Quand la redondance est une bonne chose
Suivez l'article
 Dave from DesignSpark
Dave from DesignSpark
Que pensez-vous de cet article ? Aidez-nous à vous fournir un meilleur contenu.
Dave from DesignSpark
Merci! Vos commentaires ont été reçus.
Dave from DesignSpark
There was a problem submitting your feedback, please try again later.
Dave from DesignSpark
Que pensez-vous de cet article ?

La technique de redondance en mode duplex, triplex ou même quadruplex des circuits critiques pour augmenter la fiabilité existe depuis longtemps. Naturellement, les premiers systèmes ont été conçus pour des applications aérospatiales militaires car la redondance était chère. Les avions ont pu voler en toute sécurité à l’aide d’un ordinateur, une technique appelée “fly-by-wire”, augmentant les performances de l’avion bien au-delà de la capacité d’un pilote humain. L’ordinateur embarqué de la fusée Saturn V Apollo des années 60 était doté d’une redondance triplex, ce qui explique probablement son incroyable fiabilité dans les conditions extrêmes d’un lancement. L’utilisation de modules de circuit identiques en double ou en triple dans le but d’empêcher un fonctionnement dangereux est appelée redondance modulaire double (DMR) ou redondance modulaire triple (TMR).
La redondance du capteur
Nous pouvons voir l’essentiel du fonctionnement du capteur DMR et TMR sur la Fig.1. La plupart des capteurs modernes possèdent des sorties numériques de série (p. ex. UART, SPI ou bus I²C), de sorte que le dispositif de vote logique qui compare les données risque d’être un petit microcontrôleur de faible puissance. La redondance modulaire est une technique de fusion du capteur dont le seul but est d’améliorer la fiabilité du système . Dans le cas d’une DMR, le capteur peut détecter un échec critique et permet un arrêt contrôlé du système. En d’autres termes, il améliore la probabilité d’un “scénario de sécurité”. La TMR introduit l’idée de “tolérance de panne” unique sans interruption du service jusqu’à ce qu’un second capteur échoue. Dans chaque cas, les données de chaque capteur ne sont pas fusionnées ou transformées de quelque façon, elles sont uniquement comparées par rapport à l’identité, ce qui permet de légères variations dans la production qui se fait entre des composants réels.

Bien que les capteurs soient dupliqués (a) ou triplés (b), la puce de vote ne l’est pas, et devient maintenant un danger de “point individuel de défaillance” (SPF). Ce problème peut être résolu en ajoutant une logique de vote redondante, mais avant d’exécuter cette tâche fastidieuse, il est intéressant de comparer les taux d’échec fournis par le fabricant du capteur et des puces de vote. Par exemple, Microchip fournit des statistiques de temps moyen entre pannes (MTTF) pour la plupart de leurs microcontrôleurs. Il est très probable que les capteurs, souvent soumis à des contraintes considérables lors d’un fonctionnement normal, auront beaucoup de valeurs plus petites de MTTF que les puces de vote. Lors du calcul du taux de défaillance du système, la contribution de la logique de vote peut souvent être réduite.
Le développement de la redondance du processeur
Dans un système de contrôle intégré, les données d’entrée du capteur seront traitées par une sorte d’algorithme s’exécutant sur un microcontrôleur qui produit des données de sortie pour les actionneurs de conduite et l’affichage. Ce microcontrôleur (MCU) représente un grave danger de point individuel de défaillance. Il sera nécessaire d’intégrer des circuits redondants lors d’une application critique pour la sécurité.
Les systèmes fly-by-wire bénéficiant de redondance existent depuis la fusée Saturn V des années 1960 et plus récemment dans les avions civils, en commençant avec l’Airbus A320 en 1988. Les systèmes redondants représentent un investissement supplémentaire très important, non seulement au niveau du matériel mais surtout en termes le temps de conception pour les ingénieurs afin que les circuits/logiciels soient efficaces pour atteindre l’objectif d’une mission réussie. Cet objectif s’applique à la fois aux missions habitées et inhabitées mais inclut l’hypothèse de sécurité lorsque les gens sont impliqués. L’exigence de la réussite de la mission n’a pas changé au fil des décennies, tout comme le concept de la redondance. Ce qui a changé est la condition de défaut plus probable, permanente ou temporaire, et le taux de panne probable pour chacun. Les puces modernes sont moins sujettes aux défauts graves qu’auparavant, mais leur technologie beaucoup plus dense est plus susceptible de connaître des bouleversements temporaires de particules parasites (cosmiques).
