NVIDIA Jetson Nano应用-多线程平行处理,以项目-「你带口罩了吗?」为例
Artikel folgen
 Dave von DesignSpark
Dave von DesignSpark
Wie finden Sie diesen Artikel? Helfen Sie uns, bessere Inhalte für Sie bereitzustellen.
Dave von DesignSpark
Vielen Dank! Ihr Feedback ist eingegangen.
Dave von DesignSpark
There was a problem submitting your feedback, please try again later.
Dave von DesignSpark
Was denken Sie über diesen Artikel?
|
作者 |
张嘉钧 |
|
难度 |
普通 |
思路分析
原先使用主线程运行影像辨识以及IFTTT进行实时监控,光是执行影像辨识就会要等待推论的时间,而后如果要传送至IFTTT则又有一个传送的等待Request时间,如此便会影响到While循环里的实时影像,这边有很多种方法可以改善,最快且较为简单的解决方式是将实时影像放到另一个线程中去运行,这样显示实时影像与推论的线程是同步进行的,实时影像就不会因此被推论以及等待网页的时间给延迟,只需要专心处理实时影像的部分即可。
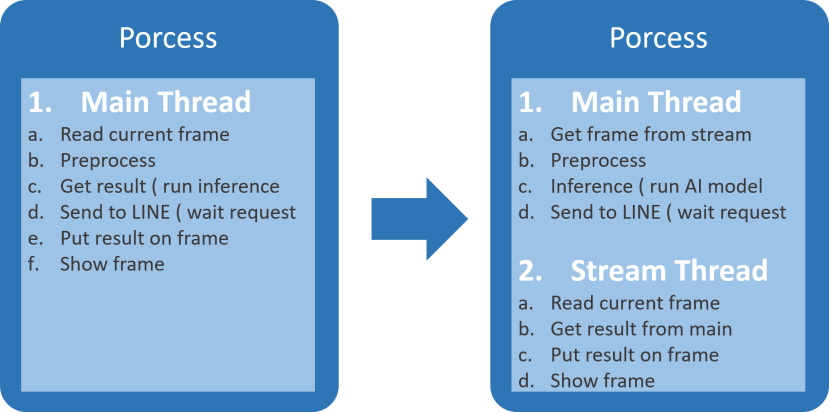
平行运算中的多线程
在Python的平行运算中有分两种,一个是Multi-Thread另一个是Multi-Process;Process ( 进程 ) 跟Thread ( 线程 ) 其实大家平常都会听到,在购买计算机的时候常常会听到几核几绪 ( 例如 : 四核八绪 ) 就是类似的概念,几个观念重点介绍:
- 每个CPU都只能运行一个Process,每个Process彼此之间是独立的。
- 每个Process可以有多个Thread运行,彼此共享内存、变量。
由于Thread无法回传值所以要使用Queue ( 队列 ) 去储存数据,那这部分我就不多作介绍因为网络上已经有很多相关的参考了,不过,这边我没有使用queue的方式去撰写程序。
增加实时影像的线程到程序中
我使用class的方式去写因为可以直接省略queue去储存、取得变量,算是一个偷吃步的小技巧,因为我这边除了读取帧之外就只有回传的动作,应该不会导致抢资源或同步的问题。
客制化的实时影像对象
为了符合我们的需求,我客制了一个类别提供了几个所需的功能,首先在initialize的部分,比较特别的地方在我使用了 isStop的参数用来中断线程并且宣告了t为实时影像线程的对象。
# 客制化的影像撷取程序
class CustomVideoCapture():
# 初始化 默认的摄影机装置为 0
def __init__(self, dev=0):
self.cap = cv2.VideoCapture(dev)
self.ret = ''
self.frame = []
self.win_title = 'Modified with set_title()'
self.info = ''
self.fps = 0
self.fps_time = 0
self.isStop = False
self.t = threading.Thread(target=self.video, name='stream')
接着先宣告了一些可以从外部控制线程的函式,像是 start_stream就是开启线程;stop_stream关闭线程;get_current_frame就是取得当前的画面,使用get_current_frame可以让外部直接获取线程更新的画面,算是一个使用Thread运行OpenCV常用的方法;最后还提供了一个set_title可以修改窗口的名称:
# 可以透过这个函式 开启 Thread
def start_stream(self):
self.t.start()
# 关闭 Thread 与 Camera
def stop_stream(self):
self.isStop = True
self.cap.release()
cv2.destroyAllWindows()
# 取得最近一次的帧
def get_current_frame(self):
return self.ret, self.frame
def get_fps(self):
return self.fps
# 设定显示窗口的名称
def set_title(self, txt):
self.win_title = txt
最后宣告了多线程要运作的函式,由于要不断更新画面所以使用while,透过isStop控制是否跳出循环,其中做的事情就是取得当前影像,设定要印上去的信息并显示出来,当按下q的时候会退出循环并且使用stop_stream终止循环:
# Thread主要运行的函式
def video(self):
try:
while(not self.isStop):
self.fps_time = time.time()
self.ret, self.frame = self.cap.read()
