When Redundancy is a Good Thing
Follow article
 Dave from DesignSpark
Dave from DesignSpark
How do you feel about this article? Help us to provide better content for you.
Dave from DesignSpark
Thank you! Your feedback has been received.
Dave from DesignSpark
There was a problem submitting your feedback, please try again later.
Dave from DesignSpark
What do you think of this article?

The technique of duplex, triplex or even quadruplex redundancy of critical circuits to increase reliability has been around a long time. Naturally, the first systems so designed were for military aerospace applications because redundancy was expensive. It enabled aircraft to be flown safely by a computer, a technique called ‘fly-by-wire’, increasing the aircraft’s performance way beyond the capability of a human pilot. The Apollo Saturn V rocket guidance computer of the 1960s featured triplex redundancy which probably accounts for its incredible reliability in the extreme conditions of a launch. The use of duplicate or triplicate identical circuit modules for the purpose of preventing unsafe operation is called Double Modular Redundancy (DMR) or Triple Modular Redundancy (TMR).
Sensor Redundancy
We can see the basics of sensor DMR and TMR operation in Fig.1. Most modern chip sensors have serial digital outputs (e.g. UART, SPI or I²C bus), so the voting logic device which compares the data from each is likely to be a small, low-power microcontroller. Modular redundancy is a sensor fusion technique with the single aim of improving system reliability. In DMR form it can detect a critical failure and allows a controlled shutdown of the system. In other words, it improves the probability of a ‘Fail-Safe’ scenario. TMR introduces the idea of single ’Fault Tolerance’ with no disruption of service until a second sensor fails. In each case, the data from each sensor is not merged or processed in any way, just compared for identity, allowing for the slight variations in output that occur between real components.

While the sensors are duplicated (a) or triplicated (b), the voting chip is not, and it now becomes a ‘Single Point of Failure’ hazard (SPF). This problem may be tackled by adding redundant voting logic, but before going through all that hassle, it’s worth comparing the manufacturer-supplied failure rates of the sensor and voting chips. For example, Microchip provides Mean-Time-To-Fail (MTTF) statistics for most of their microcontrollers. It’s highly likely that the sensors, often subjected to high degrees of stress in normal operation, will have much smaller values for MTTF than the voting chip. When calculating the system failure rate, the voting logic’s contribution may often be discounted.
The Development of Processor Redundancy
In an embedded control system, sensor input data will be processed by some sort of algorithm running on a microcontroller which produces output data for driving actuators and displays. That microcontroller (MCU) is a serious SPF hazard and will need redundant circuits to be incorporated when it’s used in a safety-critical application.
Fly-by-Wire systems featuring redundancy have been around since the Saturn V rocket of the 1960s and more recently in civilian airliners, starting with the Airbus A320 in 1988. Redundant systems represent a very significant extra investment, not only in physical hardware but more importantly in the engineers’ time designing the circuits/software to be effective in achieving the goal of a successfully completed mission. That goal applies to both manned and unmanned missions but includes the assumption of safety where people are involved. The requirement for mission success hasn’t changed over the decades, neither has the concept of redundancy. What has changed is the most likely fault condition, hard or transient, and the likely failure rate for each. Modern chips are less prone to hard faults than before, but their much denser technology is more likely to temporary upsets from stray (cosmic) particles.
TMR and Fault Tolerance
Classic TMR involves triplicate identical processors running the same code, passing their output data through comparator logic that confirms that all three are producing the same results. That is, running normally without errors (Fig.2). Should one processor ‘make a mistake’, it’s output can be ignored as the other two will be in agreement and their output passed on as correct by a ‘majority vote’. This is called fault masking because continued safe operation without interruption is possible until the remaining processors disagree. The system is said to be Fault Tolerant because a single transient or hard fault will not interrupt the flow of output data. It’s ideal for real-time control applications. However, such a system won’t necessarily protect you from design defects in the identical processors, or bugs in the identical program code running on each.
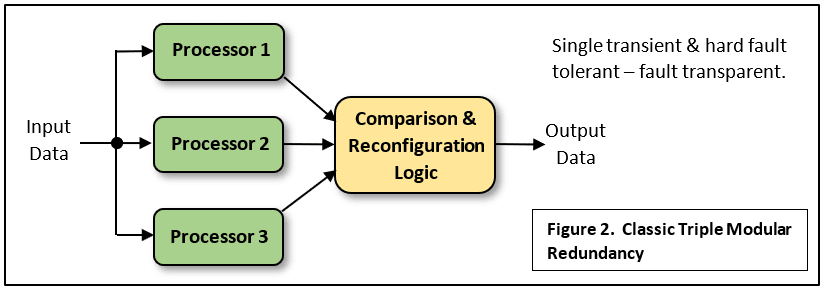
Each processor could receive the same input data from single, non-redundant sensors as shown, although a better idea is to use redundant sensors too, as in Fig.1. The drawback to this form of TMR is the complexity of the comparator logic and the circuits needed to ensure that the ‘correct’ data is applied to the final output. It may be that the checking circuits must be triplicated too and that’s not easy. Here is a recent paper on the subject.
DMR and Fault Recovery
Most practical safety system designers get around the complexity of fault-tolerant TMR by compromising with a Fault Recoverable DMR configuration. The various computers controlling flight surfaces (elevators, rudder, etc.) on the Airbus A320 airliner each consists of two independent processors that cross-check each other. Any fault brings about a shutdown and a transfer of function to another computer. There are five of these computers ingeniously interconnected driving redundant actuators. One failure has no effect on aircraft performance. If more fail, performance degrades until one remains, retaining elevator control which together with the redundant rudder system allows the plane to be steered and landed safely. For more detailed information on the A320 redundant flight control system, read this technical description.
Dissimilarity
The problem of identical computers with identical software producing identical wrong answers is addressed on the A320 by introducing the concept of dissimilarity. Three of the five computers are each based on a pair Intel 80186 16bit microprocessors; the other two contain Motorola 68010 16/32bit units. Separate contractors design, build and program each type: the only commonality being the redundant external bus interface and its protocol. Safety does not come cheap.
Safety Microcontrollers and ’Lockstep’
Advances in silicon technology have led to processor chips with more than one ‘core’ providing big increases in performance or throughput. Multi-core devices contain no redundancy, just the capacity to run multiple different programs truly in parallel. Today, the concept of machines running autonomously looks like becoming a reality, for example with driverless cars and even whole manufacturing plants. Naturally, safety has become a very big issue. Fortunately, standards have been created governing the design and safety certification of autonomous products: IEC 61508 for general industrial control and ISO 26262 for automotive applications. Chip manufacturers have responded with a new class of device: the safety microcontroller. Most of these new devices are based on the DMR principle, but with an extra twist. The two processor cores run the same program, but one or more clock cycles out of step with each other (Fig.3). The outputs are re-aligned for the purpose of error detection.

