Wenn Redundanz eine gute Sache ist
Artikel folgen
 Dave von DesignSpark
Dave von DesignSpark
Wie finden Sie diesen Artikel? Helfen Sie uns, bessere Inhalte für Sie bereitzustellen.
Dave von DesignSpark
Vielen Dank! Ihr Feedback ist eingegangen.
Dave von DesignSpark
There was a problem submitting your feedback, please try again later.
Dave von DesignSpark
Was denken Sie über diesen Artikel?

Die Technik der zweifachen, dreifachen oder sogar vierfachen Redundanz kritischer Schaltkreise zur Erhöhung der Zuverlässigkeit kommt schon seit Langem zum Einsatz. Logischerweise wurden die ersten auf diese Weise konzipierten Systeme für militärische Luft- und Raumfahrtanwendungen entwickelt, da Redundanz kostspielig war. Sie machte es möglich, dass Flugzeuge sicher über die Steuerung durch einen Computer, einer Technik namens „Fly-by-Wire“, geflogen werden, wodurch die Leistung der Flugzeuge weit über die Fähigkeiten eines menschlichen Piloten hinaus gesteigert wurde. Der Computer zur Steuerung der Apollo Saturn V-Rakete der 1960er-Jahre verfügte über dreifache Redundanz, die wahrscheinlich für seine unglaubliche Zuverlässigkeit unter den extremen Bedingungen eines Raketenstarts verantwortlich ist. Die Verwendung zweifacher oder dreifacher identischer Stromkreismodule zur Vermeidung eines unsicheren Betriebs wird als zweifache modulare Redundanz (DMR) oder dreifache modulare Redundanz (TMR) bezeichnet.
Sensor-Redundanz
In Abb. 1 sind die Grundlagen der zweifachen und dreifachen modularen Redundanz von Sensoren zu sehen. Die meisten modernen Schaltkreissensoren verfügen über serielle Digitalausgänge (z. B. UART, SPI oder I²C-Bus), so dass der Abstimmungs-Logikschaltkreis, der die Daten von jedem einzelnen Ausgang vergleicht, wahrscheinlich ein kleiner energiesparender Mikrocontroller ist. Modulare Redundanz ist eine Sensorfusionstechnik mit dem Ziel, die Systemzuverlässigkeit zu verbessern. In Form der zweifachen modularen Redundanz kann sie einen kritischen Fehler erkennen und eine kontrollierte Abschaltung des Systems ermöglichen. Mit anderen Worten: Sie erhöht die Wahrscheinlichkeit eines „ausfallsicheren“ Szenarios. Die dreifache modulare Redundanz führt das Konzept einer einzelnen „Fehlertoleranz“ ein, ohne Betriebsunterbrechung bis zum Ausfall eines zweiten Sensors. In jedem Fall werden die Daten der einzelnen Sensoren nicht zusammengeführt oder in irgendeiner Weise verarbeitet, sondern lediglich im Hinblick auf Übereinstimmung verglichen, was geringfügige Abweichungen der Ausgabe ermöglicht, die zwischen realen Komponenten auftreten.

Während die Sensoren verdoppelt (a) oder verdreifacht (b) sind, ist der Abstimmungsschaltkreis nur einmal vorhanden und führt daher zu einem „Single Point of Failure“-Risiko (SPF). Dieses Problem kann durch Hinzufügen einer redundanten Abstimmungslogik gelöst werden, doch bevor man sich mit dieser Schwierigkeit auseinandersetzt, lohnt es sich, die vom Hersteller bereitgestellten Ausfallraten des Sensors und der Abstimmungsschaltkreise zu vergleichen. Beispielsweise bietet Microchip MTTF-Statistiken (mittlere Betriebsdauer bis zum Ausfall) für den Großteil seiner Mikrocontroller. Es ist sehr wahrscheinlich, dass die Sensoren, die im Normalbetrieb häufig hohen Belastungen ausgesetzt sind, wesentlich kleinere MTTF-Werte aufweisen als der Abstimmungsschaltkreis. Bei der Berechnung der Systemausfallrate kann der Beitrag der Abstimmungslogik oft herabgesetzt werden.
Die Entwicklung von Prozessor-Redundanz
In einem integrierten Steuerungssystem werden Sensoreingangsdaten von einem bestimmten Algorithmus verarbeitet, der auf einem Mikrocontroller ausgeführt wird, der Ausgangsdaten für die Ansteuerung von Betätigungselementen und Displays erzeugt. Dieser Mikrocontroller (MCU) stellt ein ernsthaftes SPF-Risiko dar und benötigt integrierte redundante Stromkreise, wenn er in einer sicherheitskritischen Anwendung verwendet wird.
