What Engineers Need to Know About Edge Computing
Follow article
 Dave from DesignSpark
Dave from DesignSpark
How do you feel about this article? Help us to provide better content for you.
Dave from DesignSpark
Thank you! Your feedback has been received.
Dave from DesignSpark
There was a problem submitting your feedback, please try again later.
Dave from DesignSpark
What do you think of this article?
Reshaping the Digital Landscape
For many years, the dynamics driving the global IT sector have led to a centralising of computing resources at the cloud. As well as bringing about a reduction in the overall operational cost associated with IT, this has resulted in all sorts of useful innovations within our working culture and our home life too. It has enabled employees to telecommute to their offices and members of design/creative teams residing in different locations to seamlessly collaborate with one another. Thanks to cloud computing, our files may be backed up to make certain there is no longer a risk of them being lost or corrupted. Higher up the food chain, it is ensuring that the critical business data compiled by enterprises isn’t subject to the threat posed by potential power outages and suchlike. Although this will continue to be valid in a large number of use cases, there are times when this will clearly not be applicable. Another trend is emerging that acts as a counterpoint to these cloud-based topologies. This will mean that some work can be offloaded away from the cloud, with several significant benefits thereby being derived. This article will explain the need for large scale adoption of edge computing. It will look at the applications where this will be of the greatest importance and the various technological challenges it poses.
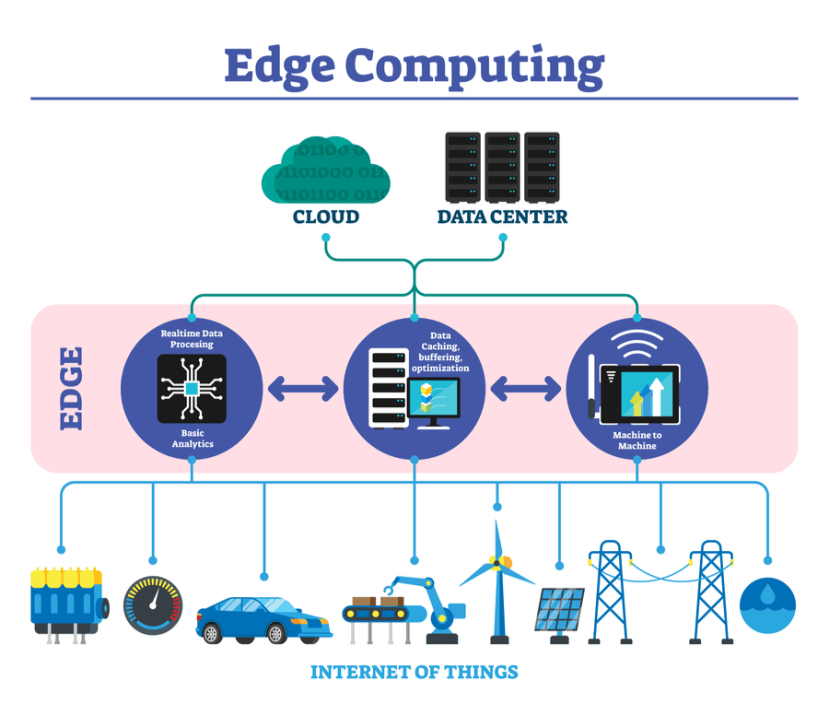
Behavioural Changes to Data Usage
There are two key reasons why edge computing will be an essential part of our future, increasingly data-centric society. These are as follows:
- There is a huge strain being placed on networking infrastructure. This is due to an ever-increasing number of connected devices generating data. A major contributor to this will be the Internet of Things (IoT) - with countless IoT nodes now starting to go into operation. Statista has estimated that there are already over 20 billion connected IoT nodes, and that figure is expected to reach 50 billion by the end of this decade. If data from all of these nodes have to be transferred back to the cloud it will result in unprecedented levels of congestion.
- In addition to the number of connections involved, the conventional centralised architecture puts a lot of distance between data sources and where that data is actually going to be processed. This means that the turnaround times witnessed are relatively slow. Certain workloads simply will not be able to accept this lack of responsiveness, as the implications will be too serious. These can range from a poor user experience for users and loss of revenue for enterprises, right through to human safety being put in jeopardy.
