Simple rasp-identifier using Movidius
Follow article
 Dave from DesignSpark
Dave from DesignSpark
How do you feel about this article? Help us to provide better content for you.
Dave from DesignSpark
Thank you! Your feedback has been received.
Dave from DesignSpark
There was a problem submitting your feedback, please try again later.
Dave from DesignSpark
What do you think of this article?
Simple rasp-identifier!!
Build edge device based 20-classes-identifying gadget with a Pi 3 Model B+, Intel Movidius NCS, the Pi-Top CEED Pro, and a Web Camera.

This project requires Raspberry Pi 3 Model B plus with Raspbian Stretch, and the Intel Movidius NCS. In addition to a Web Camera connect Raspberry Pi via USB slot. Finally, we display our result on the Pi-Top CEED Pro, Green.
Hardware
In this project, I recommend to install any VM with Ubuntu16.04. I repeat it must be 16.04 Ubuntu, I have tested the 18.X version, trust me, only Errors would be compiled.
So, let’s get started.
To begin with the Raspberry Pi~~~~
Plug in the Raspberry Pi to your Pi Top.
pi@raspberryPi: sudo raspi-configOption 5- Interfacing->P1- Camera->Enable->Yes
Option 5- Interfacing->P4- SPI->Enable->Yes
Option 7-Advanced Options->A7-GL driver->G2 GL (Fake KMS)-> Activate
To set up the Movidius on raspberry Pi, you may refer to this article written by Andrew Back: AI Powered Identificaution with the Pidentifier! His demonstration of Pidentifier is great and I learned a lot from this article. You may also follow his step by step set up of the Raspberry Pi with Movidius Stick. Or you can follow the Movidius Startup guide. Caution NCSDK v1 is the only choice for you.
Software Dependencies

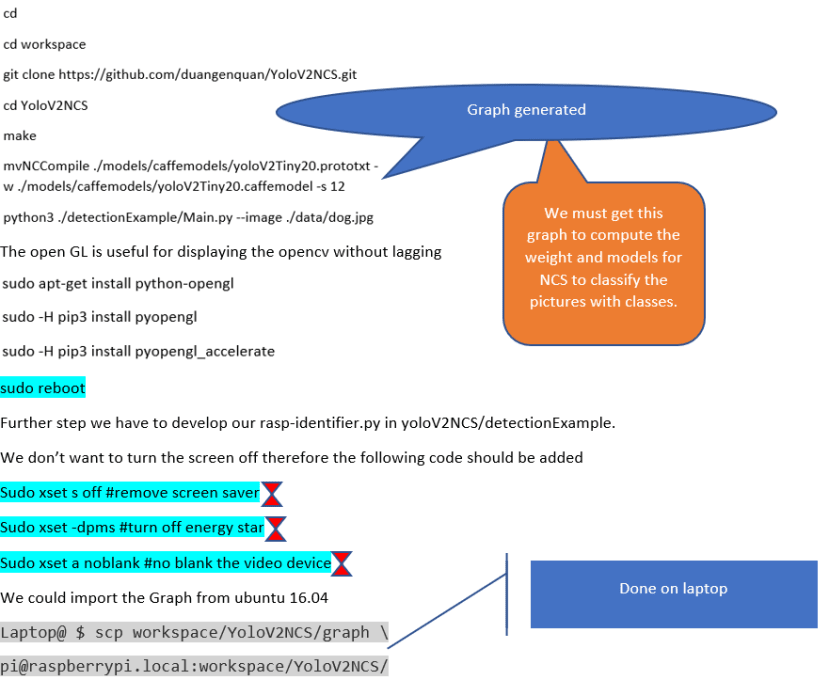
We could tune the Movidius in various ways such as Pictures, Graphs, or even, Voice. Via rapid tuning, we can obtain a great caffe model and a graph, which can be further used in the Raspberry Pi for the EDGE devices.
Due to my carelessness, I install the latest version of the NCSDK2 in a rooted ubuntu desktop which caused me a fatal result and I needed to reboot the ubuntu. To deal with this issue I installed the VM to continue my work.

The above picture shows an example of 2 layers deep learning.
This Graph is similar to the black oval which select the weight and gives only a result. It’s hard to distinguish a cat and a dog. Yet the NCS could ease the computer by a single graph.
Here is the method to install the Movidius which is similar to installation on the Raspberry Pi.
LAPTOP@WHOYOUARE: sudo apt-get update
LAPTOP@WHOYOUARE: sudo apt-get upgrade
LAPTOP@WHOYOUARE: sudo apt-get install python3-pip python3-numpy git cmake
Caution: the NCS must be inserted into this computer when making examples.

Why do we have to make examples?
It is because there are not many make files downloaded. Running examples is building individual examples. Each example comes with its own Make file, which will install only that particular example and any prerequisites it requires.
Hardware Checking
sudo apt-get install fswebcam
fswebcam image.jpg
If the following code is shown on screen. Congratulations your camera is working and is functional.
