NVIDIA在线课程:深度影像串流-DeepStream实作解说,使用网络影像串流进行深度学习辨识
关注文章
 戴夫来自 DesignSpark
戴夫来自 DesignSpark
你觉得这篇文章怎么样? 帮助我们为您提供更好的内容。
戴夫来自 DesignSpark
Thank you! Your feedback has been received.
戴夫来自 DesignSpark
There was a problem submitting your feedback, please try again later.
戴夫来自 DesignSpark
你觉得这篇文章怎么样?
Deep Stream
在过去的项目中,我们常常在使用网络摄影机或一般的USB摄影机来做影像辨识,自己在建构模型或开发项目的时候是否有更强大以及更简单的开发工具?NVIDIA都知道大家的困难,所以它整合了一套工具叫做「DeepStream」,透过AI来分析串流媒体的信息,让用户可以更清楚环境信息,文中有提到像是城市街道上的交通跟行人;医院病人的安全跟健康;工厂中机器加工的状态,这些都可以透过DeepStream这套工具来开发。
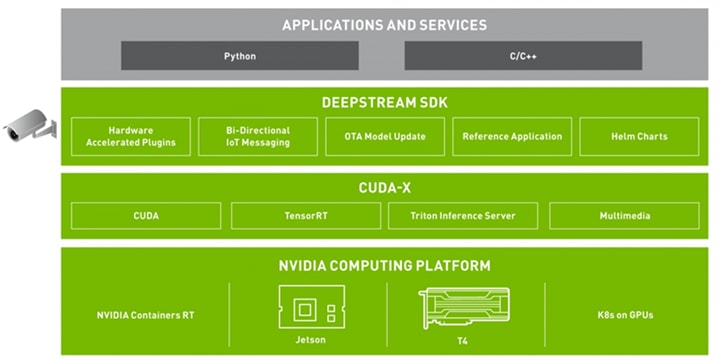
DeepStream开发上较常见是Python但是底层是由C/C++所建构而成,他们为了让使用者更容易入门,也提供了许多能够参考的应用,可以到该github去看看https://github.com/NVIDIA-AI-IOT/deepstream_python_apps。
在DeepStream中比较特别的部分除了提供安全的认证机制之外还有就是导入了TensorRT,目的是为了让数据量减少,这个部份我们将会在特别写一篇相关的技术给大家。接下来是DeepStream的架构图:
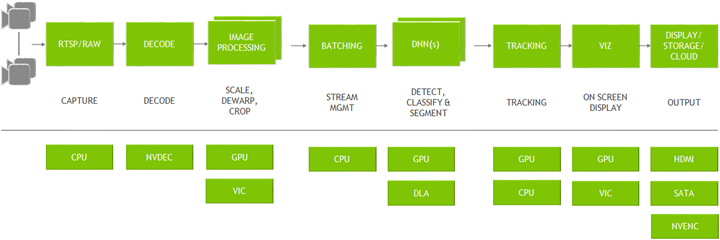
从这张图就可以看出整个运作的流程,从摄影机端获得了影像之后先进行编码跟基本的影像前处理,进行批处理以及深度神经网络的inference,VIZ是可视化的意思,神经网络模型运算结束后可能会有BoundingBox、Segmentation、Label需要显示在影像上面,最后输出的时候有提供各种储存方法,像是继续使用RTSP输出或是储存到计算机等等的。
至于分隔线以下的表示用到的工具以及技术,接下来稍微介绍一下各插件的功能,这个对于想取得DeepStream学习证明的人非常有帮助:
- 编码:使用的插件为Gst-nvvideo4linux2,技术名称叫做NVDEC
- 图像前处理:Gst-nvdewarper用于改善鱼眼镜头或全景相机;Gst-nvvideoconvert负责颜色格式转换,以上用的硬件是GPU、VIC ( vision image compositor )。
- 批处理:Gst-nvstreammux,让DeepStream能获得最佳推理。
- 在DNN的部分,提供了两种进行Inference的方法,第一种是在本地端进行TensorRT的Inference,使用的方法是GST-nvinfer;第二种是在NVIDIA提供的云端推论平台Triton,而用这个Triton技术的话是GST-nvinferserver。
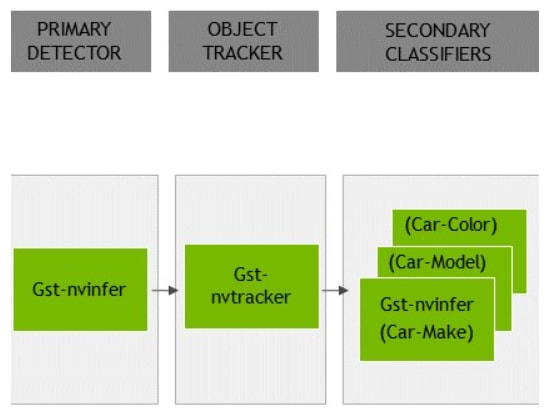
- 推论完可能还会牵扯到是否追踪对象来进行第二次的图片分类,而这边有提供Gst-nvtracker来处理这块,从高效能到高精度都可以做选择。
- 接着是可视化工具Gst-nvdsosd。
- 最后输出的时候,Gst-nvmsgconv是为了将数据上传到云端上,需要做点格式转换来减轻负载,Gst-nvmsgbroker则是为了建立跟云端的连结。

