Movidius fait monter en puissance le deep learning
Suivez l'article
 Dave from DesignSpark
Dave from DesignSpark
Que pensez-vous de cet article ? Aidez-nous à vous fournir un meilleur contenu.
Dave from DesignSpark
Merci! Vos commentaires ont été reçus.
Dave from DesignSpark
There was a problem submitting your feedback, please try again later.
Dave from DesignSpark
Que pensez-vous de cet article ?

L'IA rendue possible dans les applications embarquées de faible puissance par Neural Compute Stick.
L'Intelligence artificielle (IA) est, à l'instar de l'énergie propre produite à partir de la fusion nucléaire, l'une des choses qui, depuis des décennies, est appelée à retentir profondément sur la société — et les progrès réalisés ces dernières années permettent enfin d'exploiter l'IA dans un plus grand nombre d'applications pratiques. Cependant, le problème qui se pose de longue date est que de nombreuses applications clés, telles que le traitement de la vision, sont gourmandes en calculs et excluent par conséquent la transformation locale des dispositifs de faible puissance.
Movidius — qui fait désormais partie d'Intel — est en train de changer cette situation grâce à son unité VPU (Vision Processing Unit) Myriad 2, qui offre une visibilité de machine programmable par logiciel à ultrabasse consommation.
Dans ce billet, nous allons examiner dans un premier temps la technologie VPU Myriad et son SDK connexe, et nous familiariser avec le Neural Compute Stick (NCS) qui permet le développement et le prototypage à bas coût.
100 Gflops/watt
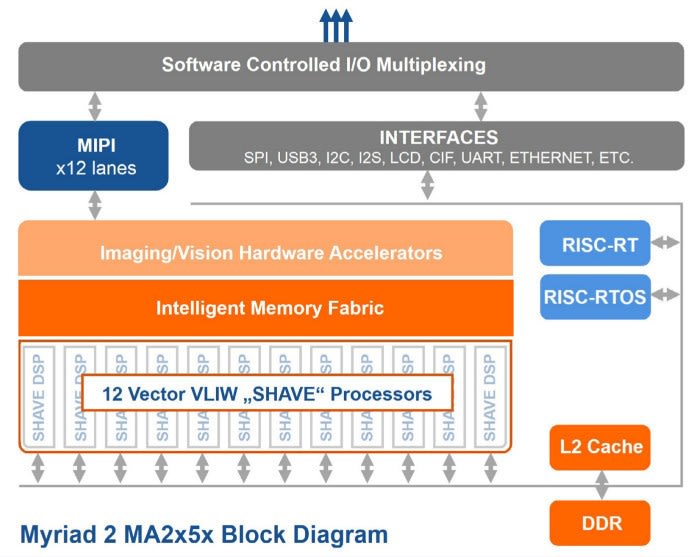
Source : Présentation du produit VPU Myriad 2 de Movidius
Le Movidius Neural Compute Stick (139-3655) offre des performances exceptionnelles pour les applications de traitement de la visibilité, de plus de 100 GFlops pour une consommation électrique d'environ 1 watt seulement, par le biais d'un système sur puce (SoC) de 600 MHz, qui intègre 12 processeurs VLIW à 128 bits regroupés dans une mémoire intégrée de 2 Mo offrant des taux de transfert de l'ordre de 400 Gbit/s.
Ses principales caractéristiques sont les suivantes :
- Prise en charge de FP16, FP32 et des opérations de nombre entier avec précision de 8, 16 et 32 bits
- Inférence sur circuit en temps réel sans connexion au Cloud
- Déploiement de modèles de réseau neuronal convolutionnel (CNN) existants ou de réseaux spécialement formés
- Toutes les données et l'alimentation sont fournies sur un simple port USB 3.0 sur un PC hôte.
Même s'il est équipé d'un port USB 3.0, le port USB 2.0 devrait convenir à de multiples usages. Notez également que pour obtenir de meilleures performances, on peut mettre en réseau plusieurs NCS via un concentrateur USB adéquat.
Prise en charge de Caffe
La prise en charge d'applications d'apprentissage en profondeur est fournie par le framework de Caffe en open source qui a été développé par le laboratoire Berkeley Artificial Intelligence Research (BAIR). Les principes orientatifs de Caffe sont les suivants :
- Expression : les modèles et les optimisations sont définis sous forme de schémas en texte clair plutôt qu'en code.
- Vitesse : pour les chercheurs et les industriels, la vitesse est cruciale pour les modèles de pointe et les données massives.
- Modularité : il faut de la souplesse et des possibilités d'extension pour les nouvelles tâches et les nouveaux environnements.
- Ouverture d'esprit : le progrès scientifique et ses applications nécessitent une approche commune en termes de code, de modèles de référence et de reproductibilité.
- Communauté : la recherche académique, les prototypes de startup et les applications industrielles partagent leurs points forts communs par une concertation et une évolution en commun dans le cadre d'un projet BSD-2.
Le site Web du projet propose une vue d'ensemble de l'anatomie et des fonctions de Caffe. Si comme moi vous n'avez qu'une petite expérience dans la technologie de l'IA, vous aurez un tas de choses à assimiler. Ne craignez rien cependant, car le SDK de Movidius Neural Compute (NC) rassemble le framework et le support matériel, ainsi que des exemples d'applications qui exploitent les modèles de réseau neuronal existants. Autrement dit, vous êtes opérationnel en un rien de temps, et en mesure d'évaluer les performances des réseaux et du matériel du NCS.
Installation du SDK
Installation du SDK
Un ordinateur fonctionnant sous Ubuntu 16.04 est requis pour l'installation du SDK NC. D'autres distributions pourraient fonctionner, mais c'est la seule qui a été spécifiée.
Vous trouverez ci-après un résumé des mesures prises. Il est conseillé de télécharger le Guide de démarrage au format PDF et d'autres documents officiels pour des instructions plus détaillées.
Une fois téléchargé, le SDK NC peut être installé comme suit :
$ sudo apt-get update
$ sudo apt-get upgrade
$ tar xvf MvNC_SDK_1.07.07.tgz
$ tar xzvf MvNC_Toolkit-1.07.06.tgz
$ cd bin
$ ./setup.sh
Cette opération peut prendre un peu de temps, car le kit d'outils et ses dépendances connexes seront installés. Notez que le script de configuration met à jour votre fichier ~/.bashrc afin de configurer la variable d'environnement PYTHONPATH en conséquence. Par ex., avec l'emplacement d'installation par défaut, la ligne ajoutée est :
export PYTHONPATH=$env:"/opt/movidius/caffe/python":$PYTHONPATH
Pour autoriser d'autres utilisateurs à utiliser le SDK, ceux-ci devront également ajouter cette ligne à leur fichier ~/.bashrc.
En supposant que nous sommes encore dans le répertoire bin, nous pouvons alors installer les modèles de Caffe pour l'exemple de code :
$ cd data
$ ./dlnets.sh
En revenant au répertoire où le SDK a été extrait pour la première fois, nous pouvons alors installer l'API :
$ cd ../..
$ tar xzvf MvNC_API-1.07.07.tgz
$ cd ncapi
$ ./setup.sh
Il existe une série d'exemples pouvant être exécutés depuis le répertoire bin pour tester le fonctionnement du NCS.
$ cd ../bin
$ make example00
$ make example01
$ make example02
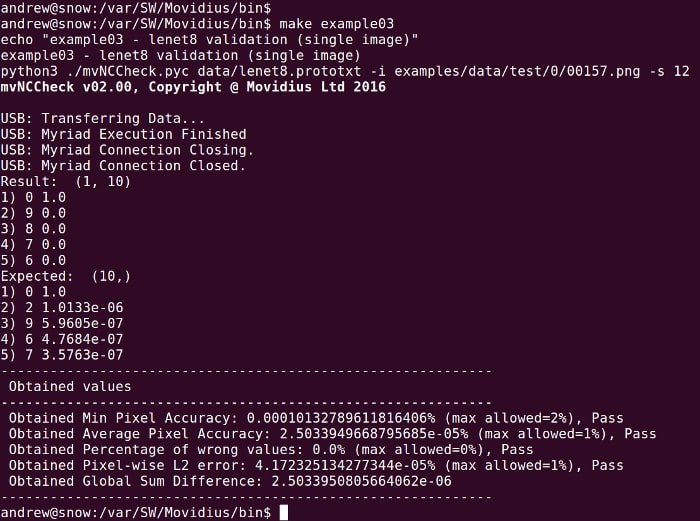
$ make example03
Exemple d'inférence de flux vidéo