La TMR et la tolérance de panne
La TMR classique comporte trois processeurs identiques exécutant le même code, passant leurs données de sortie logique dans une logique de comparaison qui confirme que les trois processeurs produisent les mêmes résultats. Il s’agit du cas d’un fonctionnement sans erreurs (Fig.2). Si un processeur “fait une erreur”, la sortie peut être ignorée étant donné que les deux autres seront identiques et que leur sortie sera correcte suite à un “vote de majorité”. C’est ce qu’on appelle le masquage de problème car l’exploitation sûre et sans interruption est possible jusqu’à ce que les autres processeurs s’y opposent. Le système est dit tolérant aux pannes car un seul défaut permanent ou temporaire n’interrompra pas le flux de données de sortie. Ce système est idéal pour les applications de contrôle en temps réel. Toutefois, un tel système ne vous protègera pas nécessairement contre les défauts de conception dans les processeurs identiques, ou des bogues dans le code de programme identique exécuté sur chaque processeur.
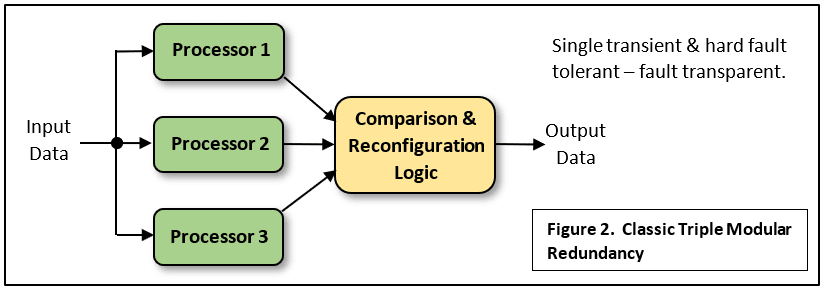
Chaque processeur peut recevoir les mêmes données d’entrée de capteurs simples non-redondants comme indiqué, bien qu’il soit conseillé d’utiliser également des capteurs redondants, comme dans la Fig.1. L’inconvénient de cette forme de TMR est la complexité de la logique du comparateur et les circuits nécessaires pour s’assurer que les données “correctes” sont appliquées à la sortie finale. Il se peut que les circuits de contrôle doivent être également triplés et ce n’est pas facile. Voici un article récent sur le sujet.
La DMR et la reprise après incident
La plupart des concepteurs de systèmes de sécurité pratiques contournent la complexité de la TMR à tolérance de panne par un compromis de configuration DMR avec reprise après incident. Les différents calculateurs de contrôle des surfaces de vol (ascenseurs, gouvernail, etc.) sur les avions Airbus A320 sont constitués de deux processeurs indépendants qui contre-vérifient les autres. Tout défaut entraîne un arrêt et un transfert de fonction à un autre ordinateur. Cinq de ces ordinateurs sont interconnectés ingénieusement pour commander des actionneurs redondants. Un défaut n’a aucun effet sur la performance des avions. Dans le cas de plus d’un défaut, la performance se dégrade jusqu’à ce qu’il reste un ordinateur qui maintient le contrôle des ascenseurs qui, avec le système de gouvernail redondant, permet à l’avion d’être dirigé et d’atterrir en toute sécurité. Pour plus d’informations détaillées sur le système de commande de vol redondant de l’A320, veuillez lire cette description technique.
Dissemblance
Le problème des ordinateurs identiques avec des logiciels identiques produisant des mauvaises réponses identiques a été résolu sur l’A320, en introduisant la notion de dissemblance. Trois des cinq ordinateurs sont basés sur une paire de microprocesseurs 16 bits Intel 80186 ; les deux autres contiennent des unités Motorola 68010 16/32bits. Des entrepreneurs différents conçoivent, construisent et programment chaque type : le seul point commun étant l’interface bus externe redondante et son protocole. La sécurité ne s’atteint pas avec de petits moyens.
Microcontrôleurs et “échelons”
Les progrès de la technologie à base de silicium ont permis d’obtenir des puces de processeur avec plus d’un “cœur” fournissant des augmentations importantes dans le rendement ou le débit. Les appareils multicoeurs ne contiennent pas de redondance, juste la capacité d’exécuter plusieurs programmes différents en parallèle. Aujourd’hui, le concept de machines fonctionnant de manière autonome semble devenir une réalité, par exemple avec des voitures sans conducteur et même des usines de fabrication. Naturellement, la sécurité est devenue un très gros enjeu. Heureusement, des normes ont été créées pour régir la conception et la certification en matière de sécurité des produits autonomes : la CEI 61508 pour le contrôle industriel général et l’ISO 26262 pour les applications automobiles. Les fabricants de puces ont réagi avec un nouveau type d’appareil : le microcontrôleur de sécurité. La plupart de ces nouveaux appareils sont basés sur le principe de DMR, mais avec une torsion. Les deux cœurs de processeur exécutent le même programme, mais avec un ou plusieurs cycles d’horloge en décalage les uns avec les autres (Fig.3). Les sorties sont ré-alignées pour la détection d’erreur.

