利用Jetson Nano、Google Colab实作CycleGAN:将拍下来的照片、影片转换成(伪)梵谷风格 – 基础建构篇
Suivez l'article
 Dave from DesignSpark
Dave from DesignSpark
Que pensez-vous de cet article ? Aidez-nous à vous fournir un meilleur contenu.
Dave from DesignSpark
Merci! Vos commentaires ont été reçus.
Dave from DesignSpark
There was a problem submitting your feedback, please try again later.
Dave from DesignSpark
Que pensez-vous de cet article ?

|
作者 |
张嘉钧 |
|
难度 |
难 |
|
材料表 |
|
CycleGAN
在 pix2pix 的时候你可以发现数据都是成对的,所以在早期的风格转换的案例中不仅仅是需要大量的数据,每一组数据都还必须是成双成对!但现实中其实搜集数据非常的费时以及困难,所以在pix2pix发表 (2016年11月) 过后没多久便研发出不对称的训练方式,而这种训练方式就是cycleGAN ( 2017年3月 )。
在CycleGAN图片案例中,可以将真实图片转换成梵谷风格图片,按照一般的GAN来思考,鉴别器只需要判断生成是否真实、风格是否正确即可,但是仔细想想,不对称的训练会有一个问题,如果当我现在输入任意一张真实图片都变成了某一张特定的梵谷风格图片,那神经网络分辨得出来吗?
举例来说,我输入一张城堡的真实图片,神经网络输出给我一张梵谷的人像画;按照神经网络的逻辑梵谷的人像画,图片风格也是梵谷风,所以计算机觉得「我生成的很真实!!!」因为成像真实、风格也是梵谷风格的。
为了避免这种问题,CycleGAN提出一个Reconstruction的概念:Reconstruction顾名思义就是重构的意思,我们将A风格图片转成B风格之后再将其转换回A风格,检查是否能成功转回原始图像。我们直接来看看概念图,CycleGAN包含三个重点:
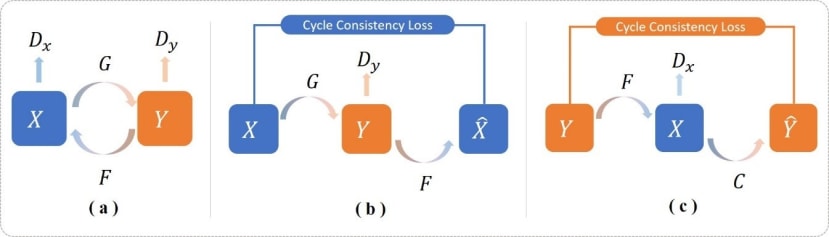
(a) 是基本的生成对抗架构,但CycleGAN总共有两个鉴别器 ( , )、两个生成器 ( ),代表有两组GAN,其中 负责判断 x 风格的图片是否真实, 则是判断 风格的图片是否真实;G负责将 风格转换成 风格,F则是将 转成 。
(b) (c) 为重构的部分,分别称为 forward cycle-consistency loss、backward cycle-consistency loss,将 转换成 风格之后在将其转换回原本风格 ( ),反之亦然。
Google Colaboratory
大致了解之后,先来简单介绍一下Google Colaboratory (简称Colab),它是Google出的一个深度学习平台,基础的深度学习框架及套件都帮你安装好,而且是类似于Jupyter Notebook的操作非常方便,更重要的是有提供每次12小时免费的GPU训练 (这对于没强力GPU算力的我是一大福音阿!)。这次因为我们的对手是CycleGAN,庞大又复杂的神经网络训练就需要强大的GPU来支持拉!
开始使用Colab
安装、开启Colab
首先开启你的Google云端硬盘,在任意空白处右键 > 更多 > 链接更多应用程序

