NVIDIA CUDA核心GPU实做:Jetson Nano 运用TensorRT加速引擎 – 上篇
关注文章
 戴夫来自 DesignSpark
戴夫来自 DesignSpark
你觉得这篇文章怎么样? 帮助我们为您提供更好的内容。
戴夫来自 DesignSpark
Thank you! Your feedback has been received.
戴夫来自 DesignSpark
There was a problem submitting your feedback, please try again later.
戴夫来自 DesignSpark
你觉得这篇文章怎么样?
今天的内容很多所以分成了上下篇,上篇主要在讲述TensorRT的概念以及使用ONNX模型等技巧,下篇会进入TensorRT应用的部分。
Outline
|
ONNX (Open Neural Network Exchange) 結語 |
TensorRT
TensorRT是由 NVIDIA 所推出的深度学习加速引擎 ( 以下简称trt ),主要的目的是用在加速深度学习的 Inference,按照官方提出TensorRT比CPU执行快40倍的意思,就像是YOLOv5针对一张图片进行推论用CPU的话大概是1秒,如果用上TensorRT的话可能就只要0.025秒而已,这种加速是非常明显的!而这种加速大部分都是运用的边缘装置上 ( Edge Device ),由于边缘装置上的效能没有一般计算机来的好,所以往往需要这种软件加速。
TensorRT 的优化方式

图源自NVIDIA原厂文件
TensorRT主要的优化过程有这些: Precision Calibration、Layer & Tensor Fusion、Kernel Auto-Tuning、Dynamic Tensor Memory、Multi-Stream Execution,今天会介绍前两种,后面三种比较底层信息也比较少所以就先不介绍了。
降低资料精准度(Precision Calibration)
在官网上有提到trt支持INT8 和 FP16两种更简化的精度格式。神经网络模型再进行训练的时候都需要将数据转成张量 ( Tensor ),而 Tensor 的数据型态为FP32 ( 单经度浮点数 ),总共会耗费32个bit,而trt优化的FP16 ( 半经度浮点数 ) 则直接少一半,INT8又再少一半,在DLI的投影片中有提到 INT8所需的内存比FP32小了61%。但减少位数虽然可以大幅降低模型的大小,但相对而言你的精准度势必会下降,所以NVDIA也有提出了相关的解决方法。
对模型进行重构与优化(Layer & Tensor Fusion)
- 第一步先删除没有使用到的输出层
- 垂直优化:由于CUDA会在每一层输入的时候启动,而这个垂直优化就是透过将常使用的层作合并,像图中将Conv、bias、relu合并为CBR,减少CUDA启动关闭的次数来达到时间上的缩减。
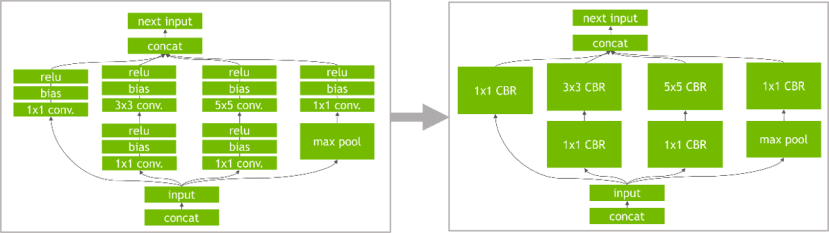
图源自NVIDIA原厂文件
- 水平优化:理论同上,如果同层其他分支也在运作一样的架构则直接合并,要注意的地方是合并成同一层之后输出必须要做分割,在输出到不同层去。

