Jetson Nano 2GB Makes AI Even More Accessible
Follow article
 Dave from DesignSpark
Dave from DesignSpark
How do you feel about this article? Help us to provide better content for you.
Dave from DesignSpark
Thank you! Your feedback has been received.
Dave from DesignSpark
There was a problem submitting your feedback, please try again later.
Dave from DesignSpark
What do you think of this article?

New NVIDIA developer kit further lowers the barrier to getting hands-on with AI, robotics and other applications which benefit from CUDA accelerated compute.
When the original Jetson Nano launched it caused quite a stir with its combination of a quad-core ARM processor and 128-core GPU, plus 4GB RAM, Gigabit Ethernet and USB 3.0, amongst other features — and providing all this at a pretty incredible price point. However, the latest edition to the family (204-9968) even further lowers the barrier to getting hands-on with the capable platform, courtesy of a new cost-optimised development kit that is close to half the price of the original Nano.
As the name suggests, this new Jetson Nano developer kit features 2GB RAM instead of 4GB and there are a few other differences. However, as we’ll come to see, the Jetson Nano 2GB will still be a great fit for many applications and at this much reduced price, is set to get many more hands-on with AI and other CUDA accelerated workloads. Not to mention also making it feasible to embed the technology in all manner of more cost-sensitive projects.
2GB + 4GB comparison

Above we can see the Jetson Nano 2GB alongside a 4GB developer kit. At this point it should be noted that the latter is an A02 variant and not the updated B01 kit, with a notable difference being that current 4GB kits now feature 2x CSI-2 camera interfaces. Hence much like earlier 4GB kits, the Jetson Nano 2GB has just a single CSI-2 camera connector. For many applications this will be more than sufficient and of course it is possible to connect a camera via USB also.

Another key difference is that while the 4GB kit features 4x USB 3.0 ports, the 2GB kit has 2x USB 2.0 ports and a single USB 3.0 port. Once again, this will be perfectly adequate for many applications and when using the kit in a learning environment, it’s likely that one if not two USB ports will simply be used for a keyboard and mouse anyway. Speaking of use as a workstation, while the 4GB kit features both HDMI and DisplayPort interfaces, the 2GB variant has only HDMI.

It’s not unusual to see DC coaxial connectors on development boards and 4GB kits feature a 5.5/2.1mm connector for the power supply. However, the new 2GB kit has replaced this with a USB-C connector, which will have been made possible by reducing the maximum current draw down from 4A to 3A, hence within the specifications for 5V power over USB-C.

This may seem like a minor detail, but USB-C power supplies are far more readily available and this perhaps hints at a commitment to make this technology as accessible as possible.

A difference that is not immediately apparent is that 4GB kits feature an M.2 connector tucked away under the Jetson System-on-Module (SoM), which is absent on the 2GB kit. However, given the very limited space the slot is of the Key-E type used for things like laptop-style WLAN adapters, rather than an SSD. Where WiFi is required a USB adapter can be used.
Both the 4GB and 2GB kits include Micro SD slots on the SoM and this is generally used for storage, although USB drives can be attached also. The 2GB kit features the same 40-pin expansion header and there is a second smaller header with connections for a power button, reset and UART etc. Similarly, both the 4GB and 2GB kits have Gigabit Ethernet.

To sum up the main differences: 2 instead of 4GB RAM, a single CSI-2 interface, not as many USB 3.0 ports (you can use an external hub), no DisplayPort (most monitors have HDMI input) and no M.2 slot (can use a USB WiFi adapter). However, the same quad-core CPU and 128-core GPU, along with other great SoC features — and nearly half the price.
Comparison with other platforms
| Features | Jetson Nano Development Kit | Raspberry Pi 4 | Coral (Beta) Developer Board |
|---|---|---|---|
| CPU | Quad-core ARM A57 | Quad-core ARM A72 | Quad-core ARM A53 |
| GPU | 472 GFLOPS (FP16) | - | 64 GFLOPS (FP16) |
| Memory | 4GB 64 bit LPDDR4 1600MHz 25.6 GB/s |
2GB, 4GB or 8GB 64 bit LPDDR4 3200 MHz SDRAM (depending on model) |
1GB 32 bit LPDDR4 1600MHz 12.8 GB/s |
| DL HW | CUDA GPU | CPU | TPU |
| DL SW |
Supports all the popular frameworks - TensorFLow Supports a wide variety of models |
Supports frameworks - TensorFLow Supports a wide variety of models |
Supports only a simplified framework - TensorFlow Lite Suports only a few selected models |
| Codec HW |
4K60 | 8x 1080p30 HEVC Decode 4K30 | 4x 1080p30 HEVC Encode |
4K60 HEVC Decode 1080P60 AVC Decode 1080P AVC Encode |
4K60 HEVC Decode No endode support |
|
WiFi/ BT USB Ports |
External WiFi Dongle bundled 1x USB 3.0 |
Integrated WiFi 2x USB 3.0 |
Integrated WiFi 1x USB 3.0 |
Comparison table provided by NVIDIA.
Given the price point an obvious comparison to make is with Raspberry Pi 4 and while this does feature a GPU, at present it can pretty much only be used for graphics. What this means is that AI workloads will be executing entirely on the CPU and hence the performance is going to be far short of what can be achieved with Jetson Nano. In fact, NVIDIA have suggested that the 2GB developer kit can offer up to 200x the performance of Raspberry Pi 4. However, the Pi 4 does have a more powerful ARM CPU and variants are available with up to 8GB RAM, so this is likely to remain a better choice for many non-AI/parallel processing workloads.
Similarly with Google Coral, which integrates a tensor processing unit (TPU) for accelerating AI workloads, we can see that the raw GFLOPS performance is lower than provided by the Jetson Nano GPU, while the board also has half the RAM and half the memory bandwidth. In addition to which, AI framework support is far more limited with Coral and this is obviously not able to take advantage of the wider CUDA ecosystem, which features software for accelerating many other non-AI workloads. That said, benchmarking has shown certain models running via Tensorflow Lite on Coral to have better performance. In addition to which, the Coral platform is available via not only a dev board, but as a USB accelerator, SoM and M.2/Mini-PCIe board.
There are of course an increasing number of more deeply embedded solutions available, which tend to be based around cut down and bespoke AI frameworks running on microcontrollers. These are great if you have an ultra-low power requirement and it is something which is suited to this class of hardware. For example, a basic smart security camera with person detection. However, such solutions are unlikely to be a good fit for many more demanding applications.
Another key thing to note is that with Jetson it is possible to run both inference and training on the same hardware. Given that training is much more computationally demanding than inference, it rarely makes sense to even bother trying to do this on a CPU. Hence when executing AI models on a Raspberry Pi or uC-based platform, training needs to be done on another computer — which more often than not is a desktop, server or cloud system that is equipped with an NVIDIA GPU.
A Jetson Nano is not going to give the same performance as a computer fitted with a recent PCIe GPU, but it does provide an eminently affordable on-ramp where the AI novice is able to get hands-on with both training and inference with minimal outlay. Further to which it may also lead to some interesting applications with e.g. iterative on-device training. Where more resources and/or faster training is required, this can easily be scaled-up thanks to portability across CUDA hardware.
So to sum up, Jetson Nano provides fantastic performance executing AI inference and as a bonus, it can also be used for training models. However, like so many things, it’s a question of the right tool for the job and there will be use cases where other platforms may be better suited.
Software support

