Google Coral USB Accelerator搭配树莓派4运行Embedded Teachable Machine – 下篇
关注文章
 戴夫来自 DesignSpark
戴夫来自 DesignSpark
你觉得这篇文章怎么样? 帮助我们为您提供更好的内容。
戴夫来自 DesignSpark
Thank you! Your feedback has been received.
戴夫来自 DesignSpark
There was a problem submitting your feedback, please try again later.
戴夫来自 DesignSpark
你觉得这篇文章怎么样?
|
作者 |
张嘉钧 |
|
难度 |
普通 |
Embedded Teachable Machine 介绍
Embedded Teachable Machine是Google在推出Coral USB Accelerator时所设计搭配的一个小项目,可透过按钮来执行拍照并且实时进行图片分类,少量的资料就可以完成训练。
会这么强大、快速的主要原因是透过已经训练好的模型 ( Mobile Net ) 来进行辨识,它可以明确的分类当初训练的1000种类别图片 ( http://image-net.org/index ),在神经网络输出结果前,它会针对输入的图片进行特征撷取获得一组特征或称为语意 ( semantic representation ),神经网络的最后一层再根据这些特征去分类到底比较符合1000种类别中的哪一个类别,实际上会输出1000个数值,分数最大的代表该模型认为可能是属于该类别。

而我们这次的 Embedded Teachable Machine是采用 Headless 型式的模型并将该模型套用到我们的数据上面。Headless顾名思义就是去掉头,在这边代表模型的去除模型的最后一层,这时我们将图片丢进去一样会获得一组特征,原本在最后一层会将其输出1000个数值,但这时候我们已经将最后一层去除掉了,变成会直接获取到该张图片的特征向量。
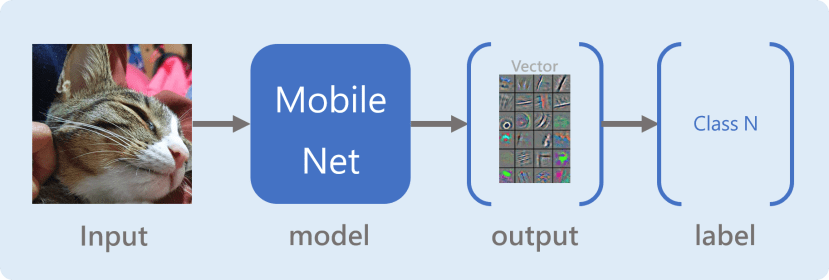
每一次按下按钮的时候,会记录该特征向量以及对应的卷标 ( 第几个按钮 ),下一张照片将透过KNN算法来判断是比较接近哪一个类别,因为相似的图片是会获得相似的特征向量,而KNN就是将相似的数据分类清楚。
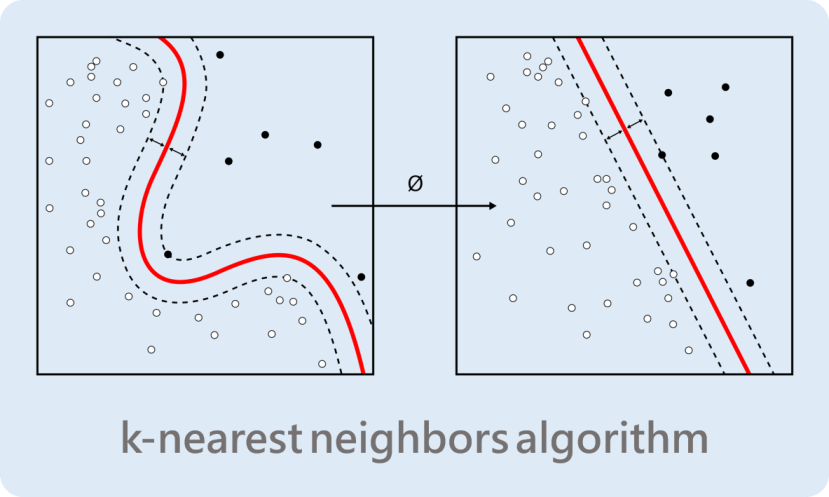
理论终于介绍完了接下来来进行实作吧!之前已经有写过简易版的教学了,但是有时候树莓派接线要查线路图对脚位还是稍微有点麻烦,所以我们这次采用T行转接版,直接将树莓派的脚位都写出来了,使用上会更加方便。
Embedded Teachable Machine 实作
材料表
|
l 树莓派4及其电源线 X1 l 树莓派T型GPIO扩展板+40P扁平电缆 X1 l Google Coral USB Accelerator X1 l WebCam X1 l 单芯线自行裁切 l 330 Ohm 1/4W电阻 X4 l 不同色LED X4 l 4 pin按钮 X5 l 10cm公母杜邦线 X10 l 面包板 X1 |
安装步骤
步骤一、树莓派接上电源、Coral、Webcam