--- Processing captured image...
Writing JPEG image to 'image.jpg'.
Program on Raspberry Pi
The Raspberry Pi is not as fast as the Intel CPU so it is hard to run a high level of neural network. Likewise, the YoloV2NCS and YoloNCS are not suitable for Raspberry Pi due to the complex instruction and our Pi will become lagging.
To reduce the issue, we could modify the Yolo to Tiny Yolo, thanks PINTO; although the correctness is not comparable, we could still use Tiny Yolo to demonstrate 20-classes of the object.
wget https://github.com/PINTO0309/OpenCVonARMv7/blob/master/libopencv3_3.4.1-20180304.1_armhf.deb
sudo apt install -y ./libopencv3_3.4.1-20180304.1_armhf.deb
sudo ldconfigAgain, we have to install the YoloV2NCS on Raspberry Pi
import sys
graph_folder="./" # Graph
if len(sys.argv) > 1:
graph_folder = sys.argv[1]
from mvnc import mvncapi as mvnc
import numpy as np
import cv2
from os import system
import io, time
from os.path import isfile, join
from queue import Queue
from threading import Thread, Event, Lock
import re
from time import sleep
from Visualize import *
from libpydetector import YoloDetector
from OpenGL.GL import *
from OpenGL.GLU import *
from OpenGL.GLUT import *
Set the global logging level to verbose.
mvnc.SetGlobalOption(mvnc.GlobalOption.LOG_LEVEL, 2)
# check the Movidius NCS is linked or not.
# show the numbers of movidius NCS implunged.
devices = mvnc.EnumerateDevices()
if len(devices) == 0:
print("No devices found")
quit()
print(len(devices))
#Create arrays for Name and graphs’ weights
devHandle = []
graphHandle = []
with open(join(graph_folder, "graph"), mode="rb") as f:
graph = f.read()
for devnum in range(len(devices)):
devHandle.append(mvnc.Device(devices[devnum]))
devHandle[devnum].OpenDevice()
graphHandle.append(devHandle[devnum].AllocateGraph(graph))
graphHandle[devnum].SetGraphOption(mvnc.GraphOption.ITERATIONS, 1)
iterations = graphHandle[devnum].GetGraphOption(mvnc.GraphOption.ITERATIONS)
dim = (320,320)
blockwd = 9
targetBlockwd = 9
wh = blockwd*blockwd
classes = 20
threshold = 0.3
nms = 0.4
print("\nLoaded Graphs!!!")
The graph was loaded at this point. We are to build the Web Camera information as well as the display information.
widowWidth = 320
windowHeight = 240
cam.set(cv2.CAP_PROP_FRAME_WIDTH, widowWidth)
cam.set(cv2.CAP_PROP_FRAME_HEIGHT, windowHeight)
lock = Lock()
frameBuffer = []
results = Queue()
lastRR = None
detector = YoloDetector(1)
Here are some definitions of opengl and Webcam The glClearColor first three parameters are the RGB color of the background. We just put 0.7 for the last value.
def init():
glClearColor(0.7, 0.7, 0.7, 0.7)
def idle():
glutPostRedisplay()
def resizeview(w, h):
glViewport(0, 0, w, h)
glLoadIdentity()
glOrtho(-w / 1920, w / 1920, -h / 1080, h / 1080, -1.0, 1.0)
def keyboard(key, x, y):
key = key.decode('utf-8')
if key == 'q':
lock.acquire()
while len(frameBuffer) > 0:
frameBuffer.pop()
lock.release()
for devnum in range(len(devices)):
graphHandle[devnum].DeallocateGraph()
devHandle[devnum].CloseDevice()
print("\n\nFinished\n\n")
sys.exit()
We will clear the image while we are turning on the webcam. Therefore it's less lagging than YoloV2NCS and YoloNCS.
def camThread():
global lastresults
s, img = cam.read()
if not s:
print("Could not get frame")
return 0
lock.acquire()
if len(frameBuffer)>10:
for i in range(10):
del frameBuffer[0]
frameBuffer.append(img)
lock.release()
res = None
if not results.empty():
res = results.get(False)
if res == None:
if lastRR == None:
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
h, w = img.shape[:2]
glTexImage2D(GL_TEXTURE_2D, 0, GL_RGB, w, h, 0, GL_RGB, GL_UNSIGNED_BYTE, img)
else:
imdraw = Visualize(img, lastresults)
imdraw = cv2.cvtColor(imdraw, cv2.COLOR_BGR2RGB)
h, w = imdraw.shape[:2]
glTexImage2D(GL_TEXTURE_2D, 0, GL_RGB, w, h, 0, GL_RGB, GL_UNSIGNED_BYTE, imdraw)
else:
img = Visualize(img, res)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
h, w = img.shape[:2]
glTexImage2D(GL_TEXTURE_2D, 0, GL_RGB, w, h, 0, GL_RGB, GL_UNSIGNED_BYTE, img)
lastRR = res
else:
if lastRR == None:
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
h, w = img.shape[:2]
glTexImage2D(GL_TEXTURE_2D, 0, GL_RGB, w, h, 0, GL_RGB, GL_UNSIGNED_BYTE, img)
else:
imdraw = Visualize(img, lastresults)
imdraw = cv2.cvtColor(imdraw, cv2.COLOR_BGR2RGB)
h, w = imdraw.shape[:2]
glTexImage2D(GL_TEXTURE_2D, 0, GL_RGB, w, h, 0, GL_RGB, GL_UNSIGNED_BYTE, imdraw)
Here is determining the rectangle openGL for locating the area which NCS located. In order to Reduce the color overlap, we set up 20 colors for each graph class.