上方的图是一个针对inference流程做解释,在批处理到第二段的分类器这些都是属于神经网络的范畴,这里强调的是可以不只是做一次对象辨识,还可以透过tracker以及Secondary Classifier来进行N次辨识,最后输出一样可以放在EDGE端跟CLOUD端。
使用JetsonNano运作DeepStream范例
深刻了解DeepStream之后我们就可以开始进行实作了,以下实作内容大部分与NVIDIA课程内容相同,并且我们使用Jetson Nano 4G版本来运作。
准备Jetson Nano
下载DLI的映像档:https://developer.download.nvidia.com/training/nano/dsnano_v1-0-0_20GB_200131A.zip,并且透过Etcher刻录安装并且远程联机,可以参考此篇文章 (https://blog.cavedu.com/2019/04/03/jetson-nano-installsystem/ ),刻录后Linux系统预设帐号密码为「dlinano」,接着可以将MicroUSB接到您的计算机。
联机至Jupyter Lab
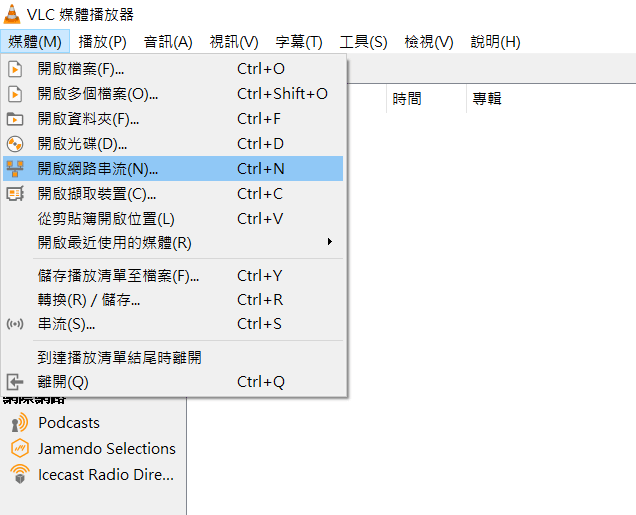
NVIDIA提供的DLI映像档已经帮我们安装好Jupyter Lab的功能,我们可以透过内网或外网远程联机至Jetson Nano,只要取得虚拟IP的地址,如果是透过MicroUSB连接统一都是192.168.55.1,而透过WIFI远程就会不太一样,像我的装置是192.168.12.152,要注意不论是哪一个IP位置都要加上端口号8888,使用方法是在IP的后方加上冒号与端口号,这样才能连动到Jupyter Lab。