步骤二、T行转接版安装

步骤三、按钮跟LED接线方法,这是官方的图,但我们这里有使用T行转接板,所以连接到树莓派的地方稍微不同

实际安装画面

步骤四、连接T行转接版
|
树莓派GPIO脚位及坐标 |
面包板接线 |
|
GPIO4 (J,4) |
黄色按钮(A,5) |
|
GPIO17(J,6) |
黄色LED灯电阻(A,7) |
|
GPIO27(J,7) |
绿色按钮(A,12) |
|
GPIO22(J,8) |
绿色LED灯电阻(A,14) |
|
GPIO5(J,15) |
橘色按钮(A,19) |
|
GPIO6(J,16) |
橘色LED灯电阻(A,21) |
|
GPIO13(J,17) |
红色按钮(A,26) |
|
GPIO19(J,18) |
红色LED灯电阻(A,28) |
|
GPIO26(J,19) |
蓝色按钮(A,35) |

完成图

准备执行环境
cd /home/pi
git clone https://github.com/google-coral/project-teachable.git
cd project-teachable
sh install_requirements.sh
修改程序代码的GPIO脚位
为了让线都接在T行转接版的同一侧所以要修改一下GPIO脚位,在teachable.py中的class UI_Raspberry中修改:
# self._buttons = [16 , 6 , 5 , 24, 27]
# self._LEDs = [20, 13, 12, 25, 22]
self._buttons = [26 , 4 , 27 , 5, 13]
self._LEDs = [21, 17, 22, 6, 19]
执行GPIO测试
透过下列程序代码进行GPIO的测试,执行之后按下按钮进行测试,如果接法与我相同,左至右的按钮个别是 [ 1, 2 ,3 ,0 ]。
cd ~/project-teachable
python3 teachable.py --testui
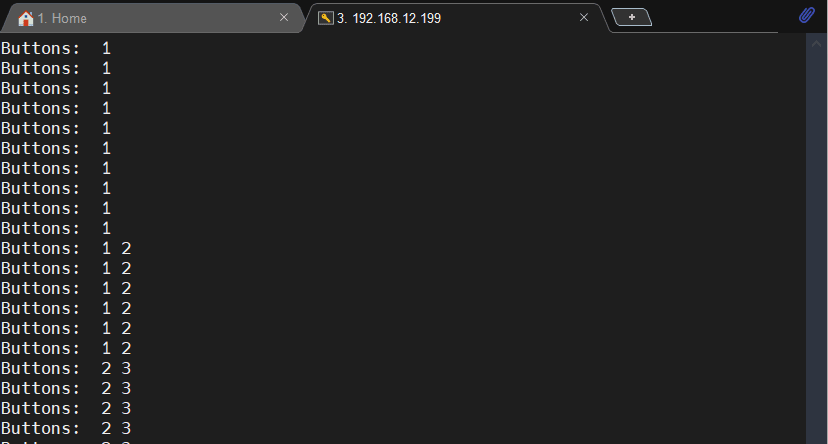
执行程序
cd ~/project-teachable
python3 teachable.py
虽然是个良好的体验,但是还是有些不方便的地方,第一个是拍完照无法储存下一次开起就重新开始;第二个是用gstreamer来做除了不熟悉之外,用MobaXterm远程的时候也无法读取,所以想要改良成OpenCV。
改良一、储存照片并能重新读取
我预计要修改的程序是Teachable.py中的TachableMachineKNN,这边是针对图片进行KNN分类的源代码,先进行分析一下,一开始要先宣告buffer跟KNN用的engine,在Classify函式中会对该图进行inference,获得特征语意 ( emb ),接着使用 Counter来获取buffer中最多的类别,for循环的部分则是要显示LED灯的信息,最后的if是按下四个按钮就离开程序:
class TeachableMachineKNN(TeachableMachine):
def __init__(self, model_path, ui, KNN=3):
TeachableMachine.__init__(self, model_path, ui)
self._buffer = deque(maxlen = 4)
self._engine = KNNEmbeddingEngine(model_path, KNN)
def classify(self, img, svg):
# Classify current image and determine
emb = self._engine.DetectWithImage(img)
self._buffer.append(self._engine.kNNEmbedding(emb))
classification = Counter(self._buffer).most_common(1)[0][0]
# Interpret user button presses (if any)
debounced_buttons = self._ui.getDebouncedButtonState()
for i, b in enumerate(debounced_buttons):
if not b: continue
if i == 0: self._engine.clear() # Hitting button 0 resets