In a previous post I took a look at the original Jetson Nano 4GB and as part of which covered the software stack. To summarise, CUDA is a parallel computing platform and API model created by NVIDIA, which is used to provide access to the GPU. It supports devices which range from those used in embedded platforms such as the Jetson family, all the way up to blisteringly high performance data centre solutions. It provides a set of accelerated libraries, in addition to extending C/C++ and providing a FORTRAN (popular in high-performance computing) implementation.
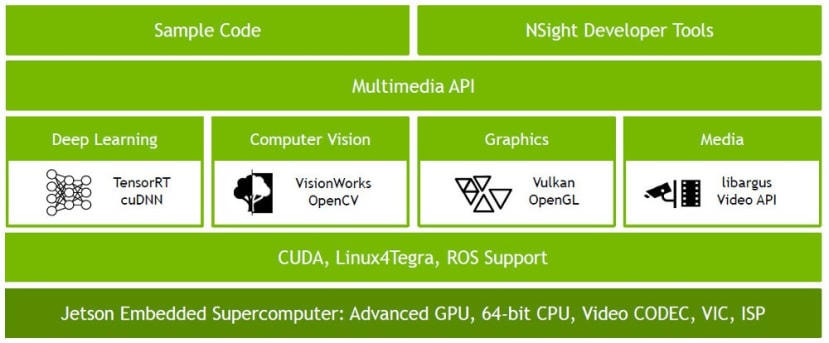
JetPack SDK builds on top of CUDA and provides OS images, libraries, APIs, examples and developer tools. It includes things such as an Ubuntu-based image for Jetson Nano, along with various accelerated higher level libraries for developing deep learning and computer vision apps.

As previously mentioned, CUDA can also be used to accelerate non-AI workloads, such as digital signal processing and in support of which, NVIDIA provide software called cuSignal, that enables GPU accelerated signal processing from within Python applications. A simple, albeit very effective, example that uses this is PyRadio, a set of software-defined radio (SDR) scripts that when used together with a desktop GPU are able to demodulate 35+ FM broadcast radio stations in parallel.
Although AI and associated fields such as robotics represent perhaps the most profound opportunities for GPU — i.e. parallel — processing, this is by no means where the story ends. Indeed, as the technology is put into the hands of many more people, we can expect to see a growth in software which is able accelerate an increasing number of compute intensive non-AI workloads.
Jetson AI Certification

At the same time as the Jetson Nano 2GB was announced NVIDIA also launched Jetson AI Certification via its Deep Learning Institute. This provides certification tracks for AI Specialist and AI Ambassador, with the latter targeted at educators and instructors. Both of which require basic familiarly with Linux and Python, while the Ambassador certification also recommends that candidates have prior teaching or training experience.
Structured course content is provided by NVIDIA and AI Specialist certification requires that those enrolled “submit an open-source project that uses NVIDIA Jetson and incorporates elements of AI (machine learning or deep learning) with GPU acceleration, along with a video demonstrating the project in action.” AI Ambassador certification involves an additional interview step.
Final thoughts
The Jetson Nano 2GB has the potential to introduce many more to AI and other CUDA accelerated (parallel processing) applications. While the low price point means that it’s likely to also find use in many projects where, despite offering fantastic price/performance, it was previously still hard to justify using the 4GB model, whether that’s a fun spare time creation, or as a component in part of a large scale research project, for example.