Fly-by-Wire-Systeme mit Redundanz kommen bereits seit der Einführung der Saturn V-Rakete der 1960er Jahre und in jüngster Zeit in Linienflugzeugen zum Einsatz, erstmals beim Airbus A320 im Jahr 1988. Redundante Systeme gehen mit einer hohen Zusatzinvestition einher, nicht nur in physische Hardware, sondern vor allem in die Arbeitszeit von Ingenieuren, die Stromkreise/Software so entwickeln, dass sie leistungsstark genug sind, um das Ziel einer erfolgreich abgeschlossenen Mission zu erreichen. Dieses Ziel gilt sowohl für bemannte als auch für unbemannte Missionen, umfasst jedoch das Gewährleisten von Sicherheit, wenn Menschen beteiligt sind. Das Erfordernis von Erfolg bei Missionen hat sich im Laufe der Jahrzehnte nicht geändert, so auch nicht das Konzept der Redundanz. Was sich geändert hat, ist höchstwahrscheinlich der Fehlerzustand, dauerhaft oder vorübergehend, und die wahrscheinliche Ausfallrate für jeden Fehlerzustand. Moderne Schaltkreise sind weniger anfällig für dauerhafte Fehler als zuvor, doch ihre viel höhere Dichte an Technologie ist anfälliger für vorübergehende Störungen durch (kosmische) Streupartikel.
TMR und Fehlertoleranz
Die klassische dreifache modulare Redundanz (TMR) umfasst dreifach vorhandene identische Prozessoren, die denselben Code ausführen und ihre Ausgangsdaten über eine Vergleichslogik weiterleiten, die bestätigt, dass alle drei die gleichen Ergebnisse liefern. Das bedeutet, dass der normale Betrieb fehlerfrei erfolgt (Abb. 2). Sollte ein Prozessor „einen Fehler machen“, kann dessen Ausgabe ignoriert werden, da die anderen beiden übereinstimmen und ihre Ausgabe durch eine „Mehrheitsabstimmung“ für korrekt befunden und weitergeleitet wird. Dies wird als Fehlermaskierung bezeichnet, da ein fortlaufender sicherer Betrieb ohne Unterbrechung möglich ist, bis die übrigen Prozessoren nicht mehr übereinstimmen. Das System wird als fehlertolerant bezeichnet, da ein einzelner vorübergehender oder dauerhafter Fehler den Fluss der Ausgangsdaten nicht unterbricht. Dies eignet sich ideal für Echtzeit-Steuerungsanwendungen. Ein solches System schützt jedoch nicht unbedingt vor Designfehlern in den identischen Prozessoren oder Fehlern im identischen Programmcode, der in jedem Prozessor ausgeführt wird.
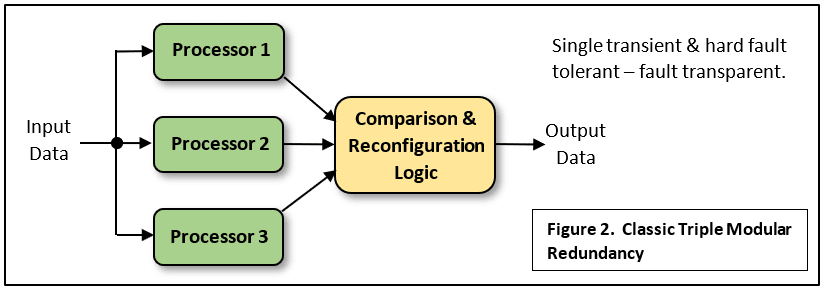
Jeder Prozessor kann dieselben Eingangsdaten von einzelnen, nicht redundanten Sensoren empfangen, wie bereits erwähnt. Es ist jedoch besser, auch redundante Sensoren zu verwenden, wie in Abb. 1 gezeigt. Der Nachteil dieser Form von dreifacher modularer Redundanz ist die Komplexität der Vergleichslogik und der Schaltkreise, die erforderlich sind, um sicherzustellen, dass die „richtigen“ Daten auf die Endausgabe angewendet werden. Möglicherweise müssen auch die Prüfstromkreise verdreifacht werden und das ist nicht einfach. Hier ist ein aktueller Artikel zum Thema.
