Quand l’automatisation classique rencontre le monde étranger de l’informatique
Suivez l'article
 Dave from DesignSpark
Dave from DesignSpark
Que pensez-vous de cet article ? Aidez-nous à vous fournir un meilleur contenu.
Dave from DesignSpark
Merci! Vos commentaires ont été reçus.
Dave from DesignSpark
There was a problem submitting your feedback, please try again later.
Dave from DesignSpark
Que pensez-vous de cet article ?

Lorsque je me suis mis à l'informatique dans les années 70, il était naturel de comprendre la composition d’un processeur. Je devais taper chaque octet et son adresse RAM avec un clavier hexadécimal.
Après avoir rempli un ko de RAM, il valait mieux en contrôler le contenu en lisant l’affichage à 7 segments une deuxième fois avant d'appuyer sur le bouton "Exécuter". Connecter des commutateurs et des voyants lumineux était la manière normale de laisser les "utilisateurs" interagir avec votre logiciel. On faisait beaucoup d'’’informatique physique". Plus tard à l'université, j'ai appris à utiliser FORTRAN pour effectuer des calculs. Je n'avais même pas le droit de toucher à l'ordinateur. Il fallait percer des trous dans des fiches de carton (appelées "cartes perforées") et laisser un "opérateur" insérer ces fiches dans l'ordinateur, qui était en fait une salle remplie de tours de 19 pouces. Le lendemain, on récupérait les résultats du calcul, sous forme imprimée ou sur des fiches perforées. Depuis cette époque, je voyage entre le monde de l’informatique physique et celui des technologies de l’information classique. Il s'agit d'univers spécialisés très différents l'un de l'autre. Très souvent, les experts de l'un ne comprennent pas ce dont parlent les experts de l'autre, ou pourquoi ils voient des difficultés dans des problèmes qui n'existent pas dans leur propre monde.
Naturellement, les outils et les règles de ces deux mondes ont historiquement été établis séparément pour correspondre à leurs objectifs spécifiques. Il semble maintenant que cela constitue l'un des principaux obstacles au développement rapide de l’IoT industriel ("internet des objets"). Dans cette série d'articles, je vais tenter d'expliquer certaines de ces différences fondamentales. Je vais essayer de présenter clairement pourquoi sécurité et sûreté se sont rarement rencontrées dans l’industrie de l’automatisation avant l’Industrie 4.0 ou pourquoi l’exécution cyclique d’une machine d'état n’est pas la meilleure architecture pour les systèmes d'exploitation tels que MS Windows. Ou peut-être êtes-vous un expert en informatique qui souhaite comprendre ce qui rend l’architecture d’un PLC ("contrôleur à logique programmable") si unique. Poursuivez votre lecture...
Part 1
Architectures systèmes déterministes et probabilistes.
Dans l’industrie de l'automatisation, les "choses" sont le domaine des ingénieurs classiques. Ils conçoivent des systèmes embarqués ou programment des contrôleurs à logique programmable pour contrôler les machines complexes impliquées dans les processus de production. Leur architecture système vise à maximiser la fiabilité et utilise souvent une réduction maximale. Les choses doivent accomplir les mêmes tâches de manière répétée et fiable, sans intervention humaine. Les interfaces homme-machine permettent une surveillance humaine et l'adaptation des valeurs de processus mais ne forment pas une partie centrale de l'algorithme de commande. Je vais tenter de présenter de façon simple le développement de ce type d’architecture.

Image 1 : circuit logique simple. La LED s'allume si les deux boutons sont enfoncés.
A ses débuts, l'informatique physique reposait sur une combinaison de portes logiques binaires. Comme dans l’image 1, on peut voir deux commutateurs (il pourrait par exemple s'agir de capteurs binaires tels que des barrières lumineuses). Si les deux sont fermés, un voyant s’allume en sortie. Imaginez maintenant comment il serait possible de suivre une séquence de commutation par ces portes logiques. Le résultat : une "logique synchrone" qui fonctionne par cycles (image 2).