Whichever technology analyst you talk to, it is universally agreed that Industry 4.0, virtual reality (VR), streaming of high-definition (HD) video from smartphones, autonomous vehicles and numerous other bandwidth-intensive applications are all going to gain greater traction in the years ahead. Yet every one of these has requirements that cloud computing alone will not be able to adequately satisfy. Consequently, a new approach to data processing needs to be implemented - namely edge computing.
Each of the application examples just mentioned will rely on the generation of large amounts of data. Likewise, they also have a time-critical element to them, with rapid reactions being mandated if they are to prove effective. This is why edge computing will have such value. The fundamental principle of this technology is that all the constituent processing resources and data storage reserves are no longer stacked up back in the cloud. Instead, ‘cloudlets’ are formed. And these are located closer to where the data is being sourced and subsequently actioned.
The advantages of implementing a more distributed topology are two-fold. Firstly, the pressures put on network bandwidth can be substantially reduced, as less data traffic will need to be transported. Secondly, support for much lower latency operation is made possible, since more analysis can be carried out locally. This means that real-time operational requirements and decision making can be taken care of. Data will then normally only have to go back to the cloud in order for longer-term analysis of underlying trends, etc.
Edge Computing’s Backstory
There are some vital engineering developments that have, in combination with one another, resulted in edge computing’s arrival on the scene. The first of these is the advent of lower power processing hardware. This is suitable for more remote deployment, where there may be power budget constraints to contend with. Alongside this is the continually heightening storage densities and lowering unit costs associated with flash memories. This has made distributed data storage much more commercially viable. Artificial intelligence (AI) is no longer something that has to be applied back at the cloud either. Ongoing technological progression has meant that more streamlined AI models have been developed, and these are suitable for edge-based inferencing work.
Use Cases
Surveillance is one of the places where edge computing is already starting to see traction. In the past, the video streams from cameras would all be passed from network video recorder (NVR) system hubs to the cloud so that AI algorithms could be applied. This would take time and use of considerable network bandwidth too. By putting more of the necessary processing resources closer to the cameras (or within the cameras themselves), all the video data captured does not have to make that long-drawn-out trip. The superfluous footage that is not of interest won’t need to be transported, as everything can be analysed at the source. Furthermore, if something deemed to be of importance is detected (through facial or number plate recognition) and needs to be flagged then a response can be made much quicker.
Taking the principles discussed above in a general surveillance context and applying them to homes, edging computing could have real value when it comes to the care of the elderly or infirm - allowing individuals to continue with independent living for longer and giving a better quality of life. By having monitoring systems recording video footage and applying AI algorithms in real-time, it will be possible for caregivers or relatives to be alerted if a serious issue arises or there is a notable deterioration in their condition over time.
Another area where edge computing will have significant value is in relation to VR and augmented reality (AR). It will allow visual content to be updated at much faster rates. This will mean that the user experience can be enhanced, avoiding the lag problems that poor latency will cause - which can otherwise result in the user feeling nauseous or impinging on their overall enjoyment.
In the industrial sphere, edge computing will form the foundation for condition monitoring. Here the IIoT sensor nodes used for monitoring different processes and equipment will have the necessary computing capacity built-in and will be able to run AI algorithms. The presence of any behavioural anomalies may then be identified, without the need for cloud situated analysis. Reaction times are thus accelerated, so that critical situations do not have time to escalate.
Challenges to Overcome
Though the advantages that edge computing presents are clear. It is not without its drawbacks. The costs of having processing and data storage functions at many different locations raise the capital expenditure involved. There will likewise be increased operational costs to factor in, due to the need to maintain the expansive processing/storage assets comprised. Concerns about operational reliability must also be considered. To address this, it is important that adequate redundancy is designed into the distributed topology to prevent any point of failure leading to unwanted disruption.
Data storage being distributed throughout the network, either at cloudlets or at the actual nodes, greatly increases the attack surface for hackers to try to exploit - heightening the risk of a potential security breach occurring. That said, by not having data all located in one centralised place, the possibility of a large scale attack is averted.
Though certain aspects of edge computing are not ideal, they must be balanced against the unquestionable appeal that improved latency and reduced network traffic brings. These are things that are not just desirable, but completely essential to a multitude of nascent applications that will come to the fore in the years ahead. There is no doubt that edge computing is destined to become a part of our evolving digital landscape. It will work in tandem with existing cloud-based topologies, with each of these being optimised for different use case scenarios.
