新的影像,wait_for_frames返回的是一個合成的影像
frames = pipeline.wait_for_frames()
# frames.get_depth_frame() is a 640x360 depth image
# 使用 process 來實現剛剛宣告的 align 對齊功能
aligned_frames = align.process(frames)
對齊完之後就可以透過get_depth_frames跟get_color_frames來取得影像了,這邊我也取得了原先的影像,最後註解的地方如果解除註解就會看到原先的解析度跟轉換後的解析度:
# 取得對齊後的影像
depth_frame = frames.get_depth_frame()
aligned_depth_frame = aligned_frames.get_depth_frame() # aligned_depth_frame is a 640x480 depth image
color_frame = aligned_frames.get_color_frame()
# 驗證是否都有影像
if not aligned_depth_frame or not color_frame:
continue
# 轉換成 numpy
depth_image = np.asanyarray(aligned_depth_frame.get_data())
color_image = np.asanyarray(color_frame.get_data())
# 顯示解析度
# print('Org (L500) : ', np.shape(np.asanyarray(depth_frame.get_data())), end='\t')
# print('After align : ', np.shape(np.asanyarray(aligned_depth_frame.get_data())))
註解掉之後可以發現,解析度從原本的 640x480變成了 960x540:
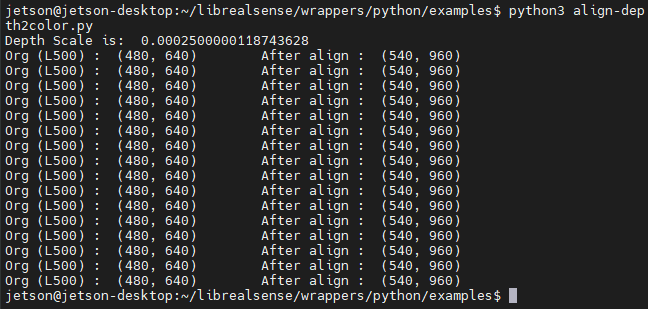
緊接著就是去背問題,我們可以直接透過dstack的方式去將一個維度的資料複製成三個維度 (範例結尾有補充說明),這樣影像的資訊就好比一張灰階照片,接著使用 np.where即可進行條件去背。這邊要注意的是depth_image_3d裡面的數值代表的還是屬於深度資訊;np.where(condition, x, y) 滿足 condition 輸出 x 否則輸出 y,滿足距離大於1公尺以及辨識不出來這兩個條件的就輸出 grey_color,沒有滿足的就輸出 color_image:
# 刪除背景 : 將背景顏色調整成 灰色
grey_color = 153
# 深度影像只有 1 個 channel,透過 dstack 建立 灰階圖 ( 這邊RGB的數值就是 深度訊息 )
depth_image_3d = np.dstack((depth_image, depth_image, depth_image)) #depth image is 1 channel, color is 3 channels
# 當 深度大於 1 公尺 或是 偵測不出來 就會 以 grey_color 取代
bg_removed = np.where((depth_image_3d > clipping_distance) | (depth_image_3d <= 0), grey_color, color_image)
最後將深度圖跟去背圖合併並且當偵測到按下按鈕「q」就會關閉所有視窗:
# 將深度影像轉換成 彩色影像
depth_colormap = cv2.applyColorMap(cv2.convertScaleAbs(depth_image, alpha=0.03), cv2.COLORMAP_JET)
# 合併圖像 左為去背圖,右為深度圖
images = np.hstack((bg_removed, depth_colormap))
# cv2.namedWindow('Align Example', cv2.WINDOW_NORMAL)
cv2.imshow('Align Example', images)
key = cv2.waitKey(1)
# Press esc or 'q' to close the image window
if key & 0xFF == ord('q') or key == 27:
cv2.destroyAllWindows()
break
finally:
pipeline.stop()
到這邊這個範例就結束了!
