在NVIDIA Jetson nano 上執行深度學習範例:影像辨識、物件偵測、影像分割
关注文章
 戴夫来自 DesignSpark
戴夫来自 DesignSpark
你觉得这篇文章怎么样? 帮助我们为您提供更好的内容。
戴夫来自 DesignSpark
Thank you! Your feedback has been received.
戴夫来自 DesignSpark
There was a problem submitting your feedback, please try again later.
戴夫来自 DesignSpark
你觉得这篇文章怎么样?
一、深度學習介紹
深度學習是機器學習的一種,機器學習是讓機器可以自我學習,透過將資料處理讓機器有人工智慧。而深度學習就是是機器學習的一種方式,它可以讓電腦像有了神經網路一樣,進行複雜的運算,運用各種演算法運算呈現出像人一樣的判斷或行為,例如之前很紅的AlphaGo打敗圍棋冠軍、照片人臉偵測標記等等應用都是深度學習的應用。
以下就是我們使用Jetson nano執行jetson-inference範例的畫面截圖

二、jetson-inference相關軟體安裝
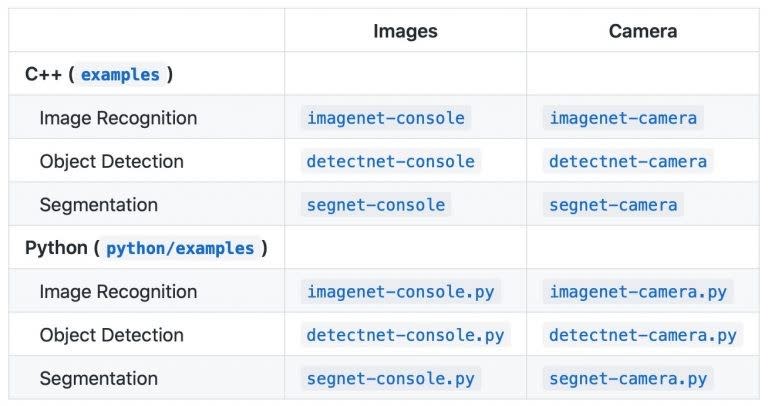
我們使用NVIDIA提供的jetson-inference範例,其中包含了影像辨識 (Image Recognition)、物件偵測 (Object Detection)、以及影像分割 (Segmentation)。它是使用TensorRT來將神經網路部屬到Jetson nano上。jetson-inference它可以使用C++ 或 Python來跑我們的範例,以下我們都使用Python來介紹。
我們使用之前文章所使用的官方提供的映像檔來安裝此jetson-inference範例的相關軟體。
我們使用之前介紹過的MobaXterm來遠端連線安裝相關軟體
Step1 輸入以下指令取得遠端更新伺服器的套件檔案清單(此指令需要輸入使用者密碼請輸入你設定的密碼,如果是按照之前教學皆設定為jetsonnano)
sudo apt-get update
Step2 輸入以下指令安裝git、cmake套件、Python 3.6開發包(如果已經安裝過會顯示已安裝)。
sudo apt-get install git cmake libpython3-dev python3-numpy
Step3 使用git下載jetson-inference專案程式
git clone --recursive https://github.com/dusty-nv/jetson-inference
Step4 移動到jetson-inference資料夾
cd jetson-inferenceStep5 創建build資料夾並移動到該資料夾
mkdir build
cd build

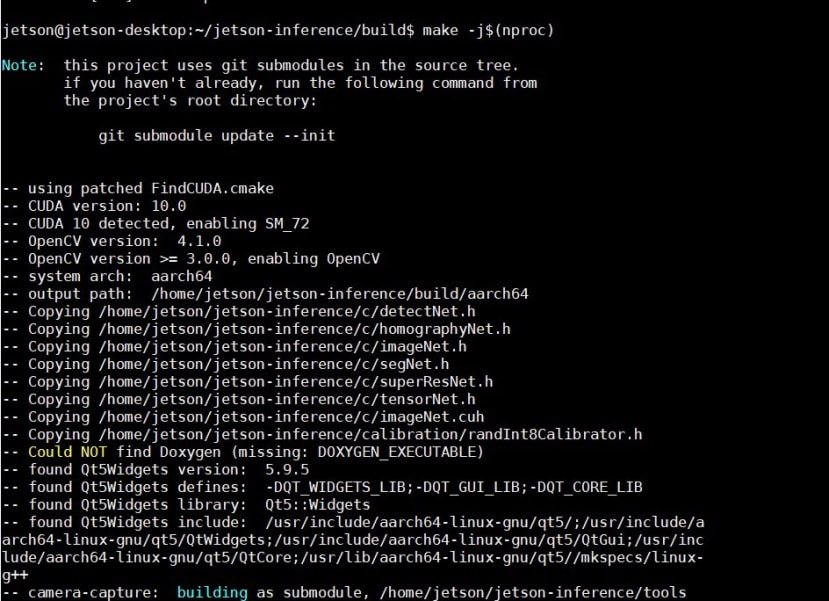
Step6 接著使用CMake來準備編譯所需的相依套件
cmake ../編譯到一半時會問你要下載甚麼模型,以下是TensorRT有支援的模型,如果選擇全部檔案下載需要一些時間,可以根據你需要的模型選擇下載或是使用下面預設的模型來下載。