输入账号密码后的画面如下,我们要使用的程序代码会放在 ~/Notebooks文件夹中:
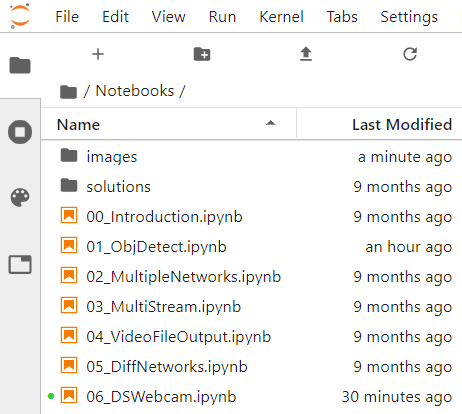
进入该文件夹后会看到NVIDIA提供的六个范例,
第一个是能够侦测串流影像中的对象 ( 人、车等等 );
第二个是透过多个网络对串流影像进行辨识,除了能够辨识对象之外还能得到车子的品牌/颜色等信息;
第三个是多个串流影像的做法;
第四个则是输出成影片,包含Bounding Box;
第五个则是透过Webcam来做实时影像辨识。
安装 & 使用 VLC
VLC是一个常见的媒体拨放器,而在Windows端下载VLC目的是要连动到JetsonNano的影像画面,因为JupyterLab无法开启JetsonNano的窗口所以影像相关需要透过网络传到VLC上,安装方法可以直接上官方网站进行下载安装。
开启VLC之后,在媒体的选项中可以开启网络串流,开启后需要输入{IP_Adress}:8554/ds-test,接下来就只要执行程序即可看到输出的画面:
01_ObjDetection.ipynb
这个范例是透过Nvidia提供的模型尝试在串流影像中进行实时的对象侦测,它能辨识的对象总共有四种1. Vehicles 2. Bicycles 3. Persons 4. Roadsigns。
实行程序的方法很简单,只需make它提供的文件夹,并且执行欲串流的影片即可,这边要注意的是它只吃h264的编码格式,如果是.mp4还需转成.264才行,这里让我困惑的点是我当初也是透过h264的编码格式输出成mp4,结果它也是不能吃…可能是两种扩展名提供的某些信息不太相同~下图为我执行西门町路况影像的结果:

在实作的部分,官方提供了两个练习给大家操作,第一个是更改Bounding Box的项目,原本四个种类都会被标注,现在它希望更改成只标注脚踏车、汽车,而你只需要更动dstest1_pgie_config.txt的部分,将其改成对应卷标数字,对于不必要出现的项目只要将threshold更改为1即可。
|
[class-attrs-all] threshold=0.2 eps=0.2 group-threshold=1 |
[class-attrs-1] threshold=0.2 eps=0.2 … |
 |
 |
第二个实作则是改变影像上面的卷标显示,在左上方可以看到有显示计算的数值,这部分的话就要去修改deepstream_test1_app.c的档案,过程比较繁杂一点。
1.定义巨集,可以想象就是给予一个变量定值

2.新增变数

3.新增判断并且增加上述变量的数值
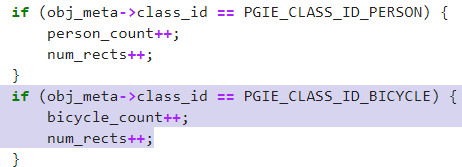
4.改变显示的内容
5.执行结果
 |
 |
02_MultipleNetworks.ipynb

它会在侦测到对象之后进行裁切接着在透过别的模型来进行更进一步的分类,相当有趣的一个范例,流程相当容易理解,进行第一次的对象辨识之后会透过tracker将该对象撷取出来进行第二次、第三次等地辅助辨识。
下图为运行的结果:

稍微学会怎么去更改这个程序吧!主要分为四个阶段:
1.Define


2.Instantiate


3.bin/link


4.Configure

5.执行结果

6.还有第三个范例是「车子的种类」,读者们可以自己去尝试看看。
03_MultiStream.ipynb

04_VideoFileOutput.ipynb
档案输出的部分就不多说了,整体操作很简单,主要在探讨如何输出、输出的画面调整、输出的文件格式。
05_DiffNetworks.ipynb
它除了内建的模型之外还提供了fasterRCNN、SSD、YOLO的模型,使用之前需要先进行下载,每个文件夹/ deepstream_sdk_v4.0.2_jetson/sources/objectDetector/ 中都有ReadMe可以查看。
06_DSWebcam.ipynb
当然最基本的开启摄影机也不会少,透过USB外接网络摄影机并且执行该程序便可以进行实时的影像辨识,在下面影片中卡顿较严重的原因除了本身inference的延迟之外也有可能是因为网络等待时间所导致,这边大家就参考看看,实际速度还是因人而异,那这个部分当然也可以使用其他模型来运作。

结语
整体而言对于DeepStream提供的一些功能还是相当强大的,因为在串流影像的部分你不只需要注意AI模型的好坏,你还需要注意相当多的数据传输与网络问题,NVIDIA将这块做好之后开发者当然就少去相当多的烦恼了,剩下的就是如何熟悉跟习惯这些工具的用法,下一篇我将会带大家认识TensorRT,以及又该如何去使用它。