if self.info is not '':
cv2.putText(self.frame, self.info, (10,40), cv2.FONT_HERSHEY_SIMPLEX, 1, (0,0,255), 2)
cv2.imshow(self.win_title, self.frame)
if cv2.waitKey(1) == ord('q'):
break
self.fps = int(1/(time.time() - self.fps_time))
self.stop_stream()
except:
self.stop_stream()
我建立了一个tools.py存放所有会用到的副函式 ( 包含上述的客制化影像类别 ),这边开始介绍其他副函式,preprocess专门在处理输入前的数据,针对该数据进行缩放、正规化、转换成含有批次大小的格式:
# 用于数据前处理的程序
def preprocess(frame, resize=(224, 224), norm=True):
'''
设定格式 ( 1, 224, 224, 3)、缩放大、正规化、放入数据并回传正确格式的数据
'''
input_format = np.ndarray(shape=(1, 224, 224, 3), dtype=np.float32)
frame_resize = cv2.resize(frame, resize)
frame_norm = ((frame_resize.astype(np.float32) / 127.0) - 1) if norm else frame_resize
input_format[0]=frame_norm
return input_format
load_model_folder则是加载模型与卷标,这边写成只需要输入存放模型与卷标的目录路径即可,两者须放置在一起,程序会靠扩展名去判断:
# 读取 模型 与 卷标
def load_model_folder(trg_dir) -> "'trg_dir' is the path include model file and labels file. return (model, label).":
model_type = [ 'trt','engine','h5']
label_type = [ 'txt']
for f in os.listdir(trg_dir):
extension = f.split('.')[-1]
if extension in model_type:
model_dir = os.path.join(trg_dir, f)
elif extension in label_type:
lable_dir = os.path.join(trg_dir, f)
return get_model(model_dir), get_label(lable_dir)
刚刚输出的时候有用到两个副函式 get_model、get_label,分别去取得模型与卷标文件的对象:
# 读取模型
def get_model(model_dir) -> "support keras and tensorrt model":
if model_dir.split('.')[-1] == 'h5':
print('Load Keras Model')
model = tf.keras.models.load_model(model_dir)
else:
print('Load TensorRT Engine')
model = load_engine(model_dir)
return model
# 读取标签
def get_label(lable_dir) -> 'return dict of labels':
label = {}
with open(lable_dir) as f:
for line in f.readlines():
idx, name = line.strip().split(' ')
label[int(idx)]=name
return label
# 读取TensorRT模型
def load_engine(engine_path):
if trt_found:
TRT_LOGGER = trt.Logger(trt.Logger.WARNING)
trt_runtime = trt.Runtime(TRT_LOGGER)
with open(engine_path, 'rb') as f:
engine_data = f.read()
engine = trt_runtime.deserialize_cuda_engine(engine_data)
return engine
else:
print("Can not load load_engine because there is no tensorrt module")
exit(1)
接着是解析预测结果的副函式,通常我们会取得到一组预测的信心指数,我们需要针对这组数据去解析出最大数值是在哪一个位置,而该位置又属于哪一个类别:
# 解析输出信息
def parse_output(preds, label) -> 'return ( class id, class name, probobility) ':
