Object Tracking using Computer Vision and Raspberry Pi
Follow article
 Dave from DesignSpark
Dave from DesignSpark
How do you feel about this article? Help us to provide better content for you.
Dave from DesignSpark
Thank you! Your feedback has been received.
Dave from DesignSpark
There was a problem submitting your feedback, please try again later.
Dave from DesignSpark
What do you think of this article?
Raspberry Pi projects have been a blind spot on my radar for a while now but having discovered the conveniences of the model 3 environment, it seemed like a good time to explore it a bit more. For this article, I will be investigating the capabilities of computer vision technology through the DesignSpark Raspberry Pi Camera which has a super 220-degree wide-angle lens!
Having a camera that can monitor an entire hemisphere makes for a perfect computer vision project by using the sensor to scan large environments quickly and efficiently. Wide-angle cameras are often used in autonomous navigation systems to identify key objects and road-markings. This is a topic that strikes my interest, hence I will be aiming to acquire and track select objects with the intent to create a similar system.
The specific aim for the project is to create a system to track the relative location of a specified object in both Cartesian (X, Y) and Polar (Angle, Magnitude) coordinate systems, based on the object's location within the captured frame. This orientation data will then be used later for basic navigation applications with the use of a moving waypoint marker.

Raspberry Pi with Pi Cam module
For this project, I will be using the OpenCV framework, an open source computer vision library and documentation in both C, Java and Python. Although not my first choice, I will be using Python, as the shell makes it very easy to develop projects fast in the terminal. The bash command terminal also makes the library and prerequisites easy to download onto Linux distributions such as Raspbian. However, having also played with the Java libraries for Android I can say it feels more robust and reliable but may take more time to start initially.
I would recommend installing the Python SimpleCV framework which is a more user-friendly front-end library based on OpenCV so you can pick and choose what level you want to work at. Tutorials on how to do this are on the SimpleCV GitHub repository. However, for this project, I have exclusively used OpenCV functions due to the requirements of the system.
There are a number of approaches when it comes to object recognition, colour-space filtering, Histogram of Orientated Gradients (HOG) as well as more complex deep-learning neural network systems. I won’t pretend to be an expert on HOG or neural network algorithms, but conveniently for this project colour-space filtering will work the best as we will be looking for vividly coloured spheres for our camera to acquire and track.

A stress-ball as a spherical acquisition target
With colour filtering, it is important to understand how colour changes with different light intensities. In a constantly well-lit room, the standard Red, Green, Blue or "RGB" colour encoding is usually sufficient but in dynamically changing lighting-environments colour filtering becomes very difficult. In these situations, Hue, Saturation, Value or "HSV" colour-space encoding is more effective because the base colour is encoded independently of ambient light-level, hence we can use the hue and saturation to identify in absolutes the colour of our object, while generally disregarding the luminosity value from the environment.
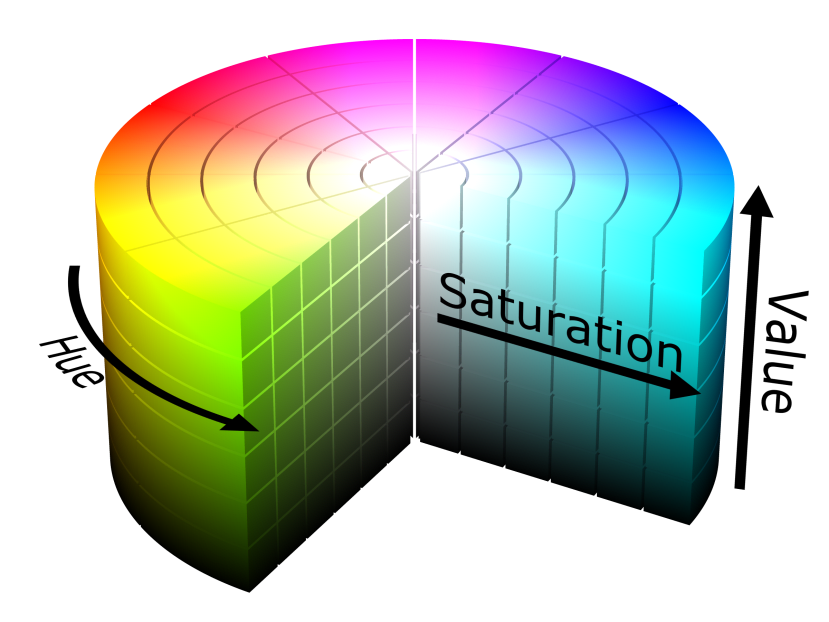
HSV colour-space illustration
By using the chosen camera to initially find the hue and saturation ranges of our object in HSV colour-space we can then start to define a filter to process each captured frame from the camera feed. By choosing an upper and lower threshold value we can identify our object in the image and mask everything else. Our output image should then contain our object, projected on a blank background.