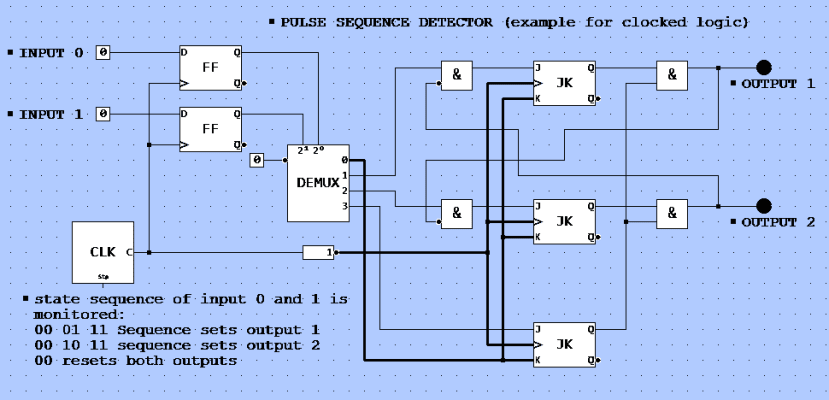
Image 2 : Exemple de logique synchrone. Vous pouvez simuler la logique en suivant ce lien :http://simulator.io/board/Yc9tpDmfyO/3
Un PLC fonctionne comme une logique synchrone. Un ensemble de portes peut être connecté (sortie vers entrées) grâce au programme du PLC pour donner de la flexibilité à ce contrôleur (dans les premiers PLC, on trouvait un ensemble de blocs logiques - d’où le nom - alors qu'aujourd'hui c’est un processeur qui effectue cette tâche). Le cœur a toujours un fonctionnement cyclique : obtention d’un instantané de toutes les entrées, calcul des opérations binaires sur les entrées, configuration de toutes les sorties. Ainsi, les opérations logiques dépendent des entrées et définissent les "états internes" (en mémoire tampon dans des circuits logiques appelés "Flip-Flops") qui doivent tous être bufferisés dans une sorte de "cliché-tampon" ("latch") avant que le PLC n'exécute des calculs binaires. Les résultats sont à nouveau mis en mémoire tampon avant de faire basculer toutes les sorties simultanément (image 3). Cette mise en mémoire tampon de "l'image de processus" est essentielle pour éviter toute interprétation erronée.
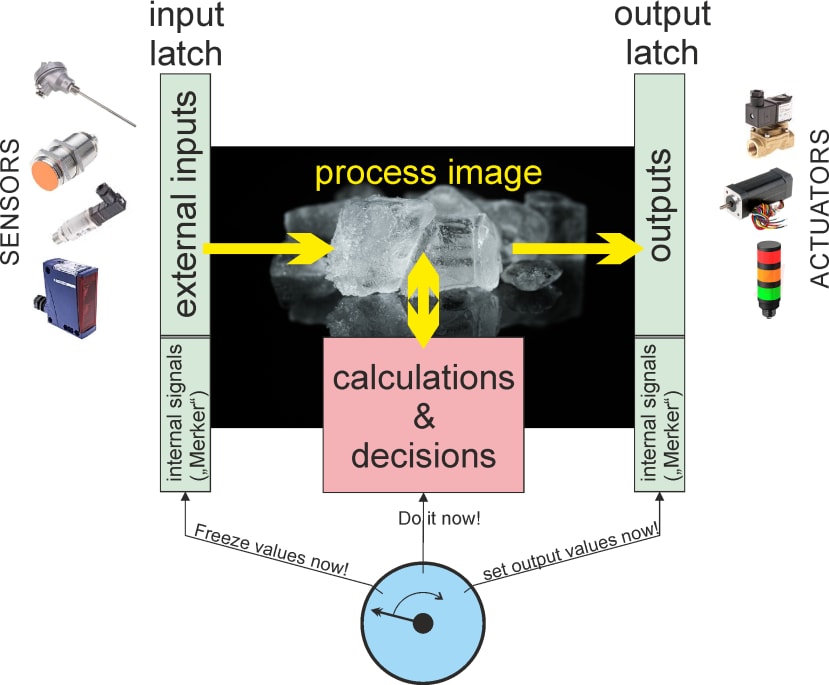
Image 3 : fonctionnement cyclique d'un PLC à l'aide d'une "image de processus".
Toute séquence a besoin d'une horloge pour détecter l'avant et l'après, mais temporiser un signal (entrée) signifie "l’échantillonner". La fréquence d'horloge s'avère être un taux d'échantillonnage, et comme Nyquist en fait la démonstration mathématique, il est possible de détecter de manière fiable un signal qui n’est pas plus court que le double du taux d’échantillonnage. Prenons l'exemple de l’image 2 : si un objet traverse les deux faisceaux lumineux, cela a toujours pour résultat une séquence "00 - 01 - 11 - 10 - 00" ou "00 - 10 - 11 - 01 - 00" suivant la direction de la transition. La période d'horloge doit être plus courte que la moitié du temps entre deux des états pour détecter une séquence de ce type. L'échantillonnage des barrières lumineuses à des moments différents rendrait la détection très compliquée voire impossible. Pour calculer la fréquence d’horloge minimum, il faut se baser sur des signaux échantillonnés simultanément.
