在NVIDIA Jetson nano 上执行深度学习范例:影像辨识、物件侦测、影像分割
この記事を購読
 Dave from DesignSpark
Dave from DesignSpark
こちらの記事について、内容・翻訳・視点・長さなど、皆様のご意見をお送りください。今後の記事製作の参考にしたいと思います。
Dave from DesignSpark
Thank you! Your feedback has been received.
Dave from DesignSpark
There was a problem submitting your feedback, please try again later.
Dave from DesignSpark
こちらの記事の感想をお聞かせください。
| 作者 | 郭俊廷/蔡雨錡 |
| 難度 | 中等 |
| 所需時間 | 2小時 |
一、深度学习介绍
深度学习是机器学习的一种,机器学习是让机器可以自我学习,透过将数据处理让机器有人工智能。而深度学习就是是机器学习的一种方式,它可以让计算机像神经网络一样,进行复杂的运算,运用各种算法运算呈现出像人一样的判断或行为,例如之前很红的AlphaGo打败围棋冠军、照片人脸侦测标记等等应用都是深度学习的应用。
以下就是我们使用Jetson nano执行jetson-inference范例的画面截图

二、jetson-inference相关软件安装
我们使用NVIDIA提供的jetson-inference范例,其中包含了影像辨识 (Image Recognition)、物件侦测 (Object Detection)、以及影像分割 (Segmentation)。它是使用TensorRT来将神经网络部属到Jetson nano上。jetson-inference它可以使用C++ 或 Python来跑我们的范例,以下我们都使用Python来介绍。

我们使用之前文章所使用的官方提供的映像文件来安装此jetson-inference范例的相关软件。
我们使用之前介绍过的MobaXterm来远程联机安装相关软件
Step1 输入以下指令取得远程更新服务器的套件档案列表(此指令需要输入用户密码请输入你设定的密码,如果是按照之前教学皆设定为jetsonnano)
sudo apt-get update
Step2 输入以下指令安装git、cmake套件、Python 3.6开发包(如果已经安装过会显示已安装)。
sudo apt-get install git cmake libpython3-dev python3-numpy
Step3 使用git下载jetson-inference项目程序
git clone --recursive https://github.com/dusty-nv/jetson-inference
Step4 移动到jetson-inference文件夹
cd jetson-inferenceStep5 创建build文件夹并移动到该文件夹
mkdir build
cd build

Step6 接着使用CMake来准备编译所需的相依套件
cmake ../编译到一半时会问你要下载甚么模型,以下是TensorRT有支持的模型,如果选择全部档案下载需要一些时间,可以根据你需要的模型选择下载或是使用下面默认的模型来下载。

