Hand Classifier Model Training
Follow article
 Dave from DesignSpark
Dave from DesignSpark
How do you feel about this article? Help us to provide better content for you.
Dave from DesignSpark
Thank you! Your feedback has been received.
Dave from DesignSpark
There was a problem submitting your feedback, please try again later.
Dave from DesignSpark
What do you think of this article?
| Author | Dan |
| Difficulty | Moderate |
| Time required | 2hrs |
In our previous article, we discussed how to use Raspberry Pi for detecting hands to activate a relay switch. In this article, we want to know about how the classifier model was trained and how to work on the related codes.
Before getting started, we want to make sure we have the minimum system requirements to perform the model training routine. In running the training program we used the following specifications:
- OS: Windows 10
- GPU: Nvidia GTX840M
- RAM: 12GB
Take note that these specifications are only based on a laptop. It is always better to run the training program to a dedicated GPU computer or server. But since our sample set is not too large, this is enough to get started. For building the environment, we used Anaconda with Python 3.5. This is better if you want to manage several environments for different purposes. In the Anaconda environment, we installed the following Python libraries:
- keras 2.2.4
- matplotlib 2.1.1
- numpy 1.17.4
- opencv-python 3.4.3.18
- tensorflow-gpu 1.11.0
- scikit-image 0.15.0
- scikit-learn 0.19.1
Taking note of the environment, we hope and assume that you have these libraries installed before running the training program. We advise that you install them first by following the tutorials on their respective websites. We want to avoid issues in which our program won’t work due to outdated libraries upon the writing of this article.
Theory
Let’s first talk about how everything works. We trained a convolutional neural network (ConvNet) model that can be used to classify our images into two classes: hand and others. But what is a CNN model? CNN models make use of the concept of convolution. It is a concept in image processing where specific operations are applied to cells of an image based on a defined kernel size. Most commonly, convolutions are used for edge detection. Computer scientists used convolutions to extract edges in sequences and further extract more information from such edges to discover higher-level features. In our example, we used a simple ConvNet model for this application. The ConvNet model is made up of three convolutional layers, a fully connected layer, and one softmax layer. In particular, the three convolutional layers extract the low, medium, and high-level features as shown below:

Using the hand image as input, the hand from the image is slowly recognized by the first convolutional layer. Going further, the network sees the upper edges of the hand and later on sees the entire hand. The output of the third convolutional layer goes into the fully connected layer to learn possible deep features such as color, shape, or size of the hand. Some people say that deep features are features that may not be comprehensible to people but only the computer understands it. It may be true since most networks are accurate, even the deep features are not recognizable by humans. Finally, the deep features enter the softmax layer where it outputs a probability of which class the image belongs to.
This explanation, however, is a very rough description of how ConvNets work. In fact, it may be a lot more useful to take a full-course class on deep learning to understand this. But still, we hope that you were able to follow the basic concept of ConvNets. Now, we go on to the training procedures.
Classifier training
STEP 1: Sample preparation
Sample preparation is one of the most crucial steps in training a neural network model. Most people encounter training problems such as models failing to converge. But sometimes, it may be just because they lack samples or had too many samples for training. In other instances, the samples may not be sorted properly.