搜寻Colab并进行安装即可

接着对空白处点右键就可以看到Google Colaboratory的选项了,而Jupyter Notebook的 ipnb檔也可以直接使用Colab开启。

开启后操作跟Jupyter几乎是一样的,所以就不多赘述了!主要的还是记得将环境改成GPU模式,在编辑 > 笔记本设定中可以调整,可以看到给的GPU还算是不错了

绑定到云端硬盘
执行的时候点击网址,复制密钥并且在输入的方框中贴上
from google.colab import drive
drive.mount('/content/gdrive')
成功挂接后会显示现在的挂接的位置,接着就可以移动到档案的位置
import os
os.chdir('/content/gdrive/My Drive/Cavedu/Article/cycleGAN')
%ls
执行完成果如下:

这样就已经到相同层级的目录下了,接着开始设计程序拉,对程序有基础的人来说,透过程序代码去学习还是最快的呢。
处理数据
首先来准备数据集,一样到作者的数据库中去捞取
 |
到datasets中找到 vangogh2photo下载下来并解压缩到与程序代码同层

其中总共有四个文件夹,接着我们可以透过ImageFolder整理一个数据集并且透过DataLoader将其加载,这边要注意的是ImageFolder会去吃下一层级文件夹的内容,所以如果你直接写 ImageFolder(‘trainA’) 你会得到错误讯息,因为trainA里面就是档案了没有文件夹,最直观的做法就是再将所有档案包一层文件夹,所以程序的部分我宣告了new_trainA 并将 trainA放到他的底下,这样ImageFolder就成功抓取到资料了:
############ Prepare Data ############
transform = transforms.Compose(
[transforms.RandomHorizontalFlip(),
transforms.Resize((286, 286)),
transforms.RandomCrop((256, 256)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])])
train_path = r'.\vangogh2photo'
trainA_path = os.path.join(train_path, r'trainA')
targetA_path = os.path.join(train_path, r'new_trainA')
trainB_path = os.path.join(train_path, r'trainB')
targetB_path = os.path.join(train_path, r'new_trainB')
if os.path.exists(targetA_path) == False:
os.makedirs(targetA_path)
print('Create dir : ', targetA_path)
shutil.move(trainA_path, targetA_path)
if os.path.exists(targetB_path) == False:
os.makedirs(targetB_path)
print('Create dir : ', targetB_path)
shutil.move(trainB_path, targetB_path)
dataA_loader = DataLoader(dsets.ImageFolder(targetA_path, transform=transform), batch_size=batch_size, shuffle=True, num_workers=4)
dataB_loader = DataLoader(dsets.ImageFolder(targetB_path, transform=transform), batch_size=batch_size, shuffle=True, num_workers=4)
这边可以稍微做一下检查,由于我们要同时汇入两种风格的图片,但它们又各自成一家 (各自有一个DataLoader),所以我们必须透过 zip 这个函式把它们绑在一起,除了检查图片维度等等信息之外,你们可以再呼叫show_AB来看图片是否正确:
import numpy as np
import cv2
def show_AB():
img1 = data[0][0][0].numpy().transpose((1,2,0)) # vangogh
img2 = data[1][0][0].numpy().transpose((1,2,0)) # real pic
res = cv2.hconcat([img1, img2])
cv2.imshow('test' , res)
cv2.waitKey(0)
cv2.destroyAllWindows()
for idx, data in enumerate(zip(dataA_loader, dataB_loader)):
if idx > 0 :
break
else :
print(len(data)) # two data loader
print(data[0][0].shape) # trainA input_x
print(data[0][1].shape) # trainA input_y
print(data[0][0].shape[0]) # get batch size
建立生成器
当数据数据已经导入,接下来就能来定义模型拉!首先建构生成器 (Generator) 跟鉴别器 (Discriminator),以下简称G、D,这次我写的CycleGAN当中,生成器用的技术不再是pix2pix所提到的U-Nets,而是改采用大名鼎鼎的ResNet核心技术- 残缺块 (Residual Block)

简单讲一下残缺块的概念,主要就是当神经网络越来越多层的时候,就可能会开始遇到梯度消失跟梯度爆炸等问题,而梯度消失可能直觉想到的就是LeakyReLU来约束 ( 不要等于0 ),而2015年的时候Kaiming He提出了更简单的方式Skip Connection。假设说现在有四层权重在C-B的时候发生梯度消失,这时候梯度的讯息就没办法传导到A,但是有了Skip Connection,D的梯度也能持续传导到A不会受到影响,而这不仅仅能解决梯度消失的问题,也能改善梯度过小导致收敛过慢的问题。

