NVIDIA Jetson Nano机器学习应用-你戴口罩了吗?结合Line通讯平台进行实时监控
关注文章
 戴夫来自 DesignSpark
戴夫来自 DesignSpark
你觉得这篇文章怎么样? 帮助我们为您提供更好的内容。
戴夫来自 DesignSpark
Thank you! Your feedback has been received.
戴夫来自 DesignSpark
There was a problem submitting your feedback, please try again later.
戴夫来自 DesignSpark
你觉得这篇文章怎么样?
|
作者 |
张嘉钧 |
|
难度 |
普通 |
|
材料表 |
关于IFTTT
IFTTT 的全名为「If This Then That」,及是触发了A事件之后就会做出B动作,基本上不用写程序,也可以有几百个服务可以进行串接,目前有三个免费API的额度,如果使用三个以上的API就要开始收费了。
厘清思绪
在开始之前先来确认一下本次目标,我们希望当辨识到特定物品的时候使用LINE进行实时通知。以IFTTT的角度来说就是「if 辨识到东西 then 传送讯息到Line」,但是IFTTT没办法进行AI辨识,必须透过工具:Webhook, Webhook的功能是当特定网页有被触及的时候就会提醒对方,我可以在辨识到特定物品的时候触及特定网页并且上传数值,这时候Webhook会收到回馈,启动Line的传送讯息功能,而Line的传送讯息功能也可以接收刚刚上传的数值。
申请IFTTT & 创建Applet
1.进入IFTTT首页,选择登入账号或申请新账号

2.请选择一种账号进行登入

3.右上角选择选择Create新服务

4.点选Add,进入服务设定。

5.搜寻 Webhooks 服务并点选该图示

6.点击 Receive a web request

7.创建事件名称并点击Create trigger 启动输入触发。
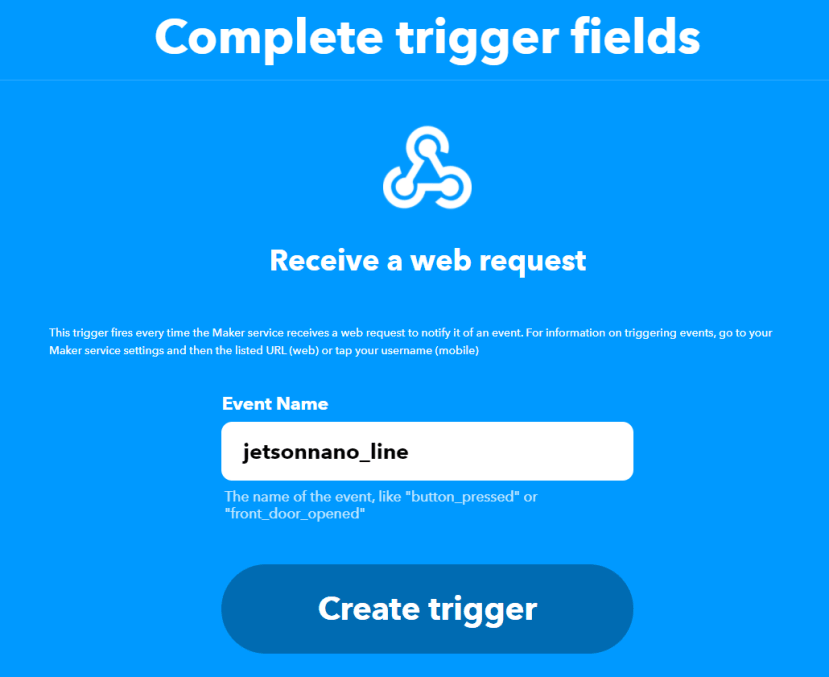
8.接着点击Then That 的 Add。