我在稍微針對np.dstack進行補充說明,下列範例是一個2x2的深度影像資訊,我們可以透過dstack轉換成三維度的影像:
import numpy as np
a = np.asanyarray( [[8000, 2000],
[0, 125]])
b = np.dstack((a,a,a))
print(a.shape, b.shape)
print('\n')
print(a)
print('\n')
print(b)
顯示的結果如下,原本是 ( 2, 2, 1) 變成了 ( 2, 2, 3):

而使用OpenCV顯示的話會類似下圖:

解決掉幀問題 ( frame_queue_example.py )
當我們在進行多個影像串流的時候總是會發生延遲問題導致掉幀,RealSense也提供了一些簡單的方式來處理這個問題。
首先要先製造掉幀的現象,這邊撰寫了slow_processing、slower_processing來模擬掉幀現象,這邊輸入的是影像物件,透過get_frame_number可以獲取現在的影像是第幾幀,於slow_processing我們每20幀就會暫停0.25秒;slower_processing則是每20幀就暫停1秒,用這種方式來模擬掉幀狀況:
# First import the library
import pyrealsense2 as rs
import time
# 每20個frame會暫停0.25秒 製造短暫的延遲
def slow_processing(frame):
n = frame.get_frame_number()
if n % 20 == 0:
time.sleep(1/4)
print(n)
# 製造更延遲的狀況
def slower_processing(frame):
n = frame.get_frame_number()
if n % 20 == 0:
time.sleep(1)
print(n)
接著與先前一樣先取得RealSense的物件並且宣告影像串流物件:
try:
# Create a pipeline
pipeline = rs.pipeline()
# Create a config and configure the pipeline to stream
# different resolutions of color and depth streams
config = rs.config()
config.enable_stream(rs.stream.depth, 640, 480, rs.format.z16, 30)
接下來會分成幾個部分來展示延遲以及改善的方式,一開始我們先確認之前寫的延遲程式有無問題,運行 slow_processing 5秒看成效如何:
print("Slow callback")
# 開始影像串流
pipeline.start(config)
# 讓 slow_processing 運行5秒就好
start = time.time()
while time.time() - start < 5:
# 取得最新的影像物件
frames = pipeline.wait_for_frames()
# 運行slow_processing
slow_processing(frames)
# 關閉RealSense物件
pipeline.stop()
成果如下,可以注意到當frame數到20的時候下一刻會變成27代表這0.25秒中間遺失了7個frame:
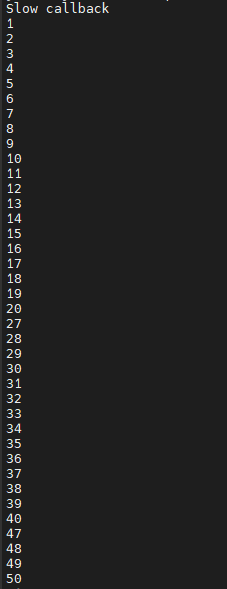
接著我們可以加上 queue 來將被丟失的幀存放在記憶體當中,frame_queue( ) 括弧當中的數值代表可以保存的幀數:
# 加上 queue
print("Slow callback + queue")
# frame_queue(n) n 是可以保留多少幀,這邊保留了50幀的空間
queue = rs.frame_queue(50)
# 開啟串流
pipeline.start(config, queue)
# 執行五秒
start = time.time()
while time.time() - start < 5:
frames = queue.wait_for_frame()
# 一樣使用 slow_processing
slow_processing(frames)
結果如下,可以發現原本的在第20幀的時候會因為延遲而丟失7幀,加上了queue之後就沒有這樣的問題了,那待我們再來測試一下延遲更久的狀況:
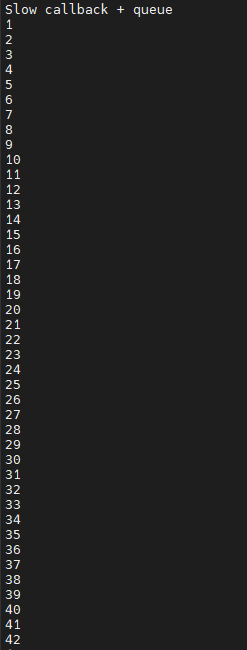
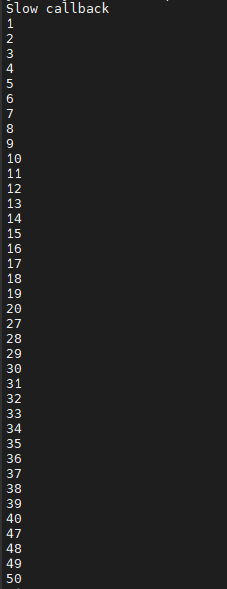
一樣的程式碼只是我們將slow_processing 改成 slower_processing:
print("Slower callback + queue")
queue = rs.frame_queue(50)
pipeline.start(config, queue)
start = time.time()
while time.time() - start < 5:
frames = queue.wait_for_frame()
slower_processing(frames)
pipeline.stop()
結果如下,可以注意到雖然queue設到50但是因為延遲時間太久所以會導致queue無法進行備份最後直接捨棄掉pool裡的幀:
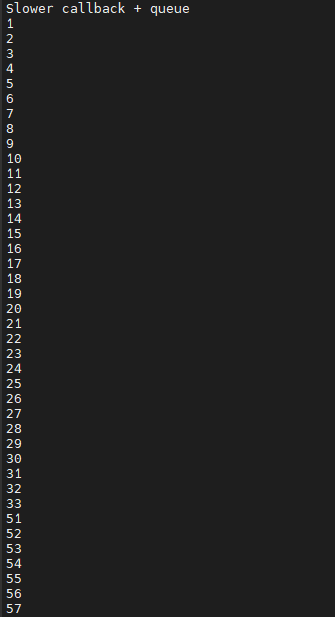
最後解決這種問題的方法就是keep_frames,我們在宣告frame_queue的時候加上這個參數,讓queue裡面的幀會被保留住:
print("Slower callback + keeping queue")
queue = rs.frame_queue(50, keep_frames=True)
pipeline.start(config, queue)
start = time.time()
while time.time() - start < 5:
frames = queue.wait_for_frame()
slower_processing(frames)
pipeline.stop()
這個範例如果介紹的有錯誤或不夠清楚,請在下方留言,也可以參考原廠資料:https://intelrealsense.github.io/librealsense/python_docs
錄製深度影像 (.bag)
介紹之前先講一下 rosbag (http://wiki.ros.org/rosbag),他是基於ROS所開發的一個紀錄工具,可以記錄機器人運行的數據資料以及影像等等的資訊。那可能因為RealSense開發者大部分是以機器人為主所以他們也直接使用相關的紀錄方式。
要錄製深度影響其實非常的簡單,你只需要在宣告config之後,在宣告enable_record_to_file() 即可,括弧當中應輸入檔案名稱,範例如下。
# 建立一個context物件存放所有 RealSense 的處理函示
pipeline = rs.pipeline()
# 配置串流物件
config = rs.config()
# 建立「深度」影像串流
config.enable_stream(rs.stream.depth, 640, 480, rs.format.z16, 30)
# 將影像數據輸出到 test.bag 當中
config.enable_record_to_file('test.bag')
具體程式可以使用opencv_viewer_example.py來修改,成果在read_bag_example的demo可以看到 ( 下一個範例 ),我自己錄製的畫面。
讀取預錄好的深度影像方式
( read_bag_example.py )
基本上看到這裡一些基本的動作讀者們應該都知道了,所以我這邊註解會少一些,第一步基本上就是導入函式以及宣告pipeline等等的,比較特別的是這邊config要增加一段 enable_device_from_file(config, 'test.bag'),告訴config資料要從這個檔案讀取,而不是RealSense:
import pyrealsense2 as rs
import numpy as np
import cv2
import argparse
import os.path
try:
pipeline = rs.pipeline()
config = rs.config()
# 告訴 config 資訊從檔案讀取
rs.config.enable_device_from_file(config, 'test.bag')
# 一樣要建立深度影像串流
config.enable_stream(rs.stream.depth, rs.format.z16, 30)
# 開啟串流
pipeline.start(config)
# 宣告著色器 預設是 jet colormap
colorizer = rs.colorizer();
接著我們就像一般使用一樣,取得frames、取得深度影像,轉換成numpy,用opencv顯示:
while True:
frames = pipeline.wait_for_frames()
depth_frame = frames.get_depth_frame()
# 將深度影像著色成 jet colormap
depth_color_frame = colorizer.colorize(depth_frame)
# 轉換成 numpy array 讓 opencv 顯示
depth_color_image = np.asanyarray(depth_color_frame.get_data())
# Opencv 顯示以及按下 q 離開
cv2.imshow("Depth Stream", depth_color_image)
key = cv2.waitKey(1)
if key == 27:
cv2.destroyAllWindows()
break
finally:
pass
成果如下:
結語
我們詳解了總共六個範例,相信大部分的狀況,讀者們都已經可以Handle了!下一次將會介紹我們如何使用物件偵測搭配RealSense。
评论