First, we collected samples from our Raspberry Pi by taking images every 5 seconds (which can be seen from the timestamp filenames of our images). To make our model simple, we put our hands in front of the camera for the hand class and nothing or something else for the others class. The sample images are shown below:

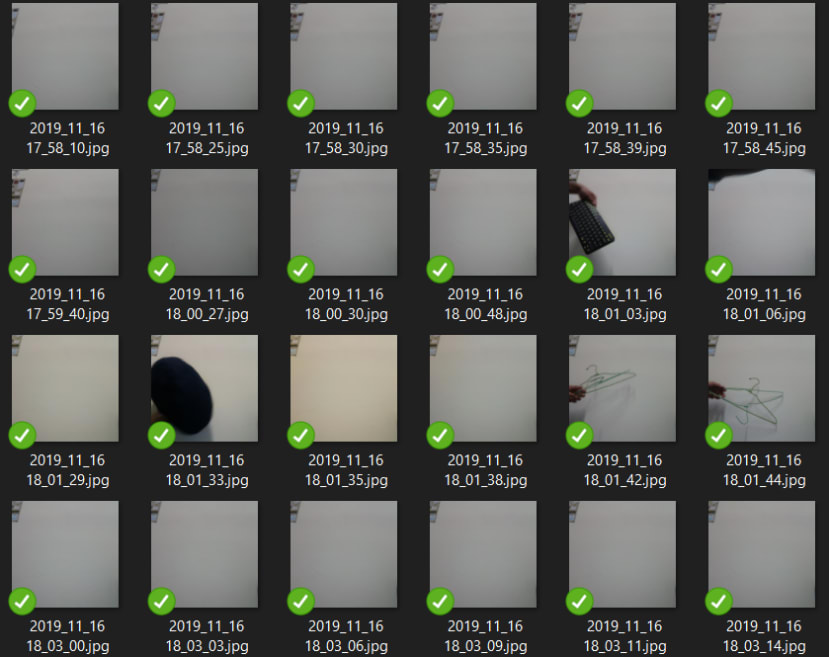
From the images, it can be seen that we made it very clear that the difference between the hand class and other class can be clearly noticed. This makes it easier for our model to learn which is a hand or not. In total, we collected 142 hand images and 135 others images. These numbers are believed to be enough since our samples are quite simple. The images were put into a folder as hand and others, respectively.
STEP 2: Model training
Introduction over, let’s go to the training program. The training program relies on two python script libraries we also prepared to simplify the training process: dataset.py and image_classifier.py
dataset.py
The script dataset.py helps in preparing the training images into formats that will be compatible with the libraries we are going to use. The most important function in dataset.py is load_set. It retrieves all the image files from the image directory and sorts them into lists according to class. Besides that, the image files are resized into 128 x 128 according to our network structure requirement, which will be discussed later on. The output of load_set is the image files in cv Mat format saved into lists with their corresponding labels in another list. The codes are as follows:
import cv2
import os
import numpy as np
from sklearn.utils import shuffle
class DataSet(object):
def __init__(self, images, labels):
self._num_examples = images.shape[0]
self._images = images
self._labels = labels
self._epochs_done = 0
self._index_in_epoch = 0
@property
def images(self):
return self._images
@property
def labels(self):
return self._labels
@property
def num_examples(self):
return self._num_examples
@property
def epochs_done(self):
return self._epochs_done
def next_batch(self, batch_size):
start = self._index_in_epoch
self._index_in_epoch += batch_size
if self._index_in_epoch > self._num_examples:
self._epochs_done += 1
start = 0
self._index_in_epoch = batch_size
assert batch_size <= self._num_examples
end = self._index_in_epoch
return self._images[start:end], self._labels[start:end]
#
#Loads images and stores them into lists, together with their labels.
#
def load_set(train_dir, image_size, classes):
images = []
labels = []
print('Now reading samples...')