9.搜寻Line并且点击LINE的icon
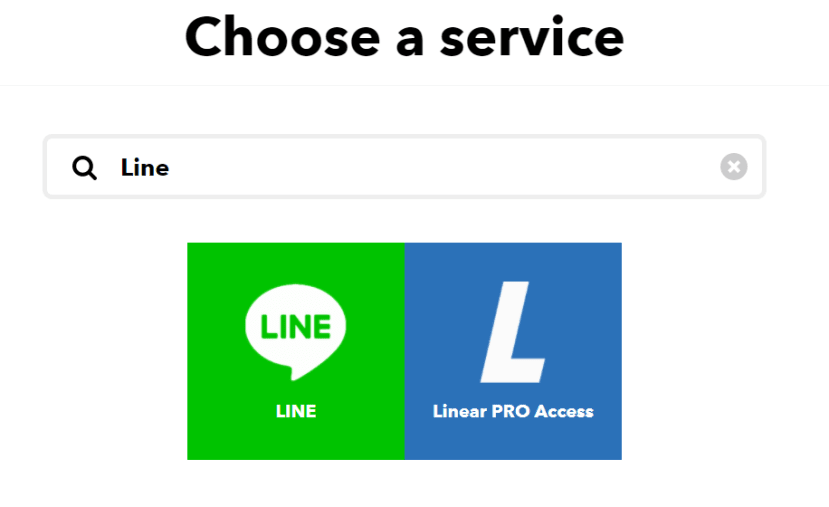
10.点击Send Message

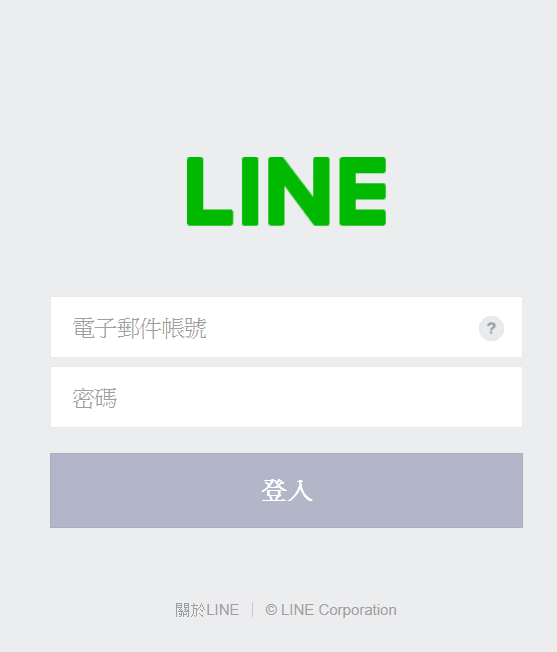
11.因为要连接到 LINE,需要进行登入LINE 的动作。
12.IFTTT透过 LINE Notify 的通知进行推播,选择同意并连动。
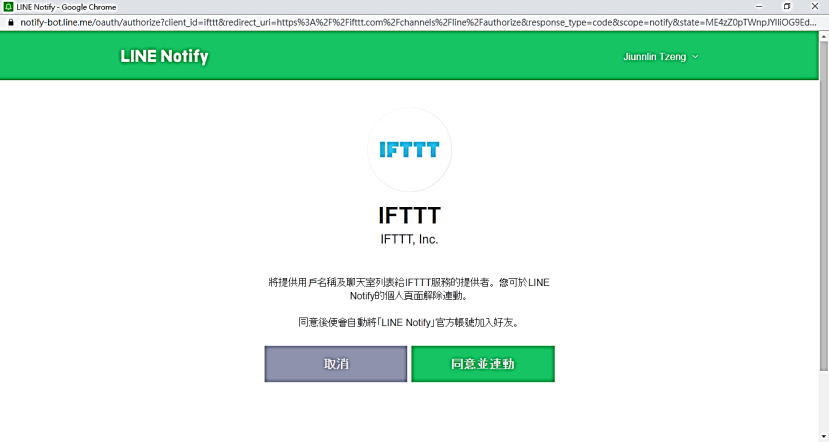
连动后会在LINE上弹出这段讯息