Python stream_infer example
Passons maintenant à un exemple particulièrement intéressant ! Un dispositif d'entrée vidéo étant nécessaire pour l'opération, nous avons décidé d'utiliser la Webcam Logitech C920 en Full HD (125-4272), car elle bénéficie d'une excellente prise en charge de Linux.
$ cd ../ncapi/tools
$ ./get_models.sh
$ ./convert_models.sh
$ cd ../py_examples/stream_infer
$ python3 stream_infer.py
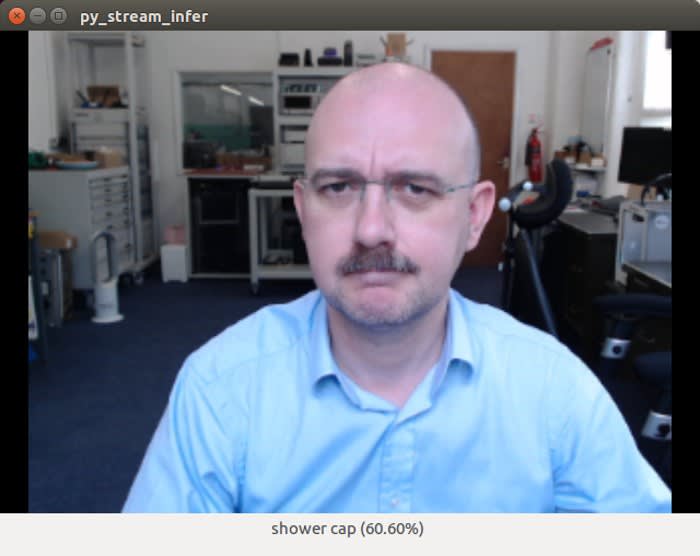
Ouille ! Un bonnet de douche 60,60% ? ! OK, ce n'est pas de ma faute — le NCS a juste fait le gros travail et nous devons remercier le réseau neuronal convolutionnel (CNN) utilisé pour l'inférence. Reconnaissons que c'est sans doute compréhensible. Quoi qu'il en soit, de ce qui précède, nous constatons qu'avec le même exemple, on s'en est mieux sorti avec une tasse à café ainsi qu'avec d'autres objets.
Ce qui compte est la vitesse à laquelle l'IA peut faire des inférences — et vu l'énergie utilisée, je ne vois pas comment il serait possible que celles-ci ne soient pas rapides.
Le modèle par défaut utilisé par l'exemple stream_infer.py est appelé SqueezeNet, un CNN qui obtient une précision équivalente à celle du modèle AlexNet qui le précède d'environ 4 ans, et qui a été entraîné pour classifier les 1,3 million d'images à haute résolution de l'ensemble de données ImageNet LSVRC-2010 en 1 000 différentes classes ; même si on estime que SqueezeNet y est parvenu avec un modèle 510x plus petit que celui d'AlexNet.
L'exemple stream_infer.py peut être configuré pour utiliser soit SqueezeNet soit AlexNet, ce qui permet de comparer leurs performances sur le NCS. Il s'agit simplement de (dé)commenter les lignes en haut du fichier Python. Il existe également les modèles Gender et GoogleNet qui sont configurables de la même façon. Par ex. :
NETWORK_IMAGE_WIDTH = 224 # the width of images the network requires
NETWORK_IMAGE_HEIGHT = 224 # the height of images the network requires
NETWORK_IMAGE_FORMAT = "RGB" # the format of the images the network requires
NETWORK_DIRECTORY = "../../networks/GoogLeNet/" # directory of the network
L'exemple stream_infer.py recherche les fichiers "graph", "stat.txt" et "categories.txt" dans NETWORK_DIRECTORY. Si on compare la taille du fichier de graphique pour AlexNet et SqueezeNet :