DMR und Fehlerbehebung
Die praktischste Lösung für Designer von Sicherheitssystemen, die Komplexität einer fehlertoleranten dreifachen modularen Redundanz zu umgehen, ist der Ausgleich durch eine DMR-Konfiguration mit Fehlerbehebung. Die verschiedenen Computer, die die Tragflächen (Höhenleitwerk, Seitenruder usw.) des Airbus A320 steuern, bestehen jeweils aus zwei unabhängigen Prozessoren, die sich gegenseitig überprüfen. Jeder Fehler führt zu einer Abschaltung und einer Funktionsübertragung auf einen anderen Computer. Fünf dieser Computer sind auf ausgeklügelte Weise miteinander verbunden und steuern redundante Betätigungselemente. Der Ausfall von einem Element hat keine Auswirkungen auf die Leistung des Flugzeugs. Wenn mehrere ausfallen, verschlechtert sich das Betriebsverhalten, bis ein Element übrig bleibt und die Steuerung des Höhenleitwerks aufrechterhält, was zusammen mit dem redundanten Seitenruder dafür sorgt, dass das Flugzeug gelenkt werden und sicher landen kann. Weitere Informationen zum redundanten Flugsteuerungssystem des A320 finden Sie in dieser technischen Beschreibung.
Unterschiedlichkeit
Das Problem identischer Computer mit identischer Software, die identische falsche Antworten liefern, wird beim A320 durch Einführung des Konzepts der Unterschiedlichkeit gelöst. Drei der fünf Computer basieren jeweils auf einem Paar Intel 80186 16-Bit-Mikroprozessoren; die anderen beiden verfügen über Motorola 68010 16/32-Bit-Einheiten. Die einzelnen Typen werden von separaten Auftragnehmern entworfen, gebaut und programmiert: Die einzige Gemeinsamkeit ist die redundante externe Busschnittstelle und das zugehörige Protokoll. Sicherheit hat ihren Preis.
Sicherheits-Mikrocontroller und „Lockstep“
Fortschritte in der Siliziumtechnologie haben dazu geführt, dass die Prozessorschaltkreise mehr als einen „Kern“ haben, was eine enorme Steigerung der Leistung oder des Durchsatzes zur Folge hat. Mehrkern-Geräte enthalten keine Redundanz, sondern nur die Funktion, mehrere verschiedene Programme wirklich parallel auszuführen. Heute scheint das Konzept autonom betriebener Maschinen Realität zu werden, zum Beispiel hinsichtlich fahrerloser Autos und sogar ganzer Fertigungswerke. Natürlich ist Sicherheit zu einem sehr großen Thema geworden. Glücklicherweise wurden Normen zur Konstruktion und Sicherheitszertifizierung autonomer Produkte verabschiedet: IEC 61508 für die allgemeine industrielle Steuerung und ISO 26262 für Automobilanwendungen. Hersteller von Schaltkreisen haben mit einer neuen Geräteklasse geantwortet – dem Sicherheits-Mikrocontroller. Die meisten dieser neuen Geräte basieren auf dem DMR-Prinzip, jedoch mit einer Besonderheit: Auf den beiden Prozessorkernen wird dasselbe Programm ausgeführt, jedoch mit einer Abweichung von mindestens einem Taktzyklus (Abb. 3). Die Ausgänge werden zur Fehlererkennung neu ausgerichtet.

Die festgelegte Verzögerung zwischen den beiden Prozessoren stellt sicher, dass ein vorübergehender Fehler, der beide Kerne gleichzeitig betrifft, nicht unerkannt bleibt. Die Kerne werden im Gleichschritt, „ Lockstep“, betrieben. Weitere Redundanz ist enthalten, um gekippte Speicherbits (Codes oder Logik zur Fehlerkorrektur) und gekippte Bits auf Kommunikationskanälen (Cyclic Redundancy Code oder CRC-Prüfung) zu beheben. Zudem gibt es eine integrierte Built-In Self-Test-Logik (BIST), die aktiviert wird, wenn eine Abweichung der Kerndaten erkannt wird. Dies ermöglicht die Behebung vorübergehender Fehler durch einen vollständigen Reset, wenn kein dauerhafter Fehler gefunden wird. Das ist noch nicht alles: Der Schaltkreis ist so ausgelegt, dass Fehler, die bei beiden Kernen auftreten, minimiert werden. Einige dieser Maßnahmen, die Texas Instruments für seine Hercules TMS570-Reihe ergreift, sind in Abb. 3 dargestellt. Dazu gehört die 90°-Anordnung der beiden Kerne zueinander mit einem Mindestabstand von 100 μm.
Weitere Beispiele für Sicherheits-Mikrocontroller mit Lockstep sind der AURIX von Infineon, der SPC5 von STMicro und der S32S24 von NXP.