glClear(GL_COLOR_BUFFER_BIT | GL_DEPTH_BUFFER_BIT)
glColor3f(1.0, 1.0, 1.0)
glEnable(GL_TEXTURE_2D)
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MIN_FILTER, GL_LINEAR)
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MAG_FILTER, GL_LINEAR)
glBegin(GL_QUADS)
glTexCoord2d(0.0, 1.0)
glVertex3d(-1.0, -1.0, 0.0)
glTexCoord2d(1.0, 1.0)
glVertex3d( 1.0, -1.0, 0.0)
glTexCoord2d(1.0, 0.0)
glVertex3d( 1.0, 1.0, 0.0)
glTexCoord2d(0.0, 0.0)
glVertex3d(-1.0, 1.0, 0.0)
glEnd()
glFlush()
glutSwapBuffers()
def infer(results, lock, frameBuffer, handle):
failure = 0
sleep(1)
while failure < 100:
lock.acquire()
if len(frameBuffer) == 0:
lock.release()
failure += 1
continue
img = frameBuffer[-1].copy()
del frameBuffer[-1]
failure = 0
lock.release()
start = time.time()
imgw = img.shape[1]
imgh = img.shape[0]
now = time.time()
im,offx,offy = PI (img, dim)
handle.LoadTensor(im.astype(np.float16), 'user object')
out, userobj = handle.GetResult()
out = RS(out, dim)
internalresults = detector.Detect(out.astype(np.float32), int(out.shape[0]/wh), blockwd, blockwd, classes, imgw, imgh, threshold, nms, targetBlockwd)
pyresults = [BBox(x) for x in internalresults]
results.put(pyresults)
print("elapsedtime = ", time.time() - now)
# we took picture to classify the object. Although Delay exists, it is still acceptable.
def PI (img, dim):
imgw = img.shape[1]
imgh = img.shape[0]
imgb = np.empty((dim[0], dim[1], 3))
imgb.fill(0.5)
newh = dim[1]
neww = dim[0]
offx = int((dim[0] - neww)/2)
offy = int((dim[1] - newh)/2)
imgb[offy:offy+newh,offx:offx+neww,:] = cv2.resize(img.copy()/255.0,(newh,neww))
im = imgb[:,:,(2,1,0)]
return im,offx,offy
def RS(out, dim):
shape = out.shape
out = np.transpose(out.reshape(wh, int(shape[0]/wh)))
out = out.reshape(shape)
return out
class BBox(object):
def __init__(self, bbox):
self.left = bbox.left
self.top = bbox.top
self.right = bbox.right
self.bottom = bbox.bottom
self.confidence = bbox.confidence
self.objType = bbox.objType
self.name = bbox.name
glutInitWindowPosition(0, 0)
glutInit(sys.argv)
glutInitDisplayMode(GLUT_RGBA | GLUT_DOUBLE )
glutCreateWindow("DEMO")
glutFullScreen()
glutDisplayFunc(camThread)
glutReshapeFunc(resizeview)
glutKeyboardFunc(keyboard)
init()
glutIdleFunc(idle)
print("press 'q' to quit!\n")
threads = []
for devnum in range(len(devices)):
t = Thread(target=infer, args=(results, lock, frameBuffer, graphHandle[devnum]))
t.start()
threads.append(t)
glutMainLoop()
Check the Result
cd workspace/YoloV2NCS/
python3 ./detectionExample/rasp-identifier.py
Caffe Issue
If there are Caffe error you may directly put the following code to change the caffe location for .py to run
$export PYTHONPATH=$env:"/opt/movidius/caffe/python":$PYTHONPATH
Contributions to the YoloV2NCS are invited, with a set of simple guidelines provided and submission via GitHub pull request. Thanks to Andrew Back for demonstrating a simple way of easing the Caffe issue problem.
Further Development
The future will be led by deep learning and data analyzing. In this project, only 20 classes of weights and models for NCS to cope with. However, is it possible to increase the speed to recognize more classes without lagging?
Is it possible to deal with the TensorFlow in real time, using Raspberry Pi? Some people said it is possible with more NCS.
The ncsdk v1 is soon to remove and will be replaced by ncsdk v2, could the following code suite the new environment?
In a word, it is impossible to control our future, yet we could take deep learning wisely to merge with our society and develop a better future.