图源自NVIDIA原厂文件
TensorRT vs Tensorflow Lite
如同Tensorflow lite ( 以下简称 tflite ),他们都是用来加速的方法。他们俩者的主要差别在于trt是由NVIDIA推出的,如果使用NVIDIA的GPU来运作效果会比tflite还要快很多,但其实市面上还有很多设备是只有CPU或是没有CUDA核心的GPU,那些设备就比较适合用tflite;我们今天的主角是Jetson Nano,它最大的优势在于它拥有CUDA核心的GPU,能够进行trt加速,它将会比其他边缘装置更适合用来开发AI相关的项目。
TensorRT建构流程
- ONNX parser:将模型转换成ONNX的模型格式。
- Builder:将模型导入TensorRT并且建构TensorRT的引擎。
- Engine:引擎会接收输入值并且进行Inference跟输出。
- Logger:负责记录用的,会接收各种引擎在Inference时的讯息。
基本上TensorRT的运作都需要先转换成ONNX才行,那ONNX到底是什么东西呢?
ONNX (Open Neural Network Exchange)
好玩的地方在于ONNX的名称为Open Neural Network Exchange ( 神经网络之间的开源交流 ),所以其实从名称来看就知道,他是一个标准化神经网络模型的工具。

图源自NVIDIA原厂文件
因为现在大部分的硬件加速都是倚赖NVIDIA的GPU,几乎就是AI世界的龙头,所以其实各大框架都陆续支持trt的SDK,但是各大框架为了独特性都会推出自己的模型格式,像是 PyTorch输出模型格式为.pt、.pth而Tnesorflow输出的模型为 .h5,各种不同的文件格式对于trt来说要优化他们会很辛苦,所以ONNX推出了一个统一的模型格式 ONNX,透过ONNX的文件格式便可以导入TensorRT来进行加速;对了,目前较热门的Tensorflow也有合作哦!只是不是透过ONNX的方式来转换。
Jetson Nano安装TensorRT
安装方法有提供两种,第一种是官方的安装方法,第二种是直接安装我的映像文件,如果是体验导向我会建议直接安装我的映像档。
1. 原廠作法

https://docs.nvidia.com/deeplearning/tensorrt/install-guide/index.html#installing-tar
详细的安装步骤可以参考官方网站,要注意的是 TensorRT 7 是还没有支持 Jetson 系列的,所以可以考虑安装6。这个会耗费大量的时间,所以另一个方法是使用我提供的映像档,其中已经包含 tensorrt 以及 uff 等相关套件。
2. 我的映像档
连结如下:
https://www.dropbox.com/sh/rgxe2uf8wodb3bx/AAAcBg0QnAnZIlgaQAD63eOza?dl=0。要注意的地方用SanDisk的SD卡可能会有容量不够的问题,建议使用Samsung 64GB以上的记忆卡。
将TensorRT连结到virtualenv
$ vim ~/.bashrc
export CUDA_HOME=/usr/local/cuda
export PATH=$CUDA_HOME/bin:$PATH
export LD_LIBARY_PATH=$CUDA_HOME/lib64:$LD_LIBRARY_PATH
export PYTHONPATH=/usr/lib/python3.6/dist-packages:$PYTHONPATH
完成之后进到虚拟环境中应该就可以看到虚拟环境连结到tensorrt了。
PyTorch 汇出 ONNX
官方介绍文件连结如下:https://pytorch.org/docs/stable/onnx.html。PyTorch为了追上AI加速的NVIDIA列车,早已在框架中也包含了ONNX模型导出的函式库,但是还是需要先安装ONNX才行,基本上我们只要透过导入ONNX函式库并且透过torch.onnx.export即可导出ONNX的模型。
Torch.onnx.export
torch.onnx.export(model, args, f, export_params=True, verbose=False, training=False, input_names=None, output_names=None, aten=False, export_raw_ir=False, operator_export_type=None, opset_version=None, _retain_param_name=True, do_constant_folding=False, example_outputs=None, strip_doc_string=True, dynamic_axes=None, keep_initializers_as_inputs=None)其中model就是要转换的模型;args可以想象成是输入的维度,以 [ batch , C , H , W ]为主,这边顺道提一下也有 dynamic_axes动态输入维度的选项可以选择,默认值export_param为True所以都会导出权重值;剩下的有兴趣在去原厂的文件查看。
使用方法
使用onnx.export的方法也是非常的简单,我们使用Alexnet来当作范例,这个是取自官方的文件,可以注意到他有定义输入跟输出的名称,目的是为了后续调用方便:
import torch
import torchvision
dummy_input = torch.randn(1, 3, 224, 224, device='cuda')
model = torchvision.models.alexnet(pretrained=True).cuda()
input_names = [ "actual_input_1" ] + [ "learned_%d" % i for i in range(16) ]
output_names = [ "output1" ]
torch.onnx.export(model, dummy_input, "alexnet.onnx", verbose=True, input_names=input_names, output_names=output_names)
因为汇出的时候选择verbose=True所以会将转换的进度打印出来:

