Pytorch深度学习框架X NVIDIA JetsonNano应用-线性回归与实作
关注文章
 戴夫来自 DesignSpark
戴夫来自 DesignSpark
你觉得这篇文章怎么样? 帮助我们为您提供更好的内容。
戴夫来自 DesignSpark
Thank you! Your feedback has been received.
戴夫来自 DesignSpark
There was a problem submitting your feedback, please try again later.
戴夫来自 DesignSpark
你觉得这篇文章怎么样?
|
作者 |
嘉钧 |
|
难度 |
理论困难,实作普通 |
|
材料表 |
|
深度学习的框架有很多种,Tensorflow、PyTorch、Mxnet、Theano等等的,其中最大众的算是Google的Tensorflow,但还有一大部分的使用者是透过PyTorch来开发深度学习,今天我们就来介绍并使用PyTorch这款深度学习套件并且使用torch做个简单的线性回归;这篇文章的对象是对于深度学习已经稍微有点概念想自己建构神经网络模型的人。

PyTorch是基于Torch而来,顺着近几年Python广为流传而开发了PyTorch,都是由Facebook的AI研究团队所研发的深度学习框架,他们的优势在于易于开发修改模型 (Dynamic Neural Networks)、类似Python语法让使用简单及可读性更好 ( TorchScript )、架构设计也易于多GPU的分布式训练;程序撰写的流程如下图,与Tensorflow略为不同像是计算损失函式与梯度要特别撰写出来,在这边也不战PyTorch与Tensorflow之间的优劣,就让广大的读者自己去尝试自己喜爱的框架。
安装
安装方法非常的简单,对于Nvidia的兼容度也很高只要选取对应的CUDA版本即可使用GPU训练,不过我们基本上都是使用边缘装置所以今天带大家安装CPU的版本;直接前往PyTorch的官网进行选取版本https://pytorch.org/

这边我们安装了一个名为torch的 Anaconda虚拟环境
> conda create --name torch python=3.7 -y
> conda activate torch
> conda install numpy jupyter -y
> conda install pytorch torchvision cpuonly -c pytorch
其余套件,numpy是数学运算很好用的函式库,支持大量维度的矩阵运算,也是神经网络数据处理的好工具而matplotlib是Python程序语言及其数值数学扩展包 NumPy的可视化操作界面。
> conda install numpy matplotlib -y我的每个套件版本如下图:

安装好之后我们可以使用Jupyter-notebook来练习PyTochScript,直接在终端机中输入指令即可:
> jupyter notebook可以直接在jupyter-notebook中新增Python3的程序语言,在这边可以直接使用 import 将 pytorch导入,需要注意的地方是导入套件的名称是「torch」不是「pytorch」,在jupyter中执行只需要点选欲执行的Block并按下Shift+Enter,若没有报错代表能够成功执行。


基础函式
1. 张量
张量是深度学习的基本元素,转成张量才方便神经网络去做运算,因为除了有规律性之外还方便GPU进行大量地平行运算;张量的定义在各种领域上都有不同的见解,这边广义的理解就是任何维度的资料,有时候可表示在一张图上所有的坐标点,有时候也可以表示图片所有pixel的RGB数值,甚至一维向量在这里也可以转换成张量。而PyTorch 自称是深度学习界的 Numpy,会这样说代表它的操作几乎跟Numpy差距不大。
2. 生成张量
使用方法与函式名称与Numpy相同,宣告也非常简单易懂。

3. 从Numpy转换成Tensor
PyTorch的优势在于数据转换非常的方便,有时候我们需要将训练的参数提取出来查看,像是特征图如果是张量的形式是无法被OpenCV或PIL显示出来的,这时候就需要将张量转换回Numpy,其中如果是张量的话会在印出来的时候于最前面显示。

4. 将Tensor 放入GPU以及提取成Numpy
下图没有提到的是,如果张量在GPU当中训练,需要先使用 .detech() 冻结该张量,因为怕影响到神经网络的训练。

5. 合并、朔形、最大值、维度相加
这几种技能是深度学习非常常用到的关键,在这边使用的方法跟Numpy一样,只是函式的名称不同而已。


6. PyTorch的Autograd
6-1 计算图 (Computation graphs) 原理
介绍之前先来带点有关计算图的基础观念,如果已经会了的人可以考虑跳到第二小节程序的部分;计算图存在的意义是为了让程序更方便计算,从计算的层面来看,神经网络的计算主要分成两个部分:
- Forward (向前传递):计算Loss损失函数数值
- Backward (反向传递):用于计算梯度