13.设定传送 LINE 讯息的内容
可以选择要推播到特定群组,或是一对一的 LINE Notify,再来是讯息格式,1个 Webhooks 可以传送3个数值,后续会教大家怎么修改。

14.点击 Continue

15.输入app的标题简述,接着可以按Finish
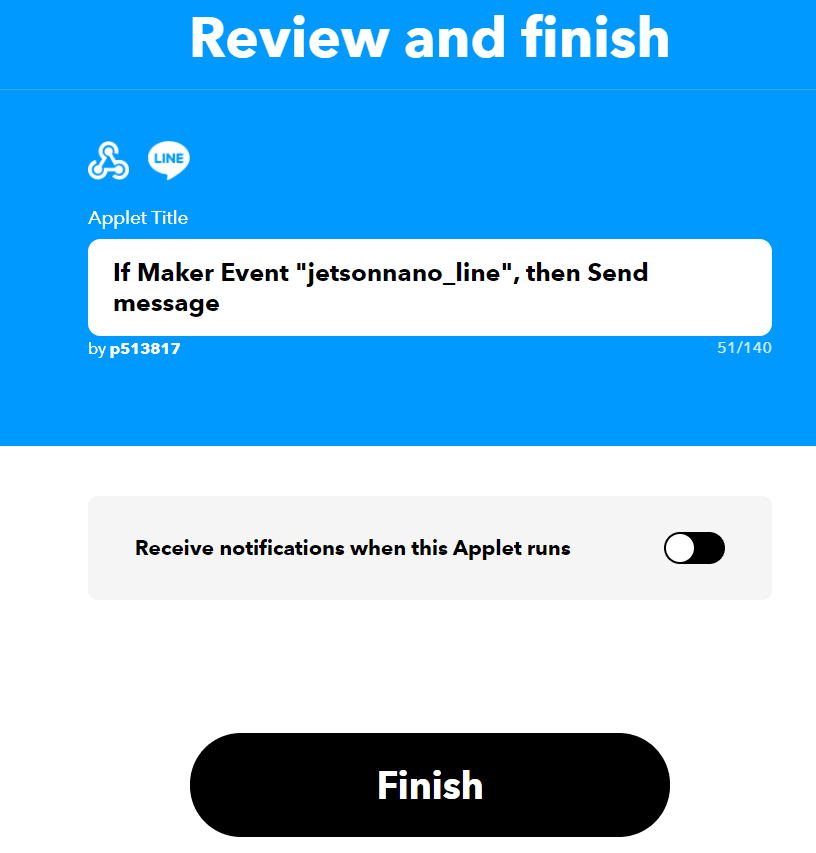
16.完成之后的画面如下,接着要点击Webhook的图标
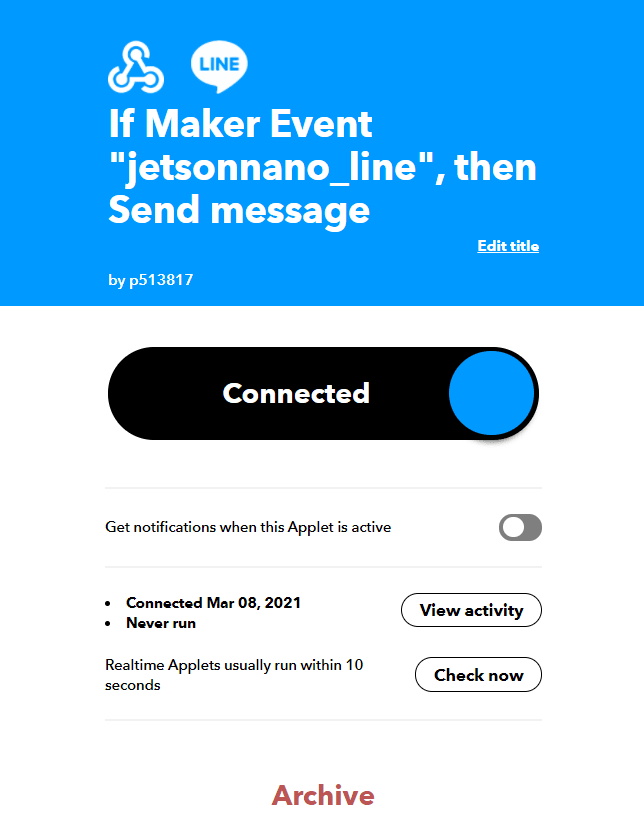
17.点击左上角的IFTTT图案回到首页,并且点击Create by me就可以看到刚刚创建的APP