Nyquist for dummies
C'est C.E. Shannon qui a introduit le terme "fréquence de Nyquist" dans la théorie du signal lors de ses travaux sur les "systèmes horaires discrets"- ne vous inquiétez pas, c'est plus simple qu'il n'y paraît. Etudions un signal numérique pour mieux comprendre :
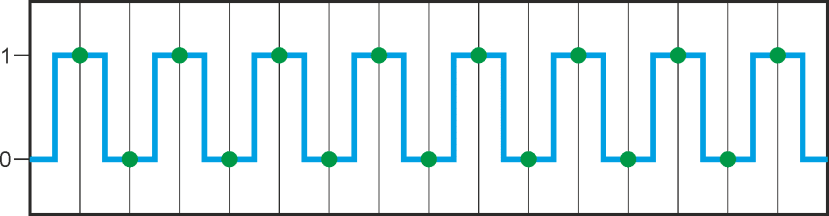
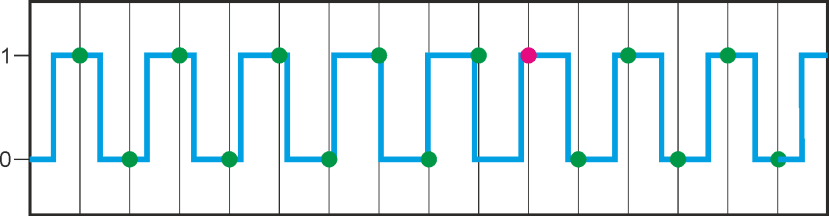
Supposons que nous avons une onde carrée qui bascule entre les deux valeurs numériques "0" et "1". Votre machine ne peut pas surveiller en permanence ce signal, mais doit relever cycliquement la valeur réelle (c’est à dire "l’échantillonner"). Si vous regardez la chronologie du signal et les "points d’échantillonnage", vous comprendrez qu'il faut échantillonner au moins deux fois par période d'onde carrée pour détecter de façon fiable les deux états de l'onde carrée. La "fréquence d’échantillonnage" (parfois aussi appelée "taux d’échantillonnage") doit donc être deux fois plus élevée que la fréquence du signal.
En d'autres termes : la plus haute fréquence du signal qui peut être traitée de manière fiable est ½ de la fréquence d'échantillonnage. Cette fréquence du signal la plus élevée admise comme entrée dans votre système est appelée la "fréquence de Nyquist".
Fréquence du signal tout juste correcte :
Fréquence du signal trop élevée = > "crénelage du signal "(point rouge) :
Ce concept d'échantillonnage séquentiel d'une image de processus, les calculs sur les valeurs d'entrée en mémoire tampon et les résultats de mise en mémoire tampon jusqu'à la fin du calcul avant la commutation simultanée des sorties sont essentiels pour un système hautement prévisible. Ce concept a été adopté par la suite par les contrôleurs embarqués utilisant des automates finis (FSM). Chaque cycle d’automate fini commence avec un état défini et peut se terminer par une transition dans un état différent selon les états du signal. Il est possible de réduire le concept de ces contrôleurs à une tâche simple : "commuter cycliquement les états (et les sorties) en fonction de l’entrée et des états internes". Un tel contrôleur fonctionne de manière complètement prévisible et fiable ("déterministe") car vous devez connaître chaque état possible lors de la conception, ainsi que les règles de transition de l'état.
EN 61131 est une des normes centrales s'appliquant à cette architecture ; elle a été développée pour définir le comportement des contrôleurs dans l'industrie de l'automatisation. Elle définit également les langages de programmation tels que le diagramme échelle ou Ladder Diagram (LD), le diagramme de blocs fonctionnels ou Function Block Diagram (FBD), le diagramme de fonctions séquentielles ou Sequential Function Chart (SFC) ou encore les listes d'instructions ou Instruction List (IL), qui reflètent les racines électroniques historiques de la technologie PLC (p. ex. un "relais" ou ladder est très proche du schéma de connexion d'une logique numérique).