選擇需要下載的模型
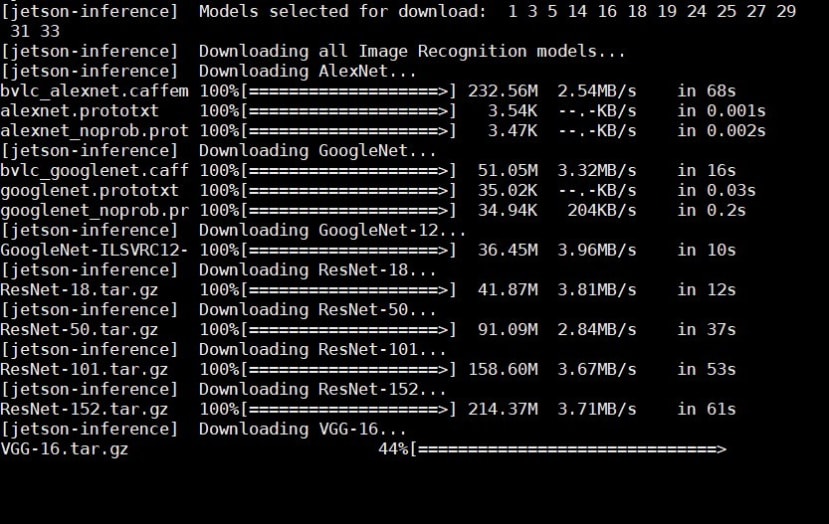
下載的過程
下載完模型後會詢問另外一個是否下載Python的PyTorch軟體包,這裡我們選擇安裝Python 3.6的PyTorch軟體包版本。

Step7 使用make編譯程式碼

編譯中
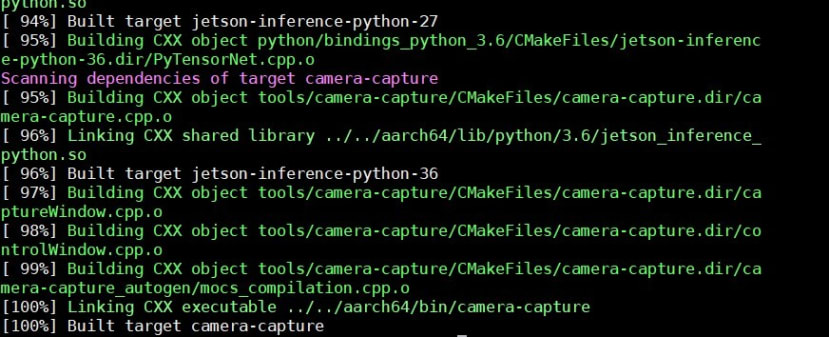
編譯完成
Step8 執行sudo make install
最後完整的輸出檔案將會在 jetson-inference/build/aarch64 這個資料夾中, 接下來所有要執行的範例程式都存放在 jetson-inference/build/aarch64/bin 資料夾中。
安裝中

安裝成功時可以看到bin底下有要執行的範例程式
三、影像辨識 (Image Recognition)
範例分成可以應用在靜態影像上(Images)或是攝影鏡頭的串流影像上(Camera)的辨識。
Step1 我們先將工作目錄移到以下範例資料夾中
cd ~/jetson-inference/build/aarch64/bin首先來辨識靜態影像上的範例程式:imagenet-console.py
Step2 呼叫影像辨識範例來辨識NVIDIA提供的影像
NVIDIA提供的影像預設路徑是jetson-inference/data/images/
可以看到下面有很多圖片可以供你測試使用,也可以使用自己的圖片來測試,以下我們使用black_bear.jpg來測試