选择需要下载的模型

下载的过程
下载完模型后会询问另外一个是否下载Python的PyTorch软件包,这里我们选择安装Python 3.6的PyTorch软件包版本。

Step7 使用make编译程序代码
make -j$(nproc)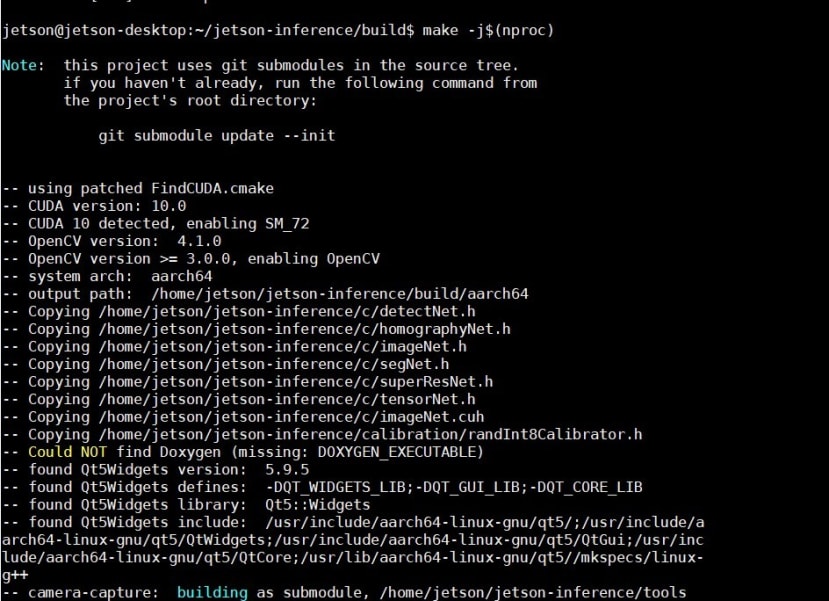
编译中

编译完成
Step8 执行sudo make install
最后完整的输出档案将会在 jetson-inference/build/aarch64 这个文件夹中, 接下来所有要执行的范例程序都存放在 jetson-inference/build/aarch64/bin 文件夹中。

安裝中

安装成功时可以看到bin底下有要执行的范例程序
三、影像辨识 (Image Recognition)
范例分成可以应用在静态影像上(Images)或是摄影镜头的串流影像上(Camera)的辨识。
Step1 我们先将工作目录移到以下范例文件夹中
cd ~/jetson-inference/build/aarch64/bin首先来辨识静态影像上的范例程序:imagenet-console.py
Step2 呼叫影像辨识范例来辨识NVIDIA提供的影像
NVIDIA提供的影像默认路径是jetson-inference/data/images/
可以看到下面有很多图片可以供你测试使用,也可以使用自己的图片来测试,以下我们使用black_bear.jpg来测试

NVIDIA提供的影像默认路径
下指令呼叫静态影像辨识程序时格式如下:(影像默认路径如上图)
./imagenet-console 要辨识的影像路径及文件名 辨识影像结果的路径及文件名
执行以下指令来辨识范例中黑熊的图片black_bear.jpg, 然后将辨识完的结果储存为 black_bear_ima.jpg。(辨识完的结果图片储存的目录默认在jetson-inference/build/aarch64/bin里面)
./imagenet-console black_bear.jpg black_bear_ima.jpg第一次跑的时候,需要等待几分钟,因为TensorRT会花上些许的时间来优化这个网络,之后再次执行程序就会快很多。
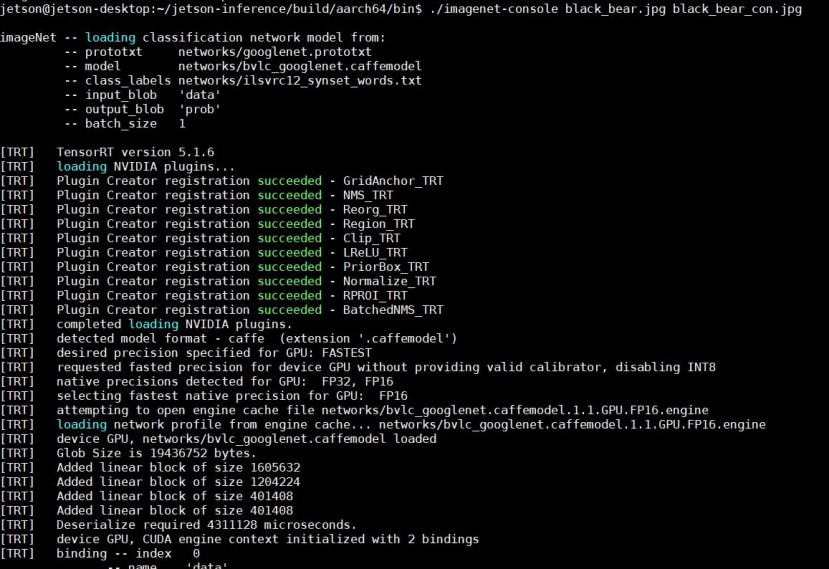


原图

辨识结果98%为美洲黑熊、黑熊
Step3 接着是摄影镜头的串流影像上(Camera)的辨识(注意这使用摄影机时的操作画面需要在Jetson nano上接屏幕才可以看到镜头的画面远程联机操作时则无法显示镜头的画面)
在本篇文章中统一使用Logitech 的C270 的USB Camera,所以需要将ca里mera指定为 /dev/video0, 也就是一般USB Camera的默认位置。
执行以下指令来让我们USB摄影机串流影像实时辨识
./imagenet-camera --camera /dev/video0执行后的结果拿取手边可得的东西来辨识,可以发现辨识成功。