images = []
labels = []
total_number_of_files = []
for index, class_name in enumerate(classes):
target_folder = train_dir + "/" + class_name
files = os.listdir(target_folder)
# Check if it is a huge folder
if len(files) > 0:
maybe_dir = target_folder + "/" + files[0]
if os.path.isdir(maybe_dir):
files = []
sub_dirs = os.listdir(target_folder)
for sub_folder in sub_dirs:
sub_files = os.listdir(target_folder + "/" + sub_folder)
for file in sub_files:
files.append(target_folder + "/" + sub_folder + "/" + file)
else:
for i, file in enumerate(files):
files[i] = target_folder + "/" + file
number_of_files = len(files)
for file in files:
original_image = cv2.imread(file)
image = cv2.resize(original_image, (image_size, image_size),0,0, cv2.INTER_CUBIC)
images.append(image)
labels.append(index)
print('{} ({}), #: {})'.format(class_name, str(index), number_of_files))
total_number_of_files.append(labels.count(index))
images = np.array(images)
labels = np.array(labels)
return images, labels, total_number_of_files
The function load_set is actually called by another function called read_train_sets:
#
#Loads images, shuffles the image datasets, and allocates the number of images of each set
#
def read_train_sets(train_path, class_names, image_size, validation_size):
class DataSets(object):
pass
data_sets = DataSets()
images, labels, number_of_files = load_set(train_path, image_size, class_names)
images, labels = shuffle(images, labels)
if isinstance(validation_size, float):
validation_size = int(validation_size * images.shape[0])
validation_images = images[:validation_size]
validation_labels = labels[:validation_size]
train_images = images[validation_size:]
train_labels = labels[validation_size:]
data_sets.train = DataSet(train_images, train_labels)
data_sets.valid = DataSet(validation_images, validation_labels)
return data_sets
The input to the function is the image path, class names, image size, and the validation set size. As the function is called, load_set is performed and the important sub-function is shuffle. Shuffle makes sure your training and validation set are randomly sorted such that it makes your training routine effective. Also, the validation size is set to separate the function into your training and validation set. Typically, the best size for the validation set is around 10% - 25% of your training set.
image_classifiers.py
The script image_classifiers.py contains the codes for constructing our ConvNet. First, the libraries are called as follows:
from keras.models import Sequential
from keras.layers.core import Dense, Activation, Flatten
from keras.layers.convolutional import Conv2D, MaxPooling2D
import tensorflow as tf
import numpy as np
import keras as ks
from skimage.transform import resizeThere are several sub-functions inside the script. First is load_classify_image:
def load_classify_image(image, image_size):
num_channels = 3
images = []
# Resizing the image to our desired size and preprocessing will be done exactly as done during training
image = resize(image, (image_size, image_size))
image = image * 255
images.append(image)
images = np.array(images, dtype=np.uint8)
# The input to the network is of shape [None image_size image_size num_channels]. Hence we reshape.
x_input = images.reshape(1, image_size, image_size, num_channels)
return x_inputThis function pre-processes the image depending on the input to our ConvNet. Next is load_labels and it simply gets the class names for our ConvNet:
def load_labels(filename):
# print("Loaded labels: " + str(filename))
return [line.rstrip() for line in tf.gfile.GFile(filename)]
Furthermore, a class called ImportGraph() is also included. The function is used to store our ConvNet model as an object to be easily called:
class ImportGraph():
def __init__(self, loc):
self.loc = loc
if ".h5" in str(loc):
self.kerasmodel = ks.models.load_model(loc)The most important component of the class is the predict_by_cnn function. It gets the prediction results from our ConvNet and sorts the classification results. The results are classified based on the classification probability. The input to predict_by_cnn is the image data, probability, and the string labels. The special part is the probability input. It is used to set a threshold for the prediction. Let’s say the classification probability for an image is 0.30 only. You can use a threshold of 0.50 to filter out this classification since the model was not confident enough. The predict_by_cnn function is shown below:
def predict_by_cnn(self, data, probability, labels):
number_of_labels = len(labels)
try:
if ".h5" in self.loc:
predictions = self.kerasmodel.predict(data)[0]
# sort predictions
top_k = predictions.argsort()[-number_of_labels:][::-1]
this_class = "na"
this_score = 0
human_strings = []
scores = []
# get results
for node_id in top_k:
human_strings.append(labels[node_id])
scores.append(predictions[node_id])
top_index = scores.index(max(scores))
top_score = scores[top_index]
if top_score >= probability:
this_score = top_score
this_class = human_strings[top_index]
if top_score < probability:
this_class = "unknown"
except Exception as e:
print(e)
return this_class, this_score