Le délai fixe entre les deux processeurs garantit qu’un éventuel état temporaire affectant simultanément les deux noyaux ne passe pas inaperçu. On dit que les cœurs s’exécutent en “échelons”. Une redondance supplémentaire est également incluse pour faire face à des bits de mémoire inversés (codes correcteurs d’erreurs ou logique ECC) et des bits inversés sur les canaux de communication (code de redondance cyclique ou contrôle CRC). La logique auto-test intégrée (BIST) est également activée quand une incohérence de données de base est détectée. Elle gère la reprise après incident temporaire via une réinitialisation complète si aucun défaut permanent n’est détecté. Ce n’est pas tout : la puce est définie de manière à minimiser les erreurs communes aux deux cœurs. Certaines de ces mesures prises par Texas Instruments pour leur gamme TMS570 Hercules sont montrées dans la Fig.3. Ces mesures incluent l’organisation des deux noyaux à 90° les uns des autres avec une distance minimale de 100μm.
Comme autres exemples de microcontrôleurs de sécurité par échelon, on peut citer : AURIX d’Infineon, SPC5 de STMicro et S32S24 de NXP.
L’Intelligence Artificielle et les systèmes redondants
La redondance du processeur peut s’avérer utile pour surmonter un obstacle majeur à l’adoption de l’IA dans les systèmes où la sécurité est essentielle. Le problème est que l’apprentissage profond pour la reconnaissance de l’objet est soumis au biais involontaire, à moins que les images pour l’apprentissage aient été très soigneusement choisies. Vous pouvez imaginer les erreurs catastrophiques qui risqueraient d’être faites par le système de vision d’une voiture sans conducteur. Une solution possible est d’utiliser un système triplé où chaque “moteur d’inférence“ lancé sur la voiture fonctionne à partir d’un jeu de données différent créé à partir de différentes séries d’images. Il devrait y avoir une forte probabilité qu’au moins deux processeurs fonctionnent correctement en même temps !
Cercle plein
Ces dispositifs en échelon peuvent détecter un défaut temporaire du cœur, effectuer un test et récupérer le processeur à plein régime après une réinitialisation complète. Si vous avez besoin d’une tolérance de panne complète comme l’ordinateur de la fusée Saturn V, vous pouvez l’obtenir, grâce à l’Agence spatiale européenne. Ils ont sorti la série LEON de cœurs à tolérance de panne qui peuvent faire face à la plupart desperturbations par une particule isolée dues à des impacts de particules cosmiques, sans interruption de service.
La redondance va (sûrement) sauver des vies
Le récent crash du vol EA302 d’Ethiopian Airlines avec la dernière version de l’avion de Boeing 737 montre bien comment de petits changements dans la conception peuvent conduire à une catastrophe. Tous les avions modernes ont des systèmes de sécurité redondants, habituellement basés autour des pilotes “dupliqués” dans le cockpit. Les capteurs de vol dupliqués alimentent des calculateurs de commande de vol dupliqués et des écrans de chaque côté du cockpit. Une contre-vérification a lieu entre les ordinateurs pour confirmer les données du capteur valide et pour une dernière sauvegarde, l’ensemble des pilotes peut comparer les paramètres. Le problème avec le nouveau 737 Max c’est qu’un système supplémentaire appelé MCAS a été ajouté pour fournir des avertissements supplémentaires d’un décrochage possible lorsque toute la puissance du moteur a été appliquée pendant le décollage. Le nez a tendance à “cabrer”, comme une moto. Le 737 Max avait besoin de ce système d’avertissement parce que ses plus grands moteurs fixés plus haut et plus en avant ont eu un impact négatif sur l’aérodynamique de la conception originale.
Le nouveau système d’avertissement ne surveillait qu’un des deux capteurs d’angle d’attaque : une grave erreur compte tenu de leur ancien format de “girouette” mécanique qui était connu pour être peu fiable. Sur le vol 302, l’angle d’attaque surveillé est soudainement resté bloqué à un angle que le nouveau système MCAS pouvait seulement interpréter comme un violent tangage du nez. Si l’autre angle d’attaque redondant avait été connecté, un avertissement de désaccord de l’angle d’attaque aurait retenti et les pilotes auraient pu alors désactiver le MCAS. En effet, un système redondant bien conçu aurait pu aussi utiliser l’information des capteurs du tube de Pitot et des accéléromètres comme vérification. Sans redondance, le capteur défectueux a amené le MCAS à penser qu’un décrochage était imminent et à pousser le manche pilote vers l’avant. Une autre erreur de conception fatale a été de supposer que toute condition de décrochage serait due à une erreur du pilote : le MCAS a forcé le manche vers l’avant et le pilote n’a pas eu la force de le tirer en arrière. L’avertissement de désaccord de l’angle d’attaque pourrait avoir été installé par le constructeur, comme une “option”. Dans ce cas, une meilleure redondance de la machine aurait pu sauver la mise. Rendre les pilotes humains “redondants” a abouti à un désastre.