preds = preds[0] if len(preds.shape)==4 else preds
trg_id = np.argmax(preds)
trg_name = label[trg_id]
trg_prob = preds[trg_id]
return ( trg_id, trg_name, trg_prob)
截至目前为止的程序,我都将其放在tools.py里,后续只要做import的动作即可将这些功能导入。
最后来到主程序的部分,这部分须要涵盖IFTTT以及Inference,流程大致如下:
1.取得模型与卷标、开启实时影像的线程:
# 取得模型与卷标
model, label = load_model_folder('keras_models')
# 设定影像撷取
vid = CustomVideoCapture()
vid.set_title('{sys} - {framework}'.format(sys='Jetson Nano', framework='Tensorflow'))
vid.start_stream()
2.设定辨识的参数,主要用于控制几秒辨识一次 ( t_delay ),与上次辨识结果不同才进行传送 ( pre_id ):
# 设定几秒辨识一次,降低运行负担
t_check = 0
t_delay = 2
t_start = 0
# 储存上一次辨识的结果,如果改变才传送,防止ifttt负担太大
pre_id = -1
3.设定IFTTT的参数:
# 设定「Line讯息」信息
event = 'jetsonnano_line'
key = 'i3_S_gIAsOty30yvIg4vg'
status = {
0:['是本人', '确定有做好防疫工作'],
1:['是本人', '注意,已成为防疫破口'],
2:['离开位置', ''],
3:['非本人', '注意您的财产']
}
4.使用While不断进行实时的辨识与LINE监控,这边设定了如果大于预设的delay时间则进行辨识:
# 开始实时辨识
t_start = time.time()
while(not vid.isStop):
# 计算时间如果大于预设延迟时间则进行辨识与发送
t_check = time.time() - t_start
if (t_check >= t_delay) or ( not vid.fps):
# 取得当前图片
ret, frame = vid.get_current_frame()
# 如果没有帧则重新执行
if not ret: continue
5.进行推论以及取得辨识结果,最后设定显示在实时影像上的信息:
# 进行处理与推论
data = preprocess(frame, resize=(224,224), norm=True)
prediction = model(data)[0]
# 解析 辨识结果
trg_id, trg_class, trg_prob =parse_output(prediction, label)
# 设定显示信息
vid.info = '{} : {:.3f} , FPS {}'.format(trg_class, trg_prob, vid.get_fps())
6.如果辨识结果与上次的不同,则回传给LINE:
if pre_id != trg_id:
ifttt.send_to_webhook(event,
key,
'环境变动',
status[trg_id][0],
status[trg_id][1] if status[trg_id][1] else '')
pre_id = trg_id
# 更新 time
t_start = time.time()
7.最后在While的外部需要确认一下Thread是否都有关闭了,写多线程很常遇到的问题就是开了线程,但是忘记关闭导致资源被用完,所以做个DoubleCheck会是不错的选择:
# 跳出 while 循环需要检查多线程是否已经关闭
time.sleep(1)
print('-'*30)
print(f'影像串流的线程是否已关闭 : {not vid.t.is_alive()}')
print('离开程序')
完整主程序如下:
#%%
import cv2
import threading
import os, time, random
import ifttt
import numpy as np
import tensorflow as tf
import platform as plt
from tools import CustomVideoCapture, preprocess, load_model_folder, parse_output
import time
# 取得模型与卷标
model, label = load_model_folder('keras_models')
# 设定影像撷取
vid = CustomVideoCapture()
vid.set_title('{sys} - {framework}'.format(sys='Jetson Nano', framework='Tensorflow'))
vid.start_stream()
# 设定几秒辨识一次,降低运行负担
t_check = 0