四、对象侦测 (Object Detection)
下指令呼叫静态对象侦测程序时格式如下:
范例分成可以应用在静态影像上(Images)或是摄影镜头的串流影像上(Camera)的侦测。
Step1 我们先将工作目录移到以下范例文件夹中
cd ~/jetson-inference/build/aarch64/binStep2 呼叫对象侦测范例来侦测NVIDIA提供的影像
下指令呼叫静态对象侦测程序时格式如下:(影像默认路径跟默认储存目录同上)
./detectnet-console 要侦测的影像路径及文件名 侦测影像结果的路径及文件名
执行以下指令来侦测范例中飞机的图片airplane_0.jpg, 然后将侦测完的结果储存为 airplane_0det.jpg。(侦测完的结果图片储存的目录默认在jetson-inference/build/aarch64/bin里面)
./detectnet-console airplane_0.jpg airplane_0det.jpg使用范例图片airplane_0.jpg的侦测结果如下,可以看到侦测出飞机这个对象并把它框起来
Step3 接着是摄影镜头的串流影像上(Camera)的对象侦测
执行以下指令来让我们USB摄影机串流影像进行对象侦测可以看到以下结果
./detectnet-camera --camera /dev/video0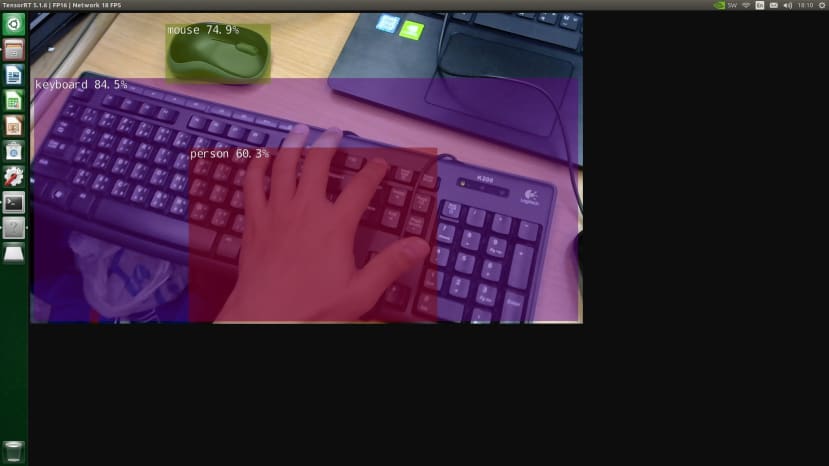
侦测结果可以看到有侦测到键盘、鼠标还有手(人类)
五、影像分割 (Segmentation)
下指令呼叫静态影像分割程序时格式如下:
范例分成可以应用在静态影像上(Images)或是摄影镜头的串流影像上(Camera)的影像分割。
Step1 我们先将工作目录移到以下范例文件夹中
cd ~/jetson-inference/build/aarch64/binStep2 呼叫影像分割范例来侦测NVIDIA提供的影像
下指令呼叫静态对象影像分割程序时格式如下:(影像默认路径如上)
./segnet-console 要分割的影像路径及文件名 影像分割结果的路径及文件名
执行以下指令来分割范例中马的图片horse_0.jpg,然后将分割完的结果储存为 horse_0seg.jpg。(分割完的结果图片储存的目录默认在jetson-inference/build/aarch64/bin里面)
./segnet-console horse_0.jpg horse_0seg.jpg
可以看到有分割成马跟人两种颜色
每种颜色所代表的对象如下图

Step3 接着是摄影镜头的串流影像上(Camera)的影像分割
执行以下指令来让我们USB摄影机串流影像进行影像分割可以看到以下结果
./segnet-camera --camera /dev/video0
分割后看到黄色的是狗 粉红色的是猫
以上就是我们的在Jetson nano上执行Deep Learning深度学习范例的介绍与教学,大家有没有成功的执行影像辨识、对象侦测 、以及影像分割三种范例呢?未来我们将会推出更多丰富的内容,有兴趣欢迎关注我们!