else : self._engine.addEmbedding(emb, i) # otherwise the button # is the class
# Hitting exactly all 4 class buttons simultaneously quits the program.
if sum(filter(lambda x:x, debounced_buttons[1:])) == 4 and not debounced_buttons[0]:
self.clean_shutdown = True
return True # return True to shut down pipeline
return self.visualize(classification, svg)
有了初步的了解之后先来整理一下思绪,我的作法很简单,预计在一开始呼叫TeachableMachine的时候先读取特定文件夹,并且把所有数据丢进engine中,接着再进行与上述雷同的动作,我先介绍一下新增的三个副函式
- check_dir:确认文件夹是否存在?如果不存在就创建一个,如果存在就读取该文件夹所有类别的照片。
- clear_dir:删除文件夹内容并创建一个空的。
- reload_dir:将读取的数据丢进TeachableMachineEngine先进行训练。
开始之前,因为我们需要先导入shutil函式库:
import shutil为了完成这个功能,第一步是按下按钮的时候可以储存图片,需要先修改classify文件夹,第一个修改的地方是「按下清除按钮的时候」,除了清除engine的数据外还须清除储存的所有照片,也就是运行clear_dir()函式,接着修改的是「按下其他按钮的时候」需要进行储存的动作,这边文件格式是PIL所以直接img.save就可以了:
def classify(self, img, svg):
# Classify current image and determine
emb = self._engine.DetectWithImage(img)
self._buffer.append(self._engine.kNNEmbedding(emb))
classification = Counter(self._buffer).most_common(1)[0][0]
# Interpret user button presses (if any)
debounced_buttons = self._ui.getDebouncedButtonState()
for i, b in enumerate(debounced_buttons):
if not b: continue
if i == 0:
self._engine.clear() # Hitting button 0 resets
self.clear_dir() ### Modify by Chun : clear data folder
else :
self._engine.addEmbedding(emb, i) # otherwise the button # is the class
### Modify by Chun : Save Image & Label
save_path = os.path.join(self.trg_folder[i-1], f'{str(self.img_nums[i-1])}.jpg')
img.save(save_path)
self.img_nums[i-1] += 1
### End of Modify
有了拍照储存的动作之后,我们需要在一开始执行的时候就读取旧有的数据,并且先运行KNN,由于只要运行一次就可以所以我们修改的地方会着重在init当中,data_path是我们预设的文件夹,会先进行check_dir()查看文件夹是否存在、是否有数据,如果有数据的话img_nums就会大于0,接着再进行reload_dir():
def __init__(self, model_path, ui, KNN=3):
TeachableMachine.__init__(self, model_path, ui)
self._buffer = deque(maxlen = 4)
self._engine = KNNEmbeddingEngine(model_path, KNN)
### Modify
self.cls_nums = KNN+1