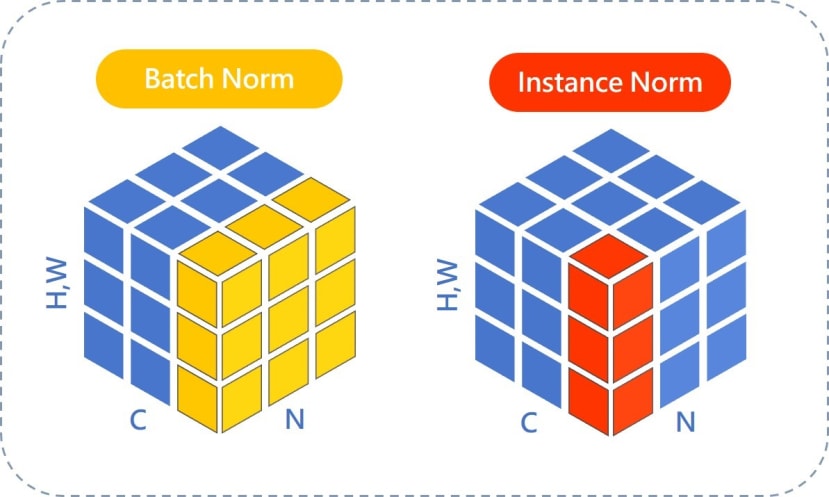
上图为该论文中提出的架构,其中Normalization的部份我们不是采用BatchNorm而是采用InstanceNorm,下图为BN跟IN的示意图 (HW为图片像素或称空间、C为通道、N为Batch的轴向),可以看到BN会对 (H,W) 跟N都进行正规化,但是在风格转换的案例中,结果通常会依赖在某几张图片的特征,这时候BN会将该批次的都综合平均掉,可能导致该张特征降低、有偏差;为了不影响结果又能做正规化加快收敛速度,我们使用Instance Norm,针对每一个实例都进行正规化,而不是一个批次的实例一起正规化。
好, 生成器的细部技术终于带完了,那我们直接来看程序代码吧!通常会先定义常用的层做一个区块。在这次的实作当中 Conv-InstancNorm-ReLU 通常都会绑在一起,所以我先宣告副函式将其包装在一起。
def conv_norm_relu(in_dim, out_dim, kernel_size, stride = 1, padding=0):
layer = nn.Sequential(nn.Conv2d(in_dim, out_dim, kernel_size, stride, padding),
nn.InstanceNorm2d(out_dim),
nn.ReLU(True))
return layer
def dconv_norm_relu(in_dim, out_dim, kernel_size, stride = 1, padding=0, output_padding=0):
layer = nn.Sequential(nn.ConvTranspose2d(in_dim, out_dim, kernel_size, stride, padding, output_padding),
nn.InstanceNorm2d(out_dim),
nn.ReLU(True))
return layer
接着因为有残缺块所以会特别定义一个类别包装残缺块:
class ResidualBlock(nn.Module):
def __init__(self, dim, use_dropout):
super(ResidualBlock, self).__init__()
res_block = [nn.ReflectionPad2d(1),
conv_norm_relu(dim, dim, kernel_size=3)]
if use_dropout:
res_block += [nn.Dropout(0.5)]
res_block += [nn.ReflectionPad2d(1),
nn.Conv2d(dim, dim, kernel_size=3, padding=0),
nn.InstanceNorm2d(dim)]
self.res_block = nn.Sequential(*res_block)
def forward(self, x):
return x + self.res_block(x)
看到这里是不是觉得还有一点怪怪的,其实还有一个小技巧没提到,这边都没使用Padding来让图片大小相同,反而去使用ReflectionPad,我自己的理解是要让图片显得更自然,保留的细节更好。
在这里我们定义生成器,总共使用了6层残缺块,通常会看到是6层或9层。
import torch
from torch import nn
from torchsummary import summary
class Generator(nn.Module):
def __init__(self, input_nc=3, output_nc=3, filters=64, use_dropout=True, n_blocks=2):
super(Generator, self).__init__()
# 向下采样 ( shape + 2 * padding - kernel + 1 ) / stride
# 256 + 3*2 = 262
# 262 - 7 + 0 + 1 = 256
# ( 256 + 2 - 3 + 1 / 2 = 128
# 128 + 2 - 3 + 1 / 2 = 64
model = [nn.ReflectionPad2d(3),
conv_norm_relu(input_nc , filters * 1, 7),
conv_norm_relu(filters * 1, filters * 2, 3, 2, 1),
conv_norm_relu(filters * 2, filters * 4, 3, 2, 1)]
# 颈脖层
for i in range(n_blocks):
model += [ResidualBlock(filters * 4, use_dropout)]
# 向上采样 (input-1)*stride + kernel - 2*padding + output_padding
# (64-1)*2 + 3 -2 +1 = 128
# (128-1)*2 + 3 -2 + 1 = 256
# 256 + 6 = 262
# 262 - 7 + 1 = 256
model += [dconv_norm_relu(filters * 4, filters * 2, 3, 2, 1, 1),
dconv_norm_relu(filters * 2, filters * 1, 3, 2, 1, 1),
nn.ReflectionPad2d(3),
nn.Conv2d(filters, output_nc, 7),
nn.Tanh()]
self.model = nn.Sequential(*model) # model 是 list 但是 sequential 需要将其透过 , 分割出来
def forward(self, x):
return self.model(x)
最后我们透过之前介绍的torchsummary来显示出来:
G = Generator()
summary(G, (3,256,256))