18.点击右上角的 Documentation

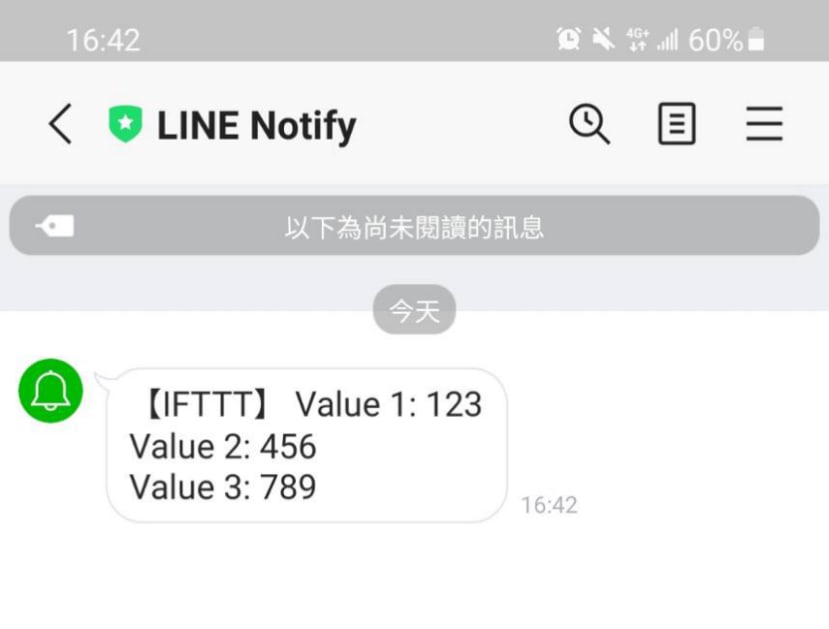
19.进到文件状态后修改内容进行测试,event字段为刚刚Webhook创建的名称 ( jetsonnano_line ),value随意输入。

执行结果可以到 Line Notify中查看
编辑Line的讯息格式
20.回到APP的页面,点击LINE的图标

21.点击 jetsonnano_line 的app方框
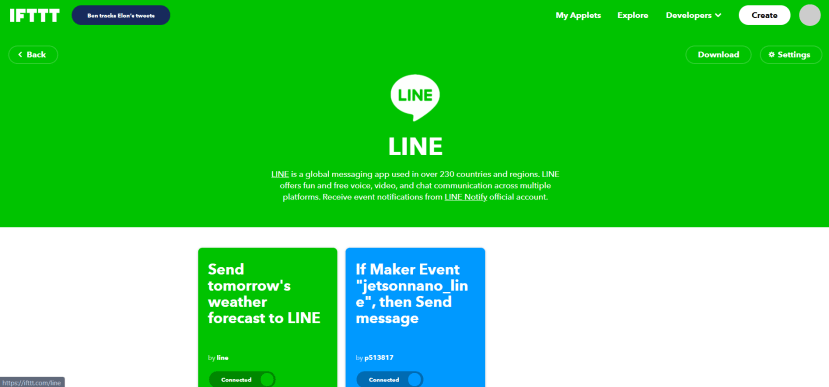
22.点击右上角的setting

23.选择Send Message右上角的edit

24.修改讯息信息,变量可以从 Add ingredient选取,有EventName、三个Value以及 OccurredAt ( 最近的时间 ) 可以选择。

25.回到Webhook的Documentation测试一下结果

到目前就已经完成基本的IFTTT设定了。
使用Python程序连动Line
解析Webhook
开始之前我们先解析一下刚刚在Webhook的Documentation。
Make a POST or GET web request to:
代表我们可以使用POST或GET的方式去触及Webhook,其中GET通常是下载网页信息而POST则是上传数据,但是在这边事都可以通用的。