The fixed delay between the two processors ensures that some transient condition affecting both cores simultaneously does not go undetected. The cores are said to be operating in ‘Lockstep’. Further redundancy is included to deal with flipped memory bits (Error Correcting Codes or ECC logic) and flipped bits on communications channels (Cyclic Redundancy Code or CRC checking). Then there is Built-In Self-Test (BIST) logic which is activated whenever a core data mismatch is detected. This provides for transient fault recovery via a full reset if no hard fault is found. That’s not all: the chip is laid out to minimize errors common to both cores. Some of these measures taken by Texas Instruments for their Hercules TMS570 range are shown in Fig.3. These include arranging the two cores at 90° to each other with a minimum separation of 100μm.
Other examples of lockstep safety microcontrollers include AURIX from Infineon, SPC5 from STMicro and S32S24 from NXP.
Artificial Intelligence and Redundant Systems
Processor redundancy may prove useful in overcoming a major obstacle to the adoption of AI in safety-critical systems. The problem is that Deep Learning for object recognition is subject to inadvertent bias unless the ‘teaching’ images are very carefully chosen. You can imagine how this could cause catastrophic mistakes to be made by the vision system of a driverless car. A possible solution is to use a triplicated system where each ‘inference engine’ running on the car works from a different dataset created from different image sets. There should be a high probability that at least two processors get it right at the same time!
Full circle
These lockstep devices can detect a transient core fault, carry out a test and recover the processor to full operation after a full reset. If you need full fault tolerance like the Saturn V rocket computer then you can have it, thanks to the European Space Agency. They originated the LEON series of fault-tolerant cores which can deal with most Single-Event Upsets due to cosmic particle impacts, with no interruption of service.
Redundancy (should) save lives
The recent crash of Ethiopian Airlines flight EA302 involving the latest version of the Boeing 737 airliner highlights how small changes in design can lead to a catastrophe. All modern airliners have extensive redundant safety systems, usually based around the ‘duplicated’ pilots in the cockpit. Duplicated flight sensors feed duplicated flight control computers and displays on each side of the cockpit. Cross-checking takes place between the computers to confirm valid sensor data and as a final back-up, the human pilots can lean across to compare each other’s readouts. The problem with the new 737 Max was that an additional system called MCAS was added to provide additional warning of a possible stall condition when full engine power was applied during take-off. The nose tends to ‘rear-up’ just like a motorcycle performing a ‘wheelie’. The 737 Max needed this warning system because its bigger engines mounted higher up and further forward had a negative impact on the original design’s aerodynamics.
The new warning system only monitored one of the two Angle-of-Attack (AOA) sensors – a serious error given their ancient mechanical ‘weather-vane’ format was known to be unreliable. On flight 302 the monitored AOA suddenly stuck at an angle which the new MCAS system could only interpret as a violent pitch-up of the nose. If the other redundant AOA had been connected, an AOA disagree warning would have sounded and the pilots could then have disabled the MCAS. Indeed, a properly designed redundant system could also have used information from the pitot tube sensors and accelerometers as a sanity-check. With no redundancy the faulty sensor caused MCAS to think a stall was imminent and it pushed the pilot’s control column right forward. Another fatal design flaw was to assume that any stall condition would be due to pilot-error: MCAS forced the stick forward and the pilot did not have the strength to pull it back. The AOA disagree warning could have been fitted by the manufacturer - as an ‘optional extra’. In this case, more machine redundancy might have saved the day. Making the human pilots effectively ‘redundant’ led to disaster.
If you're stuck for something to do, follow my posts on Twitter. I link to interesting articles on new electronics and related technologies, retweeting posts I spot about robots, space exploration and other issues.