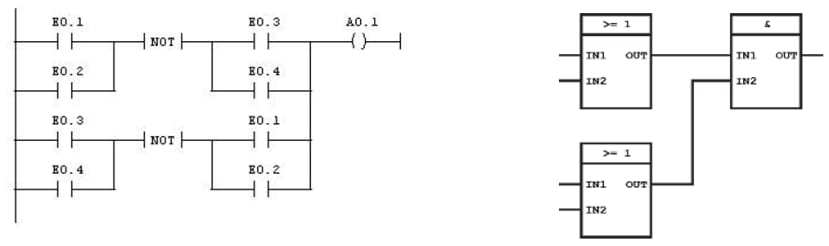
Image 4 : Exemples de programmes de PLC en LD (à gauche) et FDB (à droite).
Connecter de telles "choses" au cloud implique de pénétrer dans un autre monde, avec des règles et des objectifs différents : celui de l'informatique classique. On trouve souvent une séparation entre le "back-end" (avec des bases de données pour stocker et récupérer efficacement des masses de données) et le front-end (principalement les applications sur PC avec une interface graphique très interactive). On peut même dire que l’interaction humaine avec les données est la base de l’informatique classique, tandis que l'interaction capteur-actionneur relève du domaine des contrôleurs dans le domaine de l'automatisation. Par conséquent, l'architecture système des technologies de l’information est souvent optimisée pour un maximum d'efficacité, de réutilisation, de convivialité et de confort. Les interfaces utilisateur intuitives (UI), les langages de programmation basés sur des objets et les systèmes d'exploitation multi-tâches correspondent bien à ces objectifs.
Un logiciel d'exploitation cyclique serait un gaspillage des ressources. Les systèmes informatiques utilisent souvent un concept basé sur un événement : l'utilisateur clique sur un bouton virtuel qui déclenche un "événement" à l'intérieur du logiciel. Cet événement déclenche tous les processus qui y sont liés. Les processus en arrière-plan (souvent appelés "démons") surveillent en permanence la souris pour détecter un clic ou effectuer d'autres tâches. Ces démons travaillent indépendamment et de manière asynchrone. D'autres processus peuvent s'abonner pour recevoir des messages lorsque certains événements se produisent. Les processus d’arrière-plan offrent donc des "services". Ces processus fournissent leurs services aux processus clients.
Alors que dans le domaine de l'automatisation, un automate demanderait cycliquement au commutateur s’il est fermé, un système d'exploitation comme Linux organise un scénario du type suivant : le service clavier envoie un message dès qu'une touche est enfoncée. Toute application qui a souscrit à ce message le reçoit rapidement et peut réagir ou non. La communication entre un service et un client est généralement basée sur des événements et des messages. Elle utilise des interfaces bien définies qui constituent le seul lien entre ces deux éléments. Le reste constitue un service et les processus clients peuvent s'exécuter sur différents systèmes, et c’est souvent le cas (p. ex. les systèmes « back-end" et "front-end"). Ces structures serveur-client permettent facilement la mise en place d'une architecture hautement évolutive et distribuée. Un prestataire moderne de cloud tel qu'AWS fournit plus de mille services, et des millions de clients peuvent les utiliser simultanément sur internet.
Ce type d'architecture est tout sauf un "état fini" : travailler avec de nombreux processus asynchrones et indépendants produit un système moins prévisible. La quantité d'états possibles est généralement trop élevée pour qu’ils soient entièrement connus et pris en considération au moment de la conception. D'un autre côté, en raison de leur évolutivité et des principes de conception orientés objet, ces systèmes sont quasiment illimités lorsqu'il s'agit de travailler avec des données en masse. Ils nous ressemblent à bien des égards : multi-tâches, hautement interactifs, ouverts à la communication et adaptatifs en termes de fiabilité et de vitesse. Il n’est donc pas étonnant que les technologies de l'information soient prédestinées à interagir avec les humains (interface graphique) ni que la communication entre les systèmes soit plus "sociale" (nous aborderons cela dans la partie 2). Il n'est pas surprenant non plus que le "calcul probabiliste" (qui utilise des méthodes statistiques pour la prise de décision) permette l'apprentissage automatique et l'IA (intelligence artificielle).
Image. 5 : IIoT - quand l’automatisation rencontre l’informatique
Si les automaticiens veulent joindre leur univers déterministe à ce fantastique nouvel univers probabiliste, ils doivent comprendre qu'il est basé sur ces qualités "humaines". D’un autre côté, la connexion du cloud à des machines dans le monde réel introduit de nouveaux risques et les ingénieurs informaticiens doivent donc comprendre les bases d'un fonctionnement fiable de l'automatisation.
Prochainement
La partie 2 compare les bus de terrain aux les protocoles Internet, la partie 3 traite de la sécurité, et la dernière partie aborde l'opensource et la protection de la propriété intellectuelle.