Predicting weather using LSTM | LSTM Software | DesignSpark
Follow article
 Dave from DesignSpark
Dave from DesignSpark
How do you feel about this article? Help us to provide better content for you.
Dave from DesignSpark
Thank you! Your feedback has been received.
Dave from DesignSpark
There was a problem submitting your feedback, please try again later.
Dave from DesignSpark
What do you think of this article?
| Author | Dan |
| Difficulty | Moderate |
| Time required | 2hrs |
Since we have discussed how to use some embedded systems such as Raspberry Pi to collect sensor data, we want to introduce a way on how to utilize the data for prediction using deep learning. This is a very useful topic most especially if we already have tons of data in our database or repository.
In performing this project, we used the following specifications:
- OS: Windows 10
- GPU: Nvidia GTX1070
- RAM: 32GB
These specifications are more than enough for this application. However, we recommend using a computer with a GPU to run this project so that you can see the results instantly. Otherwise, the waiting time for training the model may take time. In addition, here are the libraries required for this project:
- keras 2.2.4
- matplotlib 2.1.1
- numpy 1.17.4
- opencv-python 3.4.3.18
- tensorflow-gpu 1.11.0
- scikit-image 0.15.0
- scikit-learn 0.19.1
- scipy 1.1.0
As we always advise, install the libraries first before going through the project tutorial. Please also take note that these libraries may not be the latest version thus, the program might not work for earlier or later versions of the libraries.
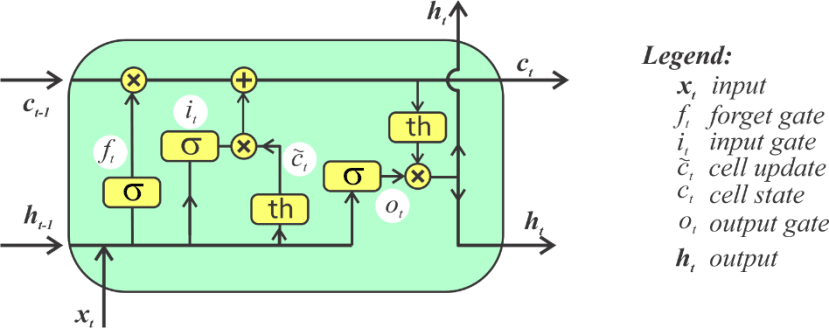
Source: https://bhrnjica.net/2019/04/08/in-depth-lstm-implementation-using-cntk-on-net-platform/
As a brief explanation, the input of the LSTM cell is a time series set of data x that undergoes several sigmoid activation gates σ. Each gate calculates a certain function to calculate the cell states. What we provided is only a very concise explanation of how LSTM works. For more information regarding LSTM, it is still a lot better to take a class on deep learning to further understand the concepts.
Software
After studying a bit about LSTM, we want to check out how to implement it into a program. To go through this tutorial, please refer to LSTM_demo.py in our repository.
https://github.com/danrustia11/WeatherLSTM
Upon opening the demo program, you can see the following source codes:
1)First, we want to call the libraries required to run this program. Other than that, we want to call some data conditioning functions. Compared to other LSTM demos, we want to show here the importance of using clean input data to perform LSTM prediction. As much as people expect, LSTM is not a perfect solution for prediction. If there are very few patterns found from the data, the LSTM still cannot predict your data. Thus, we want to condition the data first. Other than that, we want to make our results reproducible by setting the random number generator.

2)Next, we just want to call the other libraries needed for the program. Particularly, we want to include a normalisation function to prepare our data for training. Normalisation is important to make our model more efficient.

3)In here, you can set the n_timestamp, the number of timestamps (in this case, days) to be used as input for prediction. This is important since we want to consider how much data should our model check out before making a prediction. This depends on the application. Let’s say we want to do weather prediction, then we might need at least a week of data to predict the next day’s data.
We also have here the train_days, number of training days. This makes sure that the model learns several patterns based on historical data. The testing_days is how many days we want to predict. For training, we have the n_epochs, the number of epochs required for training. Since we were able to test this program beforehand, around 25 epochs was already enough to train the model without overfitting.
Lastly, we have the filter_on variable that activates the filter for our data.

4)We want to select the model type here. We want to use a stacked model in which two LSTM cells are stacked together.

5)Our data comes from here. We are going to use the daily ambient temperature of Yilan County in Taiwan provided by the Environmental Protection Administration of Taiwan.

6)In here, we perform median filter and Gaussian filter on the dataset.