HSV colour-space object filtering of the target with small unfiltered artefacts
We now have useful data in our camera frame for us to identify our object. It would be easy to simply identify any unfiltered pixel artefacts in our frame as the target, however for us to have a reliable system we must also minimise the possibility of any “false positives” (a common term in computer vision) such as any background objects with a similar colouration that may confuse the system.
To minimise this possibility, it is best to choose a target that is easy to discriminate. The ideal target would have an unnatural colouration with a very high saturation value such as fluorescent pink or neon green; of course, the best colour to use will also depend on your operating environment.
The other way to minimise false positives is to use primitive shape-profiling. In this specific case, we will be using a spherical target so we can make use of the circle finding functions available in OpenCV to identify our object amongst the remaining artefacts in the captured frame.

Acquiring the target (green ring) and extracting the centre-point co-ordinates (red dot)
With our target identified with a reliable level of filtering, we can start to quantify its location in the 2D space of the captured frame. The OpenCV "HoughCircles" function lets us find a number of properties about our object which are defined as an array of three values X, Y, and Radius.
The X and Y values directly give us our Cartesian co-ordinate axis values in raw pixels, we can then normalise these values using the total width and height of the frame to give a useable index from -1 to 1 and a normalised radius of 0 to 1. Normalising the values makes the code more usable for different camera resolutions as well as making the X, Y axis more mathematically useful.
The Cartesian X, Y position of our target in the frame can be used immediately if desired, however, we may want to transform the coordinates into a more useful plane e.g. for vehicle navigation, which would use angle and magnitude to identify surrounding obstacles in a Polar coordinate system.
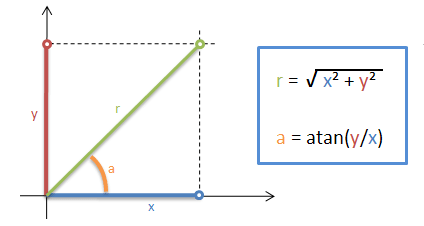
X, Y Cartesian axis transformed to an (angle), r (magnitude) Polar coordinates. The Polar transform is easy to accomplish by importing the Python "math" module and using the above equations.
With our super wide-angle camera facing directly upwards, scanning the overhead hemisphere, we can now gauge the bearing-angle of an object with reference to a straight ahead position e.g. the front of a robot or vehicle; we can then determine which direction to steer and whether to follow or avoid it.
With our newly found object bearing angle, we can now estimate the target's range using the measured radius value and deriving an equation. We can find this by manually collecting range vs radius data-points from the camera and calculating the gradient. Conveniently Microsoft Excel can do this for us - in this instance, the function is non-linear as you might expect.
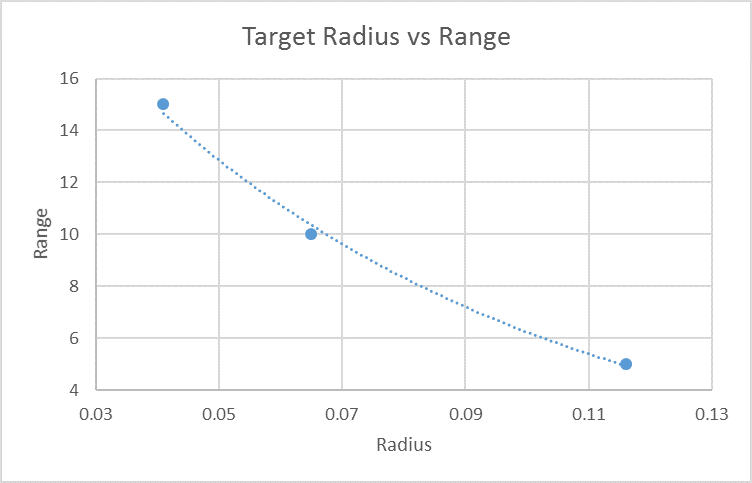
Simple data-set graph, where the range is in centimetres and radius is in normalised pixels
With the target reliably identified and its position within the camera's viewing hemisphere fully quantified, this process can now be utilised as part of a larger application environment e.g. I have already used a similar system to monitor vehicle registration plates from a fixed position. This idea could also be applied remotely as part of a primitive autonomous robot or self-driving system, which I will explore in a different article...
The source code for this project can be found on GitHub.
Click here to learn more about the DesignSpark range of Raspberry Pi camera modules and lenses