建立鉴别器
鉴别器相对就简单很多了,我们一样使用PatchGAN的技术,简单复习一下,一般生成对抗的鉴别器会输出一个数值介于 [0, 1] 之间,但PatchGAN的技术输出的是一组tensor,代表图像中各区域的真实程度;其他的部分就是一般DCGAN要注意的像是使用LeakyReLU以及输出层用tanh等。
import torch
from torch import nn
def conv_norm_leakyrelu(in_dim, out_dim, kernel_size, stride = 1, padding=0, output_padding=0):
layer = nn.Sequential(nn.Conv2d(in_dim, out_dim, kernel_size, stride, padding),
nn.InstanceNorm2d(out_dim),
nn.LeakyReLU(0.2,True))
return layer
class Discriminator(nn.Module):
def __init__(self, input_nc=3, filters=64, n_layer = 3):
super(Discriminator, self).__init__()
# 第一层不做 batchNorm
# 256 -1 +1 = 256
model = [
nn.Conv2d(input_nc, filters, kernel_size=1, stride=1, padding=0),
nn.LeakyReLU(0.2, True)]
# 第二、三层相同
# 256 +2 -4 +1 / 2 =
for i in range(1, n_layer):
n_filters_prev = 2**(i-1)
n_filters = 2**i
model += [conv_norm_leakyrelu(filters * n_filters_prev , filters * n_filters, kernel_size=4,
stride=2, padding=1)]
# 第四层 stride 为 1
n_filters_prev = 2**(n_layer-1)
n_filters = 2**n_layer
model += [conv_norm_leakyrelu(filters * n_filters_prev , filters * n_filters, kernel_size=4,
stride=1, padding=1)]
# 输出层
model += [nn.Conv2d(filters * n_filters, 1, kernel_size=4, stride=1, padding=1)]
self.model = nn.Sequential(*model)
def forward(self, input):
return self.model(input)
D = Discriminator()
D = Discriminator()
summary(D, (3,256,256))