t_delay = 2
t_start = 0
# 储存上一次辨识的结果,如果改变才传送,防止ifttt负担太大
pre_id = -1
# 设定「Line讯息」信息
event = 'jetsonnano_line'
key = 'i3_S_gIAsOty30yvIg4vg'
status = {
0:['是本人', '确定有做好防疫工作'],
1:['是本人', '注意,已成为防疫破口'],
2:['离开位置', ''],
3:['非本人', '注意您的财产']
}
#%%
# 开始实时辨识
t_start = time.time()
while(not vid.isStop):
# 计算时间如果大于预设延迟时间则进行辨识与发送
t_check = time.time() - t_start
if (t_check >= t_delay) or ( not vid.fps):
# 取得当前图片
ret, frame = vid.get_current_frame()
# 如果没有帧则重新执行
if not ret: continue
# 进行处理与推论
data = preprocess(frame, resize=(224,224), norm=True)
prediction = model(data)[0]
# 解析 辨识结果
trg_id, trg_class, trg_prob =parse_output(prediction, label)
# 设定显示信息
vid.info = '{} : {:.3f} , FPS {}'.format(trg_class, trg_prob, vid.get_fps())
# 如果与上次辨识不同,则将辨识到的结果传送至Line
if pre_id != trg_id:
ifttt.send_to_webhook(event,
key,
'环境变动',
status[trg_id][0],
status[trg_id][1] if status[trg_id][1] else '')
pre_id = trg_id
# 更新 time
t_start = time.time()
# 跳出 while 循环需要检查多线程是否已经关闭
time.sleep(1)
print('-'*30)
print(f'影像串流的线程是否已关闭 : {not vid.t.is_alive()}')
print('离开程序')
可以发现使用Thread来运行影像就完全不会受到IFTTT的影响,FPS都可以维持在30甚至以上,而主线程只需要关注于辨识以及传送数据给IFTTT即可。
使用TensorRT引擎加速推论
刚刚使用了Thread来改善IFTTT传送卡顿的问题,我们也可以针对AI推论来做改善,我们使用Jetson Nano最大的优势就在于可以使用TensorRT引擎加速处理,所以这边教大家怎么从Teachable Machine下载模型并转换成TensorRT引擎。
概略介绍
TensorRT是一个支持NVIDIA CUDA核心的加速引擎,透过对神经网络模型进行重构与数据缩减来达到加速的目的,在Jetson Nano中使用TensorRT绝对是做AI Inference的首选,那如何将神经网络模型转换成TensorRT去运行呢?
1.需要先将模型转换成 Onnx 的通用格式
2.接着在转换成 TensorRT 引擎可运作的格式
在Jetson Nano中已经带有TensorRT转换的工具,但是怎么将模型转换成Onnx还需要安装额外的工具,所以我们先来安装一下tf2onnx这个套件吧。
环境版本
|
JetPack |
4.4.1 |
|
Python |
3.6.9 |
|
pip |
21.0 |
|
tensorflow |
2.3.1+nv20.12 |
|
onnx |
1.8.1 |
安装 tf2onnx并将模型转换成onnx
首先需要将tensorflow的模型转换成onnx,我们将使用tf2onnx这个套件,在安装之前需要先确保onnx已经被安装了,这边提供相依套件以onnx的安装命令:
$ sudo apt-get install protobuf-compiler libprotoc-dev # onnx 相依套件
$ pip3 install onnx
$ pip install onnxruntime
升级numpy (可有可无):
$ python3 -m pip install -U numpy --no-cache-dir --no-binary numpy安装tf2onnx:
$ pip3 install tf2onnx宣告OpenBLAS的核心架构,在JetsonNano上少了这步应该会报错误讯息” Illegal instruction(core dumped)”:
$ nano ~/.bashrc
export OPENBLAS_CORETYPE=ARMV8
$ source ~/.bashrc
安装完之后可以回到上次教学的Teachable Machine,这次要下载的文件格式必须选择成TensorFlow > Savemodel,如下图所示:

Savemodel是Tensorflow模型「串行化」的格式,由于Onnx的格式也是串行化的,所以在一开始就转换成Savemodel在后续转换Onnx比较不容易出错。我们可以使用执行下列指令转换成onnx模型:
$ python3 -m tf2onnx.convert --saved-model ./savemodel --output ./test_opset_default.onnx透过Jetson Nano内建工具转换成TensorRT
接着可以使用JetsonNano的原生工具 (trtexec) 转换成TensorRT:
$ /usr/src/tensorrt/bin/trtexec --onnx=/home/dlinano/TM2/test_opset_default.onnx --saveEngine=/home/dlinano/TM2/test.trt --shapes=input0:1x3x224x224同时需要安装pycuda,安装步骤当中有一个nvcc是用来确认是否有抓到cuda,若没有加入环境变量则会报错,同时也无法安装pycuda:
$ nano ~/.bashrc
export PATH=${PATH}:/usr/local/cuda/bin
export LD_LIBRARY_PATH=${LD_LIBRARY_PATH}:/usr/local/cuda/lib64
$ source ~/.bashrc
$ nvcc -V
$ pip3 install pycuda
由于我们会使用到tensorrt提供的范例common.py,所以先直接复制一份:
$ cp /usr/src/tensorrt/samples/python/common.py ./common.py经过繁琐的操作后,终于可以运行程序了:
$ python3 tm_tensorrt.py这个程序比照上一篇的方法所撰写,可以注意到FPS相较于之前的推论程序都高非常多,已经可以到顺跑的程度了。

程序讲解
导入函式库以及设定TRT的基本参数
import cv2
import tensorrt as trt
import numpy as np
import common
import platform as plt
import time
from tools import preprocess, load_model_folder
TRT_LOGGER = trt.Logger(trt.Logger.WARNING)
trt_runtime = trt.Runtime(TRT_LOGGER)
先取得 TensorRT引擎,透过先前撰写好的副函式 ( load_model_folder ) 来取得 engine、label;再导入之前我们需要预先定义好buffer给TensorRT;接着解析TensorRT对象取得该「执行文本」:
load trt engine
print('取得TRT引擎与卷标')
engine, label = load_model_folder('tensorrt_engine')
# allocate buffers
print('分配 buffers 给 TensorRT 所须的物件')
inputs, outputs, bindings, stream = common.allocate_buffers(engine)
print('创建执行文本 ( context )')
context = engine.create_execution_context()
接着我们使用与上一篇雷同的OpenCV程序完成实时影像辨识,最大的区别在于TensorRT引擎导入数据的方法与推论的方法:
print('开启实时影像')
fps = -1
cap = cv2.VideoCapture(0, cv2.CAP_GSTREAMER)
while(True):
t_start = time.time()
# 读取图片
ret, frame = cap.read()
# 将图片进行前处理并放入输入数据中
inputs[0].host = preprocess(frame)
# 进行 Inference
trt_outputs = common.do_inference(context, bindings=bindings, inputs=inputs, outputs=outputs, stream=stream)
# 解析输出数据
trg_idx, trg_class, trg_prob = parse_output(trt_outputs[0], label)
# 设定显示数据
info = '{} : {:.3f} , FPS {}'.format(trg_class, trg_prob, fps)
# 将显示数据绘制在图片上
cv2.putText(frame, info, (10,40), cv2.FONT_HERSHEY_SIMPLEX, 1, (0,0,255), 2)
cv2.imshow('TensorRT', frame)
if cv2.waitKey(1) == ord('q'):
break
# 更新FPS与时间点
fps = int(1/(time.time()-t_start))
t_start = time.time()
最后离开的时候一样要做确认的动作:
cap.release()
cv2.destroyAllWindows()
print('离开程序')三种框架比较