With an optional JSON body of:
他可以使用自定义的参数但是需要使用JSON格式的内容,强制使用类似Python的字典形式,Key的位置是固定的所以写程序的时候要注意,Key后面的内容则是可以随机定义的,而这部分就是可以更换成我们辨识的结果。

对这些参数稍微有一点概念了之后就可以开始写程序啰!
实作Python Code
这边需要使用到Python的套件 Request,来完成与网页互动的功能。首先,我们先撰写了一个副函式叫「send_to_webhook」,并且给予所有能够修改的参数,像是网址的部分就要包含「事件名称」、「密钥」,而后面的自变量总共有三个「数值」;利用post或get都可以只要能触发Webhook的事件即可,我们可以使用”status_code”做个判断,如果成功的话会回传response 200,也可以直接使用“codes.ok”。
import requests
def send_to_webhook(event='', key='', val_1='', val_2='', val_3=''):
trg_url = ('https://maker.ifttt.com/trigger/{event}/with/key/{key}'.format(event=event, key=key))
trg_params = {
'value1': f'{val_1}',
'value2': f'{val_2}',
'value3' : f'{val_3}'
}
req = requests.post(trg_url, trg_params)
if req.status_code == requests.codes.ok:
print('传送成功')
else:
print('传送失败')
接着就可以在外部修改参数了:
if __name__ == '__main__':
event = 'jetsonnano_line'
key = 'i3_S_gIAsOty30yvIg4vg'
val_1 = '使用'
val_2 = 'Python'
val_3 = '连动'
ret = send_to_webhook(event, key, val_1, val_2, val_3)
我们执行程序测试一下,可以看到LINE有确实收到讯息:

结合简易的AI辨识
这部分可以结合各种形式,像是YOLOv4、Jetson Inference等API,在稍微修改一下即可,这边我提供一个更简单且我们常用的方法 Teachable Machine,这边就不介绍太多了,他是一个在线的AI体验工具。
除了在线训练之外还可以提供Tensorflow、Tensorflow Lite以及Coral的模型,这边我顺便教大家怎么去安装 Tensorflow以及Tensorflow Lite。
使用Teachable Machine训练
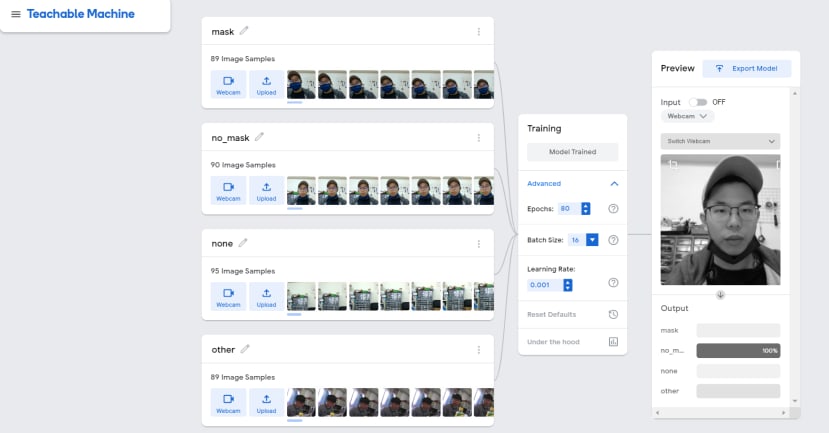
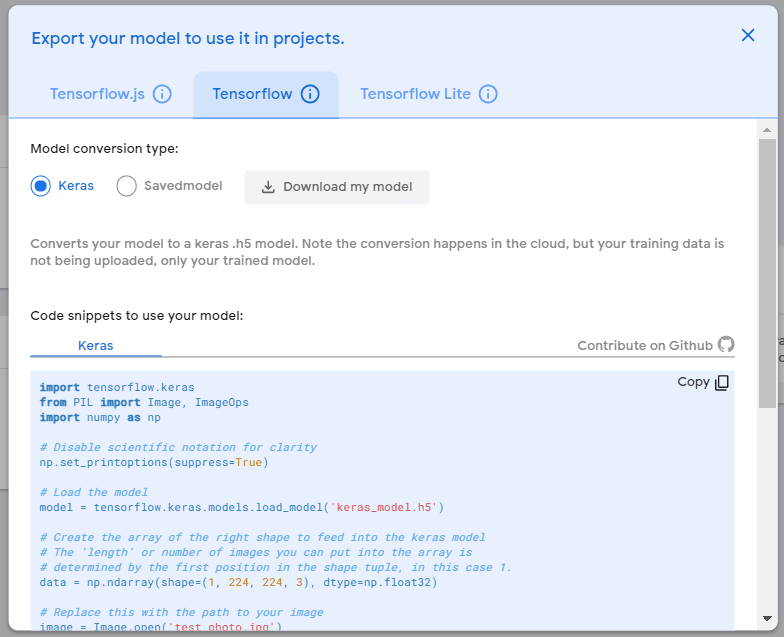
导出Tensorflow模型
我们直接使用Keras模型即可,选择Tensorflow并选择Model conversion type为Keras,点选Download my model即可进行转换与下载:
在JetsonNano中运行实时影像辨识
首先需要安装Tensorflow,我们可以直接到这里照个原厂推荐的方法操作,由于我的Nano 是JetPack 4.4.1,所以要找到 Python3.6 + JetsonPack 4.4的位置:
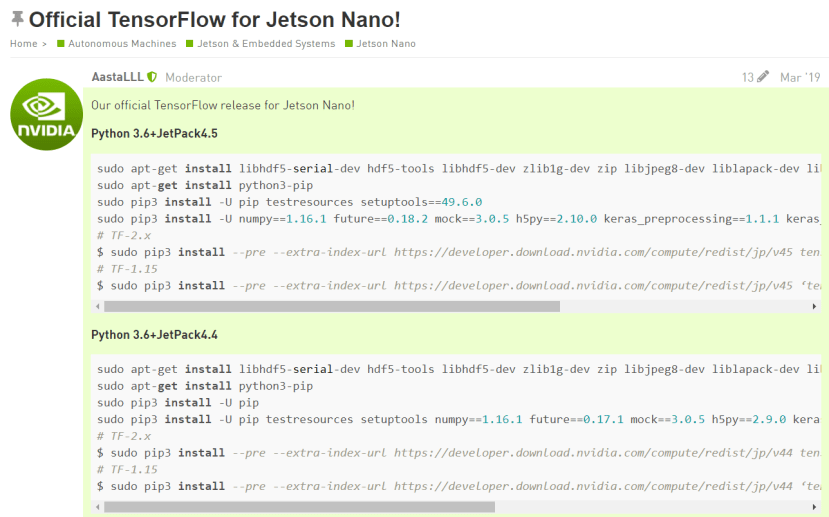
快速参考指令如下:
$ sudo apt-get install libhdf5-serial-dev hdf5-tools libhdf5-dev zlib1g-dev zip libjpeg8-dev liblapack-dev libblas-dev gfortran
$ sudo apt-get install python3-pip
$ sudo pip3 install -U pip
$ sudo pip3 install -U pip testresources setuptools numpy==1.16.1 future==0.17.1 mock==3.0.5 h5py==2.9.0 keras_preprocessing==1.0.5 keras_applications==1.0.8 gast==0.2.2 futures protobuf pybind11
# TF-2.x
$ sudo pip3 install --pre --extra-index-url https://developer.download.nvidia.com/compute/redist/jp/v44 tensorflow==2.3.1+nv20.12
安装完之后我们需要使用Teachable Machine导出的位置下方有提供范例程序,我稍微修改了一下。首先加载相关套件:
import tensorflow.keras
import numpy as np
import cv2
import time
import platform as plt
由于标签文件是一个文本文件,我写了一个程序去解析内容并储存成一个字典:
def get_label(label_path):
label = {}
with open(label_path) as f:
for line in f.readlines():
idx,name = line.strip().split(' ')
label[int(idx)] = name
return label
接着进入主程序,设定np显示的格式、加载神经网络模型与卷标;data是设定输入数据形状 (1, 224, 224, 3);最后fps用来计算实时影像每秒会有几帧,通常fps越高越好,到了60对于人眼就几乎感受不到延迟了;cap是储存摄影机设备:
print('Setting ...')
np.set_printoptions(suppress=True)
print('Load Model & Labels ...')
model = tensorflow.keras.models.load_model('keras_models/model.h5')
label = get_label('keras_models/labels.txt')
data = np.ndarray(shape=(1, 224, 224, 3), dtype=np.float32)
print('Start Stream ...')
fps = -1
cap = cv2.VideoCapture(0)
使用While不断读取最近一次的影像;t_start用于计算fps;使用cap.read()会获取两个参数,第一个通常被用来代表是否撷取成功 ( 布尔值 ),第二个则是影像数组;接着将图片丢入模型前还需要进行前处理,缩放大小至224x224,正规化,以及修改成输入数据的格式:
while(True):
t_start = time.time()
ret, frame = cap.read()
size = (224, 224)
frame_resize = cv2.resize(frame, size)
frame_norm = (frame_resize.astype(np.float32) / 127.0) - 1
data[0] = frame_norm
接着使用predict即可完成推论,我们先取得到数值最大的字段idx,并设定预计要显示在画面上的信息 (result) 再使用 putText将信息绘制到影像上,最后显示出来 (imshow),标题可以自己修改;当按下q的时候可以离开,最后释放摄影机对象并删除所有窗口:
prediction = model.predict(data)[0]
idx = int(np.argmax(prediction))
result = '{} : {:.3f}, FPS {}'.format(label[idx], prediction[idx], fps)
cv2.putText(frame, result, (10,40), cv2.FONT_HERSHEY_SIMPLEX, 1, (0 , 0, 255), 1)
cv2.imshow(win_title, frame)
if cv2.waitKey(1) == ord('q'):
break
fps = int(1/(time.time() - t_start))
cap.release()
cv2.destroyAllWindows()
print('Quit ...')
执行结果如下:

可以看到FPS只有4,不过准确度还蛮高的!但是TensorFlow在JetsonNano上开启需要一段时间,所以我会推荐转换成TensorRT的形式,下篇会再介绍。
将辨识结果传送给Line
刚刚程序当中已经取得了结果 ( results ),我们只需要将这个结果上传到Line即可,稍早我们写的ifttt程序将其储存为ifttt.py方便导入,首先设定事件名称与密钥,status用来手动设定辨识结果对应的传送内容;pre_idx则是用来储存前一个辨识的结果:
import ifttt
def main(win_title='test'):
# 设定「Line讯息」信息
event = 'jetsonnano_line'
key = 'i3_S_gIAsOty30yvIg4vg'
status = { 0:['是本人', '确定有做好防疫工作'],
1:['是本人', '注意,已成为防疫破口'],
2:['离开位置', ''],
3:['非本人', '注意您的财产'] }
pre_idx = -1
接着将程序代码放到prediction的后面,send_to_webhook详细说明请往上翻找:
# 判断是否跟上次辨识一样的结果,如果不同则进行上传
if pre_idx != idx:
ifttt.send_to_webhook( event,
key,
'环境变动',
status[idx][0],
status[idx][1] if status[idx][1] else '')
pre_idx = idx
执行结果
可以注意到如果没有传送数据的时候,FPS都还可以落在4左右,一旦传送数据就会整个
结论
我们已经学会怎么将JetsonNano与Line结合的方式了,下一篇我们将带大家尝试去将整个影像体验的效果提升。