NVIDIA提供的影像預設路徑
下指令呼叫靜態影像辨識程式時格式如下:(影像預設路徑如上圖)
./imagenet-console 要辨識的影像路徑及檔名 辨識影像結果的路徑及檔名
執行以下指令來辨識範例中黑熊的圖片black_bear.jpg, 然後將辨識完的結果儲存為 black_bear_ima.jpg。(辨識完的結果圖片儲存的目錄預設在jetson-inference/build/aarch64/bin裡面)
./imagenet-console black_bear.jpg black_bear_ima.jpg第一次跑的時候,需要等待幾分鐘,因為TensorRT會花上些許的時間來最佳化這個網路,之後再次執行程式就會快很多。



原圖

辨識結果98%為美洲黑熊、黑熊
Step3 接著是攝影鏡頭的串流影像上(Camera)的辨識(注意這使用攝影機時的操作畫面需要在Jetson nano上接螢幕才可以看到鏡頭的畫面遠端連線操作時則無法顯示鏡頭的畫面)
在本篇文章中統一使用Logitech 的C270 的USB Camera,所以需要將ca裡mera指定為 /dev/video0, 也就是一般USB Camera的預設位置。
執行以下指令來讓我們USB攝影機串流影像即時辨識
./imagenet-camera --camera /dev/video0執行後的結果拿取手邊可得的東西來辨識,可以發現辨識成功。



四、物件偵測 (Object Detection)
下指令呼叫靜態物件偵測程式時格式如下:
範例分成可以應用在靜態影像上(Images)或是攝影鏡頭的串流影像上(Camera)的偵測。
Step1 我們先將工作目錄移到以下範例資料夾中
cd ~/jetson-inference/build/aarch64/binStep2 呼叫物件偵測範例來偵測NVIDIA提供的影像
下指令呼叫靜態物件偵測程式時格式如下:(影像預設路徑跟預設儲存目錄同上)
./detectnet-console 要偵測的影像路徑及檔名 偵測影像結果的路徑及檔名
執行以下指令來偵測範例中飛機的圖片airplane_0.jpg, 然後將偵測完的結果儲存為 airplane_0det.jpg。(偵測完的結果圖片儲存的目錄預設在jetson-inference/build/aarch64/bin裡面)
./detectnet-console airplane_0.jpg airplane_0det.jpg使用範例圖片airplane_0.jpg的偵測結果如下,可以看到偵測出飛機這個物件並把它框起來

Step3 接著是攝影鏡頭的串流影像上(Camera)的物件偵測
執行以下指令來讓我們USB攝影機串流影像進行物件偵測可以看到以下結果

偵測結果可以看到有偵測到鍵盤、滑鼠還有手(人類)
五、影像分割 (Segmentation)
下指令呼叫靜態影像分割程式時格式如下:
範例分成可以應用在靜態影像上(Images)或是攝影鏡頭的串流影像上(Camera)的影像分割。
Step1 我們先將工作目錄移到以下範例資料夾中
cd ~/jetson-inference/build/aarch64/binStep2 呼叫影像分割範例來偵測NVIDIA提供的影像
下指令呼叫靜態物件影像分割程式時格式如下:(影像預設路徑如上)
./segnet-console 要分割的影像路徑及檔名 影像分割結果的路徑及檔名
執行以下指令來分割範例中馬的圖片horse_0.jpg,然後將分割完的結果儲存為 horse_0seg.jpg。(分割完的結果圖片儲存的目錄預設在jetson-inference/build/aarch64/bin裡面)

可以看到有分割成馬跟人兩種顏色
每種顏色所代表的物件如下圖

Step3 接著是攝影鏡頭的串流影像上(Camera)的影像分割
執行以下指令來讓我們USB攝影機串流影像進行影像分割可以看到以下結果
./segnet-camera --camera /dev/video0
分割後看到黃色的是狗 粉紅色的是貓
以上就是我們的在Jetson nano上執行Deep Learning深度學習範例的介紹與教學,大家有沒有成功的執行影像辨識、物件偵測 、以及影像分割三種範例呢?未來我們將會推出更多豐富的內容,有興趣歡迎關注我們!
資料來源&相關連結:
nvidia官網介紹Deploying Deep Learning
https://developer.nvidia.com/embedded/twodaystoademo
jetson-inference github網站
https://github.com/dusty-nv/jetson-inference
什麼是深度學習 類神經網絡的卷土重來