既然都做到TensorRT加速了,我们还是得来比较一下速度差距(仅供参考):
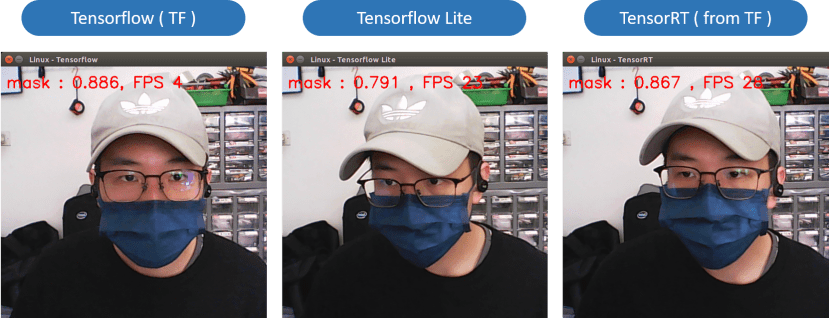
可以注意到Tensorflow的速度最慢但是准确度最高;Tensorflow Lite则是牺牲准确度换取高效能的表现;而TensorRT就更优秀了,优化的时候保留更多准确度,效能也能有效提高。
TensorRT结合Thread与IFTTT
建构的方式与上述雷同,所以就直接提供完整程序:
import cv2
import tensorrt as trt
import numpy as np
import common
import platform as plt
import time
import ifttt
import threading
from tools import CustomVideoCapture, preprocess, load_model_folder, parse_output
TRT_LOGGER = trt.Logger(trt.Logger.WARNING)
trt_runtime = trt.Runtime(TRT_LOGGER)
def main():
pre_idx = -1
print('取得TRT引擎与卷标')
engine, label = load_model_folder('tensorrt_engine')
print('分配 buffers 给 TensorRT 所须的物件')
inputs, outputs, bindings, stream = common.allocate_buffers(engine)
print('创建执行文本 ( context )')
context = engine.create_execution_context()
print('设定实时影像参数')
vid = CustomVideoCapture()
vid.set_title('{sys} - {framework}'.format(sys='Jetson Nano', framework='TensorRT'))
vid.start_stream()
# 设定几秒辨识一次,为了配合 ifttt 的延迟通知
t_check = 0
t_delay = 1
t_start = 0
# 储存上一次辨识的结果,如果改变才传送,防止ifttt负担太大
pre_id = -1
# 设定「Line讯息」信息
print('设定IFTTT参数')
event = 'jetsonnano_line'
key = 'i3_S_gIAsOty30yvIg4vg'
status = {
0:['是本人', '确定有做好防疫工作'],
1:['是本人', '注意,已成为防疫破口'],
2:['离开位置', ''],
3:['非本人', '注意您的财产']
}
t_start = time.time()
while(not vid.isStop):
# 计算时间如果大于预设延迟时间则进行辨识与发送
t_check = time.time()-t_start
if t_check >= t_delay:
ret, frame = vid.get_current_frame()
if not ret: continue
inputs[0].host = preprocess(frame, resize=(224, 224), norm=True)
infer_time = time.time()
# with engine.create_execution_context() as context:
trt_outputs = common.do_inference(context, bindings=bindings, inputs=inputs, outputs=outputs, stream=stream)
infer_time = time.time() - infer_time
preds = trt_outputs[0]
trg_id, trg_class, trg_prob = parse_output(preds, label)
vid.info = '{} : {:.3f} , FPS : {:.3f}'.format(trg_class, trg_prob, vid.get_fps())
if pre_id != trg_id:
ifttt.send_to_webhook(event,
key,
'环境变动',
status[trg_id][0],
status[trg_id][1] if status[trg_id][1] else '')
pre_id = trg_id
t_start = time.time()
# 跳出 while 循环需要检查多线程是否已经关闭
time.sleep(1)
print('-'*30, '\n')
print(f'影像串流的线程是否已关闭 : {not vid.t.is_alive()}')
if __name__ == '__main__':
main()
结语
这次我们使用了两种方式来进行改造、加速,其实透过Thread就能有不错的成果了,但是TensorRT又能再减少一些负担,让 AI辨识与Line的监控讯息可以变得更加确实、快速。