Finally, our ConvNet model is constructed in createCNNModel. Specifically, our model is a sequential model. This means that the model follows a certain order for performing several functions:
# cnn
def createCNNModel(img_shape, n_classes, n_layers):
# Initialize model
model = Sequential()Next, we construct each layer of our ConvNet. Referring to our ConvNet structure a while ago, we can see that we have three convolutional layers. Here, we can see the different sizes of the layers. This allows feature extraction at different levels such as low, medium, and high. The codes are as follows:
# Layer 1
model.add(Conv2D(64, (5, 5), input_shape=img_shape))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(3, 3), strides=2))
# Layer 2
model.add(Conv2D(64, (5, 5), padding='same'))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(3, 3), strides=2))
# Layer 3
model.add(Conv2D(128, (3, 3), padding='same'))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(3, 3), strides=2))
Indeed, you can try changing these parameters such as the convolutional layer kernel and mask sizes. However, it is better if you have already checked out how convolution works before doing so. Lastly, a flattening layer is added to transform our features into a single dimension. After doing so, Rectified Linear Unit (ReLu) is used to activate deep features from the lower level features:
model.add(Flatten())
model.add(Dense(n_layers))
model.add(Activation('relu'))Finally, the dense layer is used to set the number of classes while its softmax activation layer outputs the probability of the image belonging to a certain class.
model.add(Dense(n_classes))
model.add(Activation('softmax'))
return modelFinally, let’s go to the training script – cnn_trainer.py. The script starts by calling the necessary libraries:
#
# Library and dependencies
#
import matplotlib.pyplot as plt
import keras
import dataset as dataset
import os
from keras.preprocessing.image import ImageDataGenerator
from keras.utils import to_categorical
import image_classifiers as ICNext, we set some arbitrary program constants. One of which is the model name:
#
# Arbitrary constants
#
# Define model name
model_name = "hand_cnn"You can set this to whichever name you want depending on your model. Other than that, we have the training directory or the image directory. Inside the directory are the image class folders:
# Train directories
train_dir = "hand_samples"Next are the train settings. This is quite important since your training routine depends on these. First is the batch_size. This is used to know how many images are used to test the model on every epoch. This is typically set into multiples of the number of classes such as 2 x 8 = 16. This, however, depends on your GPU card. If your GPU card is good enough, you can make this as high as possible:
# Train settings
batch_size = 16 # number of validation and training samples per stepThe step_per_epoch now includes the number of training steps per epoch.
step_per_epoch = 20 # number of training steps per epochNow, epochs is the number of validation steps for training. This is the number of times the model is tested. Normally this is set depending on the number of samples. For now, we used 25 based on our initial testing:
epochs = 25 # number of epochsThe models can be saved in every n number of epochs. In this context, to save is to freeze the model such as it can be called to be used for our application. We’ve employed a save_every_epoch function as an optional feature of our program:
save_every_epoch = 5 # saves model every epochLastly, we have the target_size which is the input size to the ConvNet model. Included in it is the number_of_layers. The number_of_layers is the number of layers of the fully connected layer. Depending on the complexity of the images, this can be set from 64 to up to 4096, where 64 is the least complex:
target_size = 128 # resizes images to this size
number_of_layers = 128Now, we set the model saving settings. In this example, we set it into BEST_MODELS where the program saves the model depending on if the training and validation accuracy before the previous epoch. This is more efficient since it can check if your model improves after each epoch:
# Model saving settings
EVERY_N_EPOCHS = 1
BEST_MODELS = 2
save_model_mode = BEST_MODELSBefore starting the training routine, we set a random seed such that our training becomes reproducible:
# Set seed to make reproducible training results
from numpy.random import seed
seed(1)
from tensorflow import set_random_seed
set_random_seed(2)Next, we set the model saving directory, get the number of classes, set a model saving directory, and save the class names in a .txt file:
# Assigns model save directory
model_dir = "generated_models/" # saves all model (.h5) files to this location
model_save_dir = model_dir + model_name # saves model to the name assigned in train_path
savemodel_filename = model_save_dir + "/" + str(model_name)
# Scan folder and check number of classes
class_names = os.listdir(train_dir)
class_names = [f for f in class_names if ".jpg" not in f]
num_classes = len(class_names)
# Makes model save directory
try:
os.mkdir(model_save_dir)
except:
print("Directory exists!")