7)Next, we want to set our training and testing data set based on our set variables a while ago.

8)The data is normalised from 0 to 1 here.

9)Our data is split according to the number of timestamps declared a while ago.

This means that we use n_timestamps to predict the next day. The prediction program runs a moving window of n_timestamps for prediction.
10)Now, we want to construct the LSTM model using Keras.
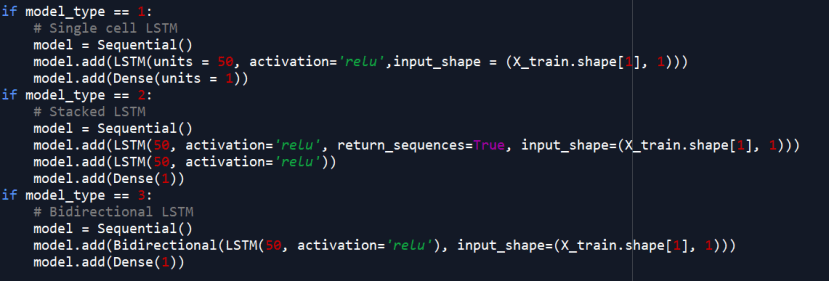
11)Finally, we start our model training here. If you cannot run the training program, it might be a good solution to reduce the batch size.

12)Afterwards, we want to predict the data based on our testing dataset. We also want to convert the data back to its original values based on the normalisation process.

13)Lastly, we want to display the results of the prediction. Here, we included the original data, the n predicted days, and the first 75 days.
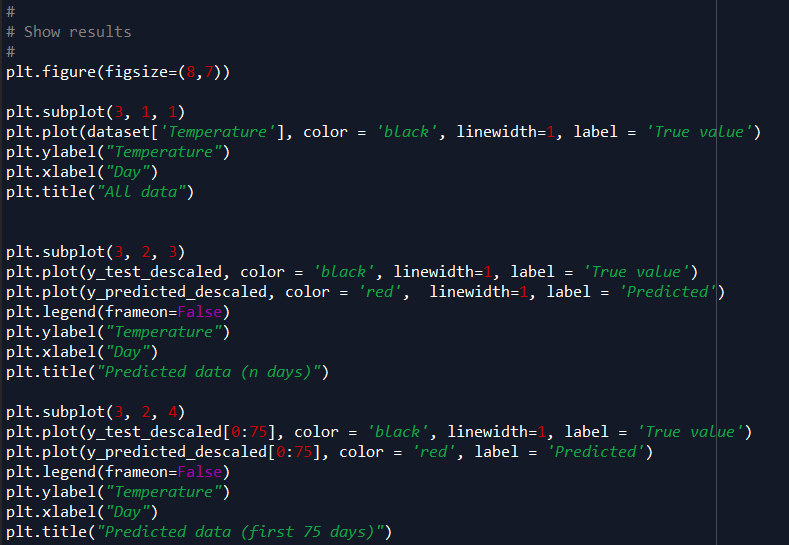
The training curve, residual plot, and the scatter plot are shown using these codes. We also included the MSE and r2 as a reference to the results.

Results
If you used our default parameters, we can see the following results:
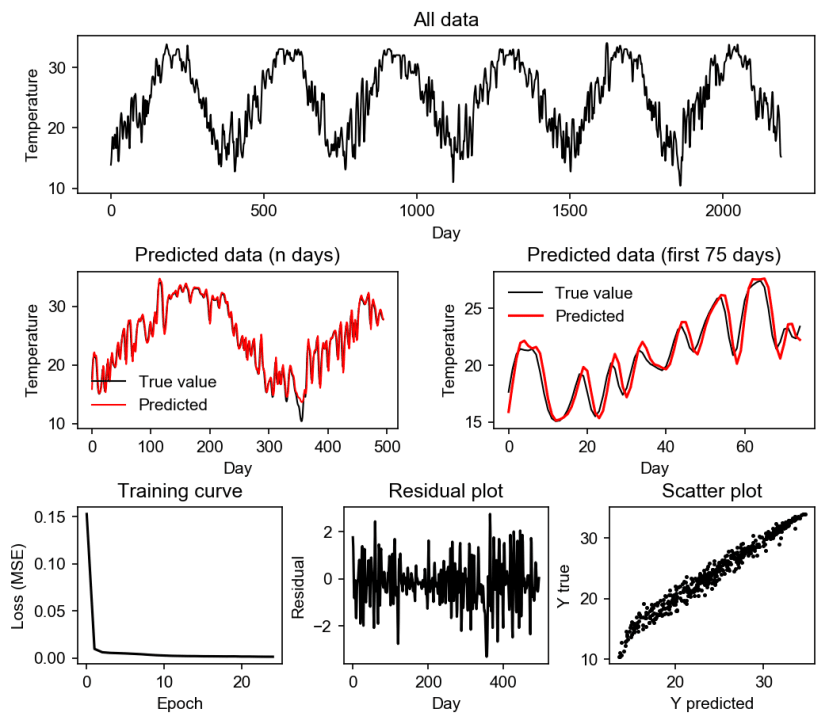
Figure 1. Stacked LSTM prediction results with a filter using 10 input days.
From the results, we can see that our model prediction was successful. However, it can be observed from the predicted (n days) that the errors are usually from the unexpected rise or decline in the data such as in days 350-360. But, based on the first 75 days, the model can properly follow the pattern of the data.
But to try to tune our LSTM model, we also ran the program using different parameters:

It can be seen from the table that the Stacked LSTM performed best compared to the other types. We can also see that the single-cell worked great using 100 input days but we found that this kind of set up was too computationally expensive. The bidirectional LSTM also performed worse with more input days.
Finally, we want to prove that conditioning the data is really important in performing LSTM. We find this reasonable if and only if the prediction should not be 99.9% accurate such as if we want to predict a volcanic eruption or such. Instead, we only want to predict the temperature in this project. To prove our point, here are the results without filtering:
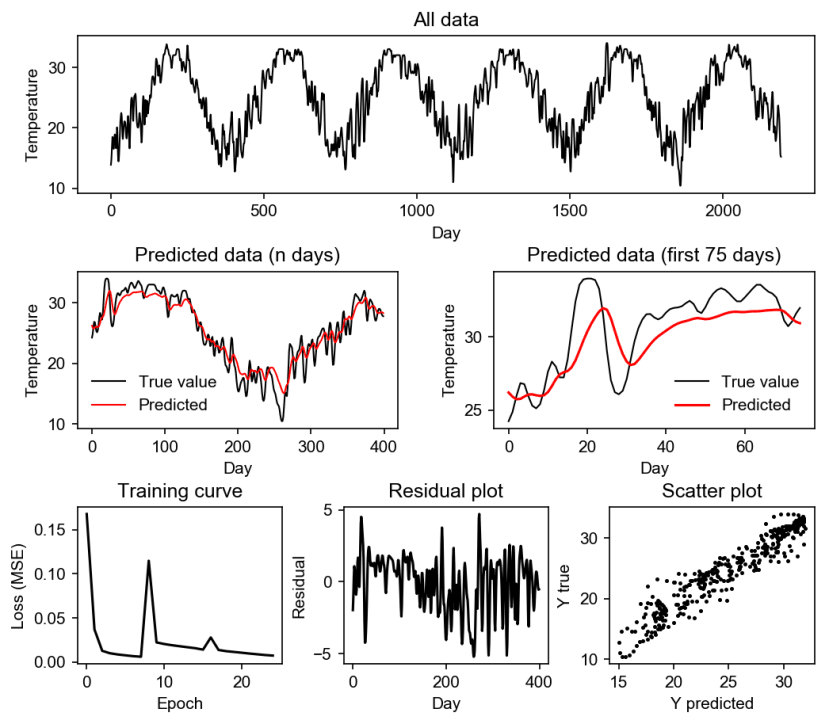
Figure 2. Stacked LSTM prediction results without a filter using 10 input days.
We can see that if there was no filter used, the LSTM model can only follow the pattern, but the error margin is larger. The results are still indeed, a little bit reasonable but it is not too exact. Here are the results of quantitatively comparing the results:

Summary
In this project, we found that LSTM is a good tool for predicting data. However, we can see from here that there are several things to take home as lessons in using LSTM. First, more input days does not really mean that the model will be more accurate. Other than that, data conditioning may help in making the model more accurate. Lastly, even though we haven’t shown, LSTM needs a certain amount of data to be applied. From there, we can imagine that LSTM can be used for predicting stocks, weather, trends, and a lot more.
Github:
https://github.com/danrustia11/WeatherLSTM
References:
https://colah.github.io/posts/2015-08-Understanding-LSTMs/
https://www.kdnuggets.com/2018/11/keras-long-short-term-memory-lstm-model-predict-stock-prices.html
https://bhrnjica.net/2019/04/08/in-depth-lstm-implementation-using-cntk-on-net-platform/