 戴夫来自 DesignSpark
戴夫来自 DesignSpark
你觉得这篇文章怎么样? 帮助我们为您提供更好的内容。
戴夫来自 DesignSpark
Thank you! Your feedback has been received.
戴夫来自 DesignSpark
There was a problem submitting your feedback, please try again later.
戴夫来自 DesignSpark
你觉得这篇文章怎么样?
现场可编程门阵列 (FPGA) 是一组逻辑门,这些逻辑门经过硬件编程以执行用户指定的任务。基于处理器的平台。得益于高速嵌入式资源,如 DSP 片和快速存储器,FPGA 现在是也用于算法加速。
该项目将 Pi 估计算法在 FPGA 硬件中的运行速度与同一算法在处理器上的运行速度进行了比较。ARM/FPGA SoC 开发的核心选项。Xilinx Zynq-7000 架构紧密集成了单核或双核 667MHz ARM Cortex -带有 Xilinx 7 系列 FPGA 的 A9 处理器。
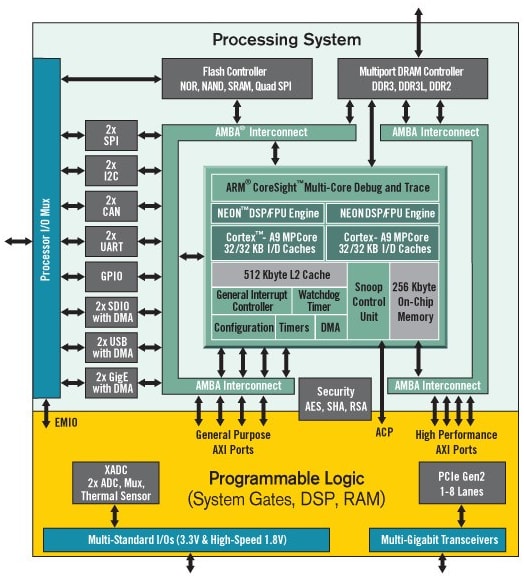
Zynq APSoC Architecture
Cora Z7 产品变体分别称为 Cora Z7-10 (184-0484) 和 Cora Z7-07S (184-0456) 。Cora Z7 广泛的硬件接口,从 1Gbps 以太网 PHY 到模拟到数字转换器和通用输入/输出引脚,使其成为开发各种嵌入式应用程序的理想平台。
| Product Variant | Cora Z7-10 | Cora Z7-07S |
| Zynq Part | XC7Z010-1CLG400C | XC7Z007S-1CLG400C |
| ARM Processor Cores | 2 | 1 |
| 1 MSPS On-chip ADC | Yes | Yes |
| Look-up Tables (LUTs) | 17,600 | 14,400 |
| Flip-Flops | 35,200 | 28,800 |
| DSP Slices | 80 | 66 |
| Block RAM | 270 KB | 225 KB |
| Clock Management Tiles | 2 | 2 |

Cora Z7 Zynq 7000 Platform
Estimating Pi using Monte Carlo Method
有很多网站解释Pi Estimation through Monte Carlo Method,可以看看这个网站。原理是产生大量的随机点,看有多少落在单位正方形围成的圆内。 正方形的面积为 1,而圆形的面积为 pi / 4,因为半径为 0.5。有大量随机点 (x,y),

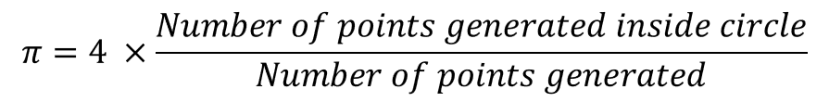
要实现该算法,您只需生成随机点(x, y) ,然后检查该点与原点 (x,y) 的距离是否小于或等于 1 (x2 + y2 <= 1). 如果是,您增加出现在圆圈内的点数。
在 ARM 处理器和 Linux 中运行算法
本教程 教你如何在Cora Z7 ARM处理器上启动Linux。然后你可以使用Go编程语言通过蒙特卡洛方法估计Pi。你需要的是Ubuntu 16.04.3,Xilinx Viavdo 2017.4, Petalinux, Golang. 安装通过apt-get,但其他工具需要通过Xilinx官网下载,需要使用Petalinux引导进入Linux。
下表显示了每个 Cora Z7 变体处理 100,000 个蒙特卡罗样本所花费的时间。

在 FPGA 结构中运行算法
本教程 向您展示如何在 FPGA 逻辑中构建算法。FPGA 结构包含称为数字信号处理 (DSP) 切片的元素。在运行蒙特卡罗方法的情况下,您需要进行两次乘法运算(x*x 和 y *y)。只要每个乘法运算的结果小于 48 位宽,您只需在每个运行 Monte Carlo 模拟的代码实例中使用两个 Cora 的 DSP 片。随机样本是通过使用线性反馈移位寄存器(LFSR),种子值由控制器提供,整个系统的时钟为125MHz。
查看下面粘贴的每个 Cora 变体打印的结果:
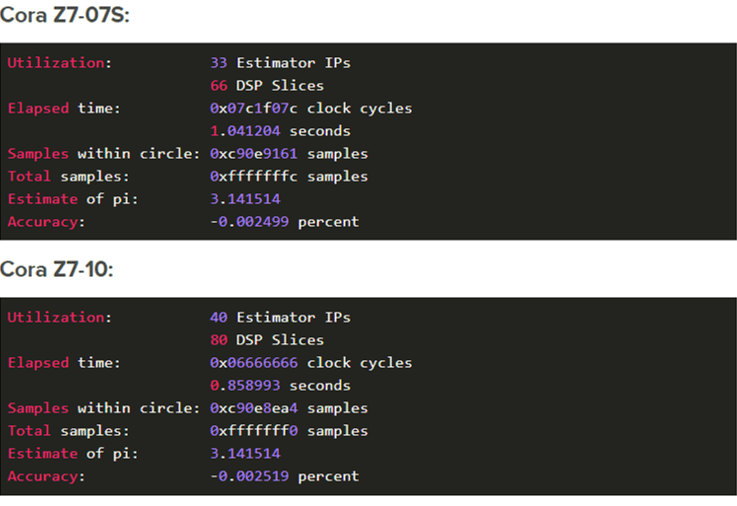
FPGA Vs Processor
两个 Cora Z7 变体中较慢的一个能够在大约一秒内处理一个完整的 32 位整数的样本,而在 Linux 中,两个变体中较快的仅在 1.8 秒内处理 100,000,000 个样本。该算法的版本快了 77 倍. FPGA 设计每个时钟周期可以处理 9 个 Monte Carlo 样本(每 8 纳秒一个时钟周期)。

评论