self.data_path = 'data'
self.trg_folder = [] # trg_folder = './data/{Class}'
self.img_nums = [0, 0, 0, 0] # img_nums = [ x, x, x, x], count each class's images
self.check_dir()
if sum(self.img_nums) != 0:
print('\n', 'Reload Data', end=' ... ')
self.reload_data()
### End of Modify
其余三个副函式的内容如下:
def check_dir(self):
print('\n', 'Check Dir', end=' ... ')
for cls in range(1, self.cls_nums+1): # Classes from 1 to 4
self.trg_folder.append(os.path.join(self.data_path, str(cls)))
# Check Directory is existed or not
if os.path.exists(self.trg_folder[cls-1]) is False:
os.makedirs(self.trg_folder[cls-1])
self.img_nums[cls-1] = 0
else:
self.img_nums[cls-1] = len(os.listdir(self.trg_folder[cls-1]))
def clear_dir(self):
shutil.rmtree(self.data_path)
self.check_dir()
print('\n\n Clear \n\n')
def reload_data(self):
t_start = time.time()
for cls in range(1, self.cls_nums+1): # 1 ~ 4
if self.img_nums[cls-1] != 0 :
for idx in range(0, self.img_nums[cls-1]):
img = Image.open(os.path.join(self.trg_folder[cls-1], f'{idx}.jpg'))
emb = self._engine.DetectWithImage(img)
self._buffer.append(self._engine.kNNEmbedding(emb))
classification = Counter(self._buffer).most_common(1)[0][0]
self._engine.addEmbedding(emb, cls)
print('Done({:.3f}s)'.format(time.time()-t_start))
最后一步就是将main()中的 TeachableMachineKNN改成你修改好的版本,如果你是像我一样额外写一个副函式的话就需要修改,如果只是修改原本的就可以不用更改。
# teachable = TeachableMachineKNN(args.model, ui)
teachable = TeachableMachineKNN_ByChun(args.model, ui)
修改后的结果:
第二篇
改良二、修改成OpenCV
上一篇已经将Embedded Teachable Machine 改良可以储存数据以及读取旧有数据了,接下来我想将其改良成OpenCV格式, Gstream虽然效能比较强大但我还在熟悉中,如果使用MobaXterm远程的时候也会取得不到画面,再来就是Tkinter上我确定能使用OpenCV但是Gstream还要研究。
INFO:
Modify Original Code to Save and Reload Data, and change PyGi to OpenCV.
Modify Items:
1. Modify TeachableMachineKNN_ByChun
2. Change PyGi to OpenCV in main()
3. Use Thread to Improve Delay of Streaming : ThreadCapture()
4. Modify TeachableMachine.visiual() to get_results()
综合上述问题我决定来改良一下,首先要找到问题点!在哪里取得图像的?:

找到了!在teachable_reload.py中的第386行,应该是类似开一个Thread不断运行teachable.classify的用法,所以接下就是将其批注掉开始一连串修改之旅吧!
由于它的写法是类似Thread的写法所以我也直接开一个Thread来执行,使用Thread也可以让影像更流畅,取用的流程更直觉,基本上OpenCV Thread的写法都很雷同,注意的点就是我特别导入了 knn,方便日后直接将影像跟KNN Engine调用,主要的几个函式:
- start():开启线程,不断执行current_frame取得最新影像
- stop():关闭线程
- get_frame():「回传」当前影像
- crop_frame():裁切影像
- current_frame():取得当前影像
run_knn():将当前影像丢入KNN引擎并回传结果
### Modify by Chun
class ThreadCapture():
def __init__(self, knn):
self.frame = []
self.status = False
self.isStop = False
self.knn = knn
self.cap = cv2.VideoCapture(0)
self.cap.set(cv2.CAP_PROP_FRAME_WIDTH, 640)
self.cap.set(cv2.CAP_PROP_FRAME_WIDTH, 480)
def start(self):
threading.Thread(target=self.current_frame, daemon=True, args=()).start()
def stop(self):
self.isStop = True
def get_frame(self):
return self.frame
def crop_frame(self):
h = self.frame.shape[0]
w = self.frame.shape[1]
cut = int((w-h)/2)
self.frame = self.frame[0:h, cut:w-cut]
def current_frame(self):
while(not self.isStop):
self.status, self.frame = self.cap.read()
self.crop_frame()
self.cap.release()
def run_knn(self):
img_resize = cv2.resize(self.frame, (224, 224))
img = cv2.cvtColor(img_resize, cv2.COLOR_BGR2RGB)
img_pil = Image.fromarray(img)
return self.knn.classify(img_pil)
### End of Modify
取得影像没问题了,但是最麻烦的地方是self.knn.classify(img_pil),这是我修改后的副函式,先来看一下原本的,光是引入的数值就有两个,第一个是img,第二个是svg:
def classify(self, img, svg):
#省略省略
return self.visualize(classification, svg)
Visualize的部分我没太深入研究但是可以看的出来svg应该是原图的意思,就算不了解Gstreamer但可以看到关键词add、text,代表在图上加入文字:
def visualize(self, classification, svg):
self._frame_times.append(time.time())
fps = len(self._frame_times)/float(self._frame_times[-1] - self._frame_times[0] + 0.001)
# Print/Display results
self._ui.setOnlyLED(classification)
classes = ['--', 'One', 'Two', 'Three', 'Four']
status = 'fps %.1f; #examples: %d; Class % 7s'%(
fps, self._engine.exampleCount(),
classes[classification or 0])
print(status)
svg.add(svg.text(status, insert=(26, 26), fill='black', font_size='20'))
svg.add(svg.text(status, insert=(25, 25), fill='white', font_size='20'))
我们希望获得的应该是status中的Class字段的内容,也就是 classes[classification or 0],这个是它辨识出来的结果,所以我复制了visualize()命名为get_results() 该函式将返回status跟classes[classification or 0],并且将gstream显示的程序删掉:
def get_results(self, classification):
self._frame_times.append(time.time())
fps = len(self._frame_times)/float(self._frame_times[-1] - self._frame_times[0] + 0.001)
# Print/Display results
self._ui.setOnlyLED(classification)
classes = ['--', 'One', 'Two', 'Three', 'Four']
status = 'fps %.1f; #examples: %d; Class % 7s'%(
fps, self._engine.exampleCount(),
classes[classification or 0])
return status, classes[classification or 0]
并且 classify的部分原本有svg这个引入参数,也需要将其删掉只留下img:
class TeachableMachineKNN_ByChun(TeachableMachine):
# 省略省略
def classify(self, img):
# 省略省略
return self.get_results(classification) ### Modify by Chun
最后在main()的部分使用OpenCV开启实时影像,先宣告刚刚写好的对象ThreadCapture,停留一秒确保thread有撷取到影像,使用while循环持续获取最新的影像,取得影像后就执行run_knn()并显示结果、图片,按下按键q的时候跳出循环,停止线程:
### Modify by Chun
# print('Start Pipeline.')
# result = gstreamer.run_pipeline(teachable.classify)
stream = ThreadCapture(teachable)
stream.start()
time.sleep(1) # 等待thread撷取到摄影机影像
while(True):
status, frame = stream.get_frame()
if status:
info, res = stream.run_knn()
print(info)
cv2.imshow('Test', frame)
if cv2.waitKey(1)==ord('q'):
break
ui.wiggleLEDs(4)
stream.stop()
cv2.destroyAllWindows()
### End of Modify
执行结果如下,可以注意到画面跟原本的不太一样,文字也没有显示所以下一步要来显示文字,可以按下按键q离开程序:

放上文字的方法非常简单,只需要增加下列程序在print(info)下方就可以了
cv2.putText(frame, info, (10,40), cv2.FONT_HERSHEY_SIMPLEX, 0.8, (0,0,255), 1, cv2.LINE_AA)
结语
这样子就完成第二个项目了!这次带大家认识树梅派加上Coral加速,光是第一个范例已经能大幅增加速度,接着透过第二个范例熟悉Coral的用法,也顺便介绍了类似K-NN的方法 (Embedded),上下两篇整个技术量充足阿!
相关文章
用 Google Coral USB Accelerator 搭配 Raspberry Pi 实作 Teachable Machine
评论