这边直接引用原厂文件的内容:
The resulting alexnet.onnx is a binary protobuf file which contains both the network structure and parameters of the model you exported (in this case, AlexNet). The keyword argument verbose=True causes the exporter to print out a human-readable representation of the network:
汇出的是一个二进制的protobuf的档案,这是一种串行化的数据结构,ONNX会依靠这种数据结构来描述模型档案,在Caffe等AI框架也都是使用一样的数据结构形式,那这个binary protobuf包含了神经网络的架构跟权重,之前在开发PyTorch的时候是被建议储存权重就好,架构要再另外写,有时候会觉得稍微有一点麻烦,但是ONNX就改善这个问题了,他只需要导入档案,模型的架构也都包含在其中不用额外建构了。
检查ONNX模型
首先我们要先安装ONNX套件:
$ pip install onnx我的结果如下,可以注意到它会连同protobuf也一起安装了。

刚刚执行完程序之后应该可以注意到档案中已经多了一个alexnet.onnx,这个就是我们汇出成功的档案,接着可以透过下列程序来确认:
import onnx
# Load the ONNX model
model = onnx.load("alexnet.onnx")
# Check that the IR is well formed
print(onnx.checker.check_model(model))
print('-'*50)
# Print a human readable representation of the graph
print('Model :\n\n{}'.format(onnx.helper.printable_graph(model.graph)))

图形化显示ONNX模型
广大的网友们都推荐使用Netron这套软件,直接透过PyPI即可安装。

透过下列程序代码可以查看图形化模型,执行完他会产生一个localhost来存放图档:
$ netron [FILE]
点击Block便可以获得相关信息:


可以看到我们当初在汇出的时候宣告了输入的维度所以这边输入维度也是显示当初设定的数值,在右侧也可以看到相关信息,包括连PyTorch的版本信息也有显示出来。
透过ONNX RUNTIME运行ONNX Model
获得到ONNX后要怎么执行呢?他自己也提供了一个平台(框架)可以运行,叫做ONNX RUNTIME ( 以下简称 ORT ),他兼容了许多硬件加速平台,像是今天的主角TensorRT,还有Intel的OpenVINO等等的,也因为ONNX模型的关系,所以他也兼融了各大平台的模型,等于说用户透过TF、PyTorch建构的神经网络模型,都可以再ORT上进行推论跟训练。
先来安装ONNX RUN TIME:
$ pip install onnxruntime
使用ORT 来进行模型的推论之范例程序:
import onnxruntime as ort
ort_session = ort.InferenceSession('alexnet.onnx')
outputs = ort_session.run(None, {'actual_input_1': np.random.randn(10, 3, 224, 224).astype(np.float32)})
print(outputs[0])
基本上有两个重点,第一个是导入需要用InferenceSession接着直接用run即可进行推论;第二个重点在于run的自变量是要用字典形式来输入,所以需要给定字典的域名并且告知输入的数值。
ORT 运行 AlexNet
开始之前我先写了一个整理显示信息的程序,文件名为log.py,特别将文字改了颜色:
import time
def print_div(text, custom='', end='\n\n'):
print('-'*50, '\n')
print(f"{text}{custom}", end=end)
class timer():
def __init__(self, text):
print_div(text, '...', end=' ')
self.t_start = time.time()
def end(self):
t_cost = time.time() - self.t_start
print('\033[35m', end='')
print('Done ({:.5f}s)'.format(t_cost))
print('\033[0m')
class logger():
def __init__(self, text):
print_div(text)
接着开启一个新档案 3_run_onnx.py将函式库以及刚刚写的log导入:
import onnxruntime as ort
import time
from PIL import Image
import numpy as np
from torchvision import transforms as T
# Custom
from log import timer, logger
先读取数据并且转换成对应格式:
trans = T.Compose([T.Resize(256), T.CenterCrop(224), T.ToTensor()])
img = Image.open('../test_photo.jpg')
img_tensor = trans(img).unsqueeze(0)
img_np = np.array(img_tensor)
logger('Image : {} >>> {}'.format(np.shape(img) , np.shape(img_tensor)))
宣告ORT的Session并且不同于范例的做法我直接取得第一层的名称,这个作法是为了避免打错字或是忘记自己当初定义的名称:
# ONNX Run Time
load_onnx = timer('Load ONNX Model')
ort_session = ort.InferenceSession('alexnet.onnx')
load_onnx.end()
# run( out_feed, in_feed, opt )
input_name = ort_session.get_inputs()[0].name
infer_onnx = timer('Run Infer')
outputs = ort_session.run(None, {input_name: img_np})[0]
infer_onnx.end()
获得结果后将卷标给显示出来:
# Get Labels
f = open('../imagenet_classes.txt')
t = [ i.replace('\n','') for i in f.readlines()]
logger("Result : {}".format(t[np.argmax(outputs)]))
运行结果如下:
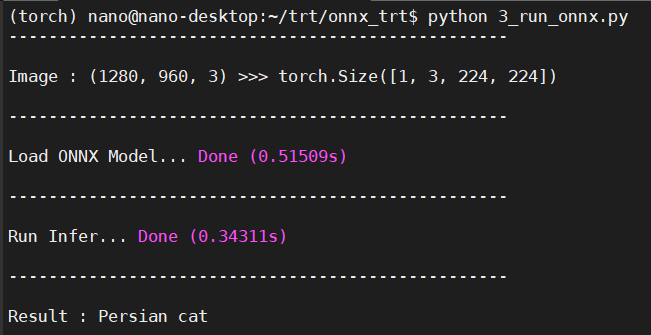
ORT运行.onnx与PyTorch运行.pth速度差异
这边我将输出的数值做了softmax缩限在 [0, 1]之间。
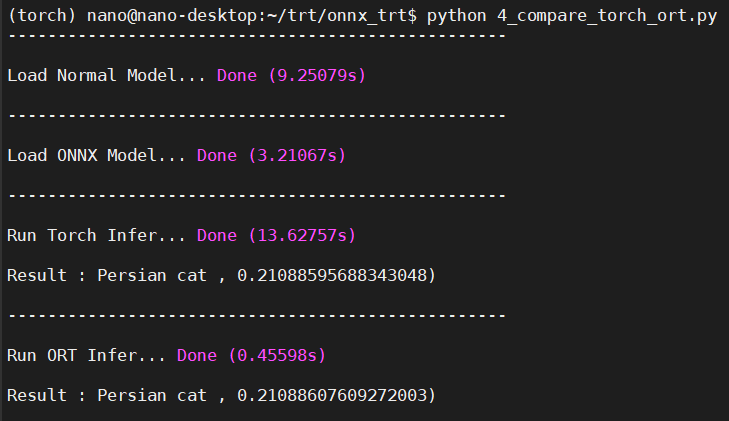
稍微整理一下,可以发现光ONNX与PyTorch模型加载速度就有显著的差异了,在Inference的时间上也有将近45倍的差距!由此可知ONNX确实能够简化模型并且加速Inference的时间,接着要使用TensorRT引擎来运行ONNX模型!
參考文章
What is the difference between tflite and tensorRT?
TensorRT-Optimization-Principle
Speeding up Deep Learning Inference Using TensorFlow, ONNX, and TensorRT