从这边的输出可以注意到我们输出的是 (62, 62) 的tensor,再次验证了某些论文看似很难执行起来却很简单的道理。
定义CycleGAN
看到这里恭喜你已经将CycleGAN摸了一半了,接着我们在训练CycleGAN之前要先将依些基本的参数给定义好:
###### initial ######
def weights_init_normal(m):
classname = m.__class__.__name__
if classname.find('Conv') != -1:
init.normal_(m.weight.data, 0.0, 0.02)
###### basic parameters ######
device = 'cuda:0' if torch.cuda.is_available() else 'cpu'
batch_size = 4
epochs = 100
decay_epoch = 10
lr = 2e-3
log_freq = 100
CycleGAN总共需要两组GAN,这边也先定义好,并且套用初始化权重的副函式:
G_A2B – 学习将A风格转换成B风格
G_A2B – 学习将B风格转换成A风格
D_A – 学习判断是否为A风格的图像
D_B -学习判断是否为B风格的图像
############ Define Model ############
G_A2B = Generator().to(device)
G_B2A = Generator().to(device)
D_A = Discriminator().to(device)
D_B = Discriminator().to(device)
G_A2B.apply(weights_init_normal)
G_B2A.apply(weights_init_normal)
D_A.apply(weights_init_normal)
D_B.apply(weights_init_normal)
接着定义损失函式、优化器、学习率的更新工具,这边要注意的是我们需要定义两个损失函式 (MSE、L1),下一篇训练的时候会再提到;再来就是学习率的更新器了,在PyTorch当中更新学习率的方法有很多种,除了直接提取出来更改之外还有scheduler的方法,详细就不多做介绍,在相关文章中我有贴一篇在讲lr_scheduler的文章可以参考看看,在这边我LambdaLR的更新方式参考了这一篇github https://github.com/Lornatang/CycleGAN-PyTorch 的写法:
############ define Loss function ############
MSE = nn.MSELoss()
L1 = nn.L1Loss()
############ define optimizer ############
class LambdaLR():
def __init__(self, epochs, offset, decay_epoch):
self.epochs = epochs
self.offset = offset
self.decay_epoch = decay_epoch
def step(self, epoch):
return 1.0 - max(0, epoch + self.offset - self.decay_epoch)/(self.epochs - self.decay_epoch)
optim_G = torch.optim.Adam(itertools.chain(G_A2B.parameters(), G_B2A.parameters()), lr=lr, betas=(0.5, 0.999))
optim_D = torch.optim.Adam(itertools.chain(D_A.parameters() , D_B.parameters()), lr=lr, betas=(0.5, 0.999))
lr_scheduler_G = torch.optim.lr_scheduler.LambdaLR(optim_G,lr_lambda=LambdaLR(epochs, 0, decay_epoch).step)
lr_scheduler_D = torch.optim.lr_scheduler.LambdaLR(optim_D, lr_lambda=LambdaLR(epochs, 0, decay_epoch).step)
在训练之前我们还要定义最后一个东西,叫做ReplayBuffer,其实不使用他也是可以的,因为我最一开始是用tensorflow写cycleGAN也没提到相关技术一样可以训练,而稍微查了一下类似的技术在Q-learning中比较常见,在这边使用的概念比较像是储存50张生成的图像并且从其中随机抓取来做预测,目的可能是不要让神经网络学习到顺序的规则,如果理解有错误还请各位纠正。
# To store 50 generated image in a pool and sample from it when it is full
# Shrivastava et al’s strategy
class ReplayBuffer:
def __init__(self, max_size=50):
assert (max_size > 0), "Empty buffer or trying to create a black hole. Be careful."
self.max_size = max_size
self.data = []
def push_and_pop(self, data):
to_return = []
for element in data.data:
element = torch.unsqueeze(element, 0)
if len(self.data) < self.max_size:
self.data.append(element)
to_return.append(element)
else:
if random.uniform(0, 1) > 0.5:
i = random.randint(0, self.max_size - 1)
to_return.append(self.data[i].clone())
self.data[i] = element
else:
to_return.append(element)
return torch.cat(to_return)
fake_A_sample = ReplayBuffer()
fake_B_sample = ReplayBuffer()
到这边我们已经将CycleGAN要准备的都搞定了,接下来就是训练的重头戏,我们将在下一篇带大家实作如何训练、预测以及应用!
参考数据
CycleGAN 论文
https://arxiv.org/pdf/1703.10593.pdf
Pytorch中的学习率衰减方法
https://www.jianshu.com/p/9643cba47655
CycleGAN using PyTorch
https://github.com/arnab39/cycleGAN-PyTorch
CycleGAN-PyTorch