Künstliche Intelligenz und redundante Systeme
Prozessorredundanz kann sich als nützlich erweisen, um ein großes Hindernis bei der Einbeziehung von KI in sicherheitskritischen Systemen zu überwinden. Das Problem besteht darin, dass Deep Learning für die Objekterkennung Gegenstand unbeabsichtigter Verzerrungen ist, es sei denn, die „Lehrbilder“ werden sehr sorgfältig ausgewählt. Sie können sich vorstellen, inwiefern dies zu katastrophalen Fehlern führen kann, die das System für maschinelles Sehen eines fahrerlosen Autos macht. Eine mögliche Lösung ist die Verwendung eines dreifachen Systems, bei dem jede in dem Fahrzeug laufende „Inferenzmaschine“ mit einem anderen Datensatz arbeitet, der aus verschiedenen Bildsätzen erstellt wurde. Es sollte eine hohe Wahrscheinlichkeit bestehen, dass mindestens zwei Prozessoren gleichzeitig die richtige Lösung finden!
Alles miteinander verbinden
Diese Lockstep-Geräte können einen vorübergehenden Kernfehler erkennen, einen Test durchführen und den Prozessor nach einem vollständigen Reset wieder in den vollen Betrieb versetzen. Wenn Sie eine vollständige Fehlertoleranz wie beim Computer der Saturn V-Rakete benötigen, können Sie dies dank der Europäischen Weltraumorganisation bekommen. Sie hat die LEON-Reihe fehlertoleranter Kerne entwickelt, die die meisten Single-Event-Upsets aufgrund der Auswirkungen kosmischer Partikel ohne Betriebsunterbrechung ausgleichen können.
Redundanz rettet Leben – sollte sie zumindest
Der sich unlängst ereignende Absturz des Flugs EA302 von Ethiopian Airlines, bei dem die neueste Version der Boeing 737 im Spiel war, zeigt, wie kleine Änderungen im Design in einer Katastrophe enden können. Alle modernen Linienflugzeuge verfügen über umfassende redundante Sicherheitssysteme, die in der Regel auf den „duplizierten“ Piloten im Cockpit basieren. Duplizierte Flugsensoren versorgen duplizierte Flugsteuerungscomputer und Displays auf jeder Seite des Cockpits mit Daten. Es erfolgt eine Gegenprüfung zwischen den Computern, um gültige Sensordaten zu bestätigen, und als letzte Sicherung können die menschlichen Piloten die Messwerte vergleichen. Das Problem mit der neuen 737 Max bestand darin, dass ein zusätzliches System namens MCAS hinzugefügt wurde, um eine zusätzliche Warnung über einen möglichen Strömungsabriss auszugeben, wenn während des Starts die volle Triebwerksleistung bereitgestellt wurde. Die Nase des Flugzeugs neigt dazu, sich „aufzurichten“, genau wie ein Motorrad bei einem „Wheelie“. Die 737 Max benötigte dieses Warnsystem, da ihre größeren, weiter oben und weiter vorn montierten Triebwerke negative Auswirkungen auf die Aerodynamik des ursprünglichen Designs hatten.
Das neue Warnsystem überwachte nur einen der beiden Anstellwinkelfühler – ein schwerwiegender Fehler in Anbetracht dessen, dass die frühere mechanische „Windrichtungsgeber“-Ausführung als unzuverlässig galt. Während des Flugs 302 blieb der überwachte Anstellwinkelfühler plötzlich bei einem Winkel blockiert, den das neue MCAS-System nur als extremen Strömungsabriss interpretieren konnte. Wenn der andere redundante Anstellwinkelfühler angeschlossen gewesen wäre, wäre eine Warnung wegen Nichtübereinstimmung der Anstellwinkelfühler ausgegeben worden und die Piloten hätten dann das MCAS deaktivieren können. Tatsächlich hätte ein sorgfältig konzipiertes redundantes System auch Informationen von den Staudrucksonden und Beschleunigungssensoren zur Plausibilitätsprüfung heranziehen können. Ohne Redundanz hat der fehlerhafte Sensor das MCAS dazu veranlasst, einen bevorstehenden Strömungsabriss zu interpretieren, so dass der Steuerknüppel des Piloten nach vorn gedrückt wurde. Ein weiterer fataler Konstruktionsfehler bestand in der Annahme, dass jeder Strömungsabriss auf einen Fehler des Piloten zurückzuführen ist: Das MCAS drückte den Steuerknüppel nach vorn und der Pilot hatte nicht die nötige Kraft, ihn zurückzuziehen. Die Warnung wegen Nichtübereinstimmung der Anstellwinkelfühler hätte vom Hersteller als „optionale Zusatzfunktion“ eingebaut werden können. In diesem Fall hätte mehr Redundanz das Unglück möglicherweise verhindern können. Die menschlichen Piloten im wahrsten Sinne des Wortes „redundant“ zu machen, endete in dieser Katastrophe.