图6.1 神经网络模型

图6.2计算图的节点就像个函数
计算图中向前传递的计算方式非常的简单,每个节点都可以当作是一个简单的函数,而计算完的结果如下,这边假设正确输出是10,L是模拟计算损失函式:

如果我们去针对该模型的起始a去计算偏导数的话如下:

可以发现这些计算都是依循了「链锁律」,复杂的函数都是由简单的函数所构成对于这个神经网络模型手动计算很简单,但是当神经网络很复杂的时候就不适合这样去计算,所以才产生了计算图的方式,让计算机按照顺序去计算所有变量的梯度;由于反向传递也符合链锁律的法则,所以我们可以针对个别的运算去做偏导数再做合计,理论上会获得一样的结果。

图6.3 反向传递的时候针对个别的函数进行微分
假如我们现在计算整个函数 L 对 a 的导数,有几个重点:
- 我们需要先找到整个函数可以从L 走到 a 的所有路径,总共两条
- 将其路径上所有偏导数相乘,记得只有数学运算的部分也就是边条的部分
所以最后的结果会跟我们手动求偏导的结果是一样的:
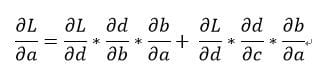
整理一下会发现,结果竟然一样:

6-2 PyTorch的Auto grad framework
为了让PyTorch知道这些张量是要进行反向传递的,我们必须再宣告的时候使用 requires_grad,让这些张量的计算保存在计算图当中。顺带一提,requires_grad的默认值是False。

我们先用一个很简单的范例来测试反向传递,在PyTorch中我们使用 backward函数来进行反向传递,它会自动帮我们算好并且使用 grad 将其计算后的结果取出,记得backward的对象是最后的输出而grad的对象是预计要训练的权重。

接下来我们透过先前所说的范例来进行反向传递,可以看到结果是正确的。

6-3 PyTorch冻结权重
在神经网络的训练中,有些人会刻意冻结某些层让模型不会训练到那些参数,迁移学习或是生成对抗都会用到该技术;在Tensorflow的作法需要使用到freeze() 的函数,而PyTorch可以将required_grad() 设定成False或是使用torch.no_grad() 这个函数。

实作:线性回归 (Linear Regression)
前面已经将大部分基础的PyTorch给介绍完了,接下来可以建置一个简单的线性回归试试看,首先机器学习中有分线性回归与非线性回归两种,建立的步骤如下:
- 建立最基本的线性模型,例如 : y = w * x + b
- 设定要训练的数据 ( 输入 x、权重 w、偏差b以及输出 y ),我们选择先将 w、b预设 [ 10. , 3. ] 方便观察计算机是否收敛到跟默认值一样。

3.我们的目的是要让模型可以慢慢学习到正确的权重 ( w ),所以这边我们利用 randn 来随机产生权重 ( w_ ),让模型自己更新成正确的权重;并且我们宣告一组新的 x 用来预测 ( 测试资料 )。

4.设定超参数,目前先定义了「迭代次数」、「纪录时间」、「学习率」。

5.随机生成的权重 ( w_ ) 会计算出一组新的答案 ( y_ )。我们会计算新的 y_ 跟正确解答 y 的「差距」也就是Loss,我们可以透过 loss知道现在对于模型来说是否越来越接近正确解答;而我们使用的方法是MSE。
6.Loss 的部分需要进行反向传递来获得梯度,让模型知道还差多远、朝哪个方向走才会逼近解答。

7.接下来就要更新权重,通常会设置一个学习率来调整更新的步伐大小。这边要注意的事,由于 PyTorch 每次呼叫参数都会将数据追踪到计算图中,为了防止重复运算我们使用 no_grad,并在其底下更新权重 ( w_ )。
8.新的权重 ( w_ ) 就会获得新的答案 ( y_ ),也会有新的梯度 ( w_.grad ),所以记得要将梯度给清除,不然会将旧的累加上去。

完整程序代码以及可视化结果如下:

可以发现因为模型简单进行50次迭代就能收敛的很好,为了更好的观察我也做了可视化,可以注意到每次迭代都有确实往Ground Truth收敛:


结语
整篇文章下来相信你已经学会如何用PyTorch制作一个LinearRegression了,不过还有一个LogsticRegression还没实作,这部分会在下一篇中也会一并介绍,此外还会教大家使用torch.nn改造这篇最后的程序,torch.nn是torch帮大家打包好的模块,里面有各种函数可以调用,建置神经网络的全连接层、卷积层等,还有激励函数、优化器等,你将会发现torch建置神经网络的快速跟强大。
下一篇:
Pytorch深度学习框架X NVIDIA JetsonNano应用-torch.nn实作