La différence n'atteint pas vraiment 510x pour le fichier graphique, mais elle demeure grande en termes de taille de fichier.
Network compilation and profiling

Source : Documentation du kit d'outils NCS de Movidius
De nouveaux CNN — par ex., pour classifier les types d'images recouvertes par un CNN existant — seront conçus et entraînés sur la base d'un framework approprié. Le réseau sera ensuite compilé en un fichier graphique et profilé à l'aide du kit d'outils NCS qui accompagne le SDK.
Ciblage de plates-formes embarquées
Même s'il faut d'abord installer l'API sur le même ordinateur que le kit d'outils (système Ubuntu 16.04 x86-64), les bibliothèques, les en-têtes, etc. seront ensuite installés sur d'autres plates-formes. De fait, un ensemble de paquets pour Raspbian Jessie est fourni avec le SDK. Ainsi, après l'installation de ces dépendances supplémentaires du référentiel Raspbian, une seule ligne est conservée dans l'exemple stream_infer.py à modifier afin que cet exemple puisse fonctionner sur un Raspberry Pi.
Applications type

VPU Movidius sélectionné pour le traitement de pixels VR de 4K dans le nouveau Motorola Moto Mod. Source : movidius.com
Les applications de visibilité de la machine incluent :
- Drones et robotique
- Réalité virtuelle et augmentée
- Appareils portables
- Sécurité intelligente
On voit aisément comment l'unité VPU de Myriad VPU pourrait être exploitée dans les caméras de sécurité afin, par exemple, d'identifier un véhicule garé dehors et faire la différence entre un cambrioleur et un animal de compagnie. Imaginez également la grande valeur ajoutée qu'elle pourrait apporter à un robot ménager — par ex., un aspirateur — et dans les applications de drones, où vous voudriez peut-être éviter ou rechercher certains objets. Toutes ces possibilités illustrent les utilisations de cette technologie, et manifestement, il en sortira beaucoup plus encore.
Réflexions initiales
La technologie Movidius permet déjà la mise en œuvre pratique de l'IA dans un grand nombre d'applications réelles, et continue de se rendre utile dans les produits de pointe, tels que le traitement des pixels VR de 4K pour les modules complémentaires des smartphones et pour les systèmes "voir et éviter" des drones. La disponibilité de Neural Compute Stick signifie que tout le monde peut immédiatement commencer à explorer l'unité VPU de Myriad 2, et ajouter aisément de puissantes capacités d'apprentissage en profondeur aux plates-formes embarquées existantes.