pass
# Make labels .txt file
label_filename = savemodel_filename + ".txt"
with open(label_filename, 'w') as txt_file:
for x in range(0,len(class_names)):
txt_file.write(class_names[x] + "\n")
We finally call the read_train_sets function we’ve mentioned a while ago:
# Separate training and validation set
data = dataset.read_train_sets(train_path=train_dir,
class_names=class_names,
image_size=target_size,
validation_size=0.2)
After doing so, you will be able to see the following output:
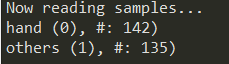
The image data is prepared as the input to our training function here:
# Prepare training and validation data
train_data = data.train.images.astype('float32')
valid_data = data.valid.images.astype('float32')
nRows,nCols,nDims = train_data.shape[1:]
input_shape = (nRows, nCols, nDims)
train_labels = data.train.labels
valid_labels = data.valid.labels
train_labels_one_hot = to_categorical(data.train.labels)
valid_labels_one_hot = to_categorical(data.valid.labels)
Now, we set the model saving settings. In this example, we set it into BEST_MODELS where the program saves the model depending on if the training and validation accuracy before the previous epoch. This is more efficient since it can check if your model improves after each epoch:
# Set image normalization
datagen = ImageDataGenerator(rescale=1./255)
The model is called and compiled in this part:
# Create model and show its structure
# Refer to "image_classifiers.py" for changing the structures
model = IC.createCNNModel((target_size, target_size, 3), num_classes, number_of_layers)
# Compile model
optim = keras.optimizers.Adam(lr=0.00005)
model.compile(optimizer=optim, loss='categorical_crossentropy', metrics=['accuracy'])
print(model.summary())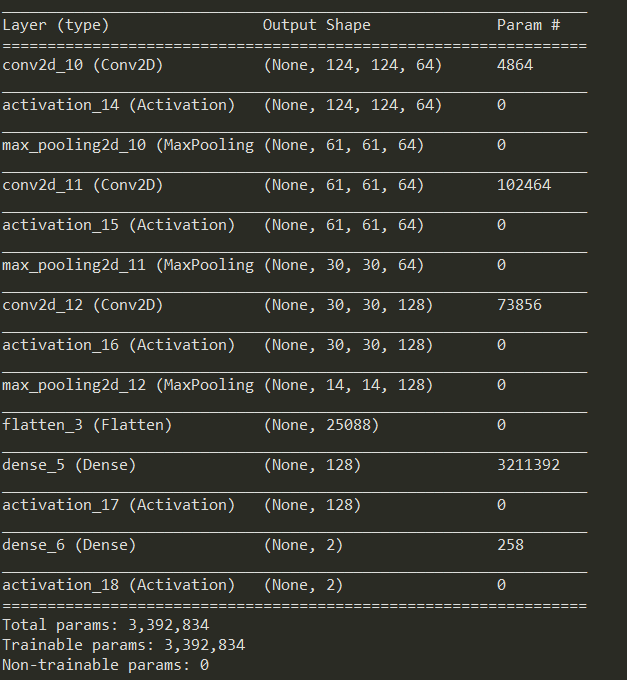
The training routine starts here:
#
# Option 1:
# Saves model every 10 epochs
#
if save_model_mode == EVERY_N_EPOCHS:
mc = keras.callbacks.ModelCheckpoint(str(savemodel_filename) + "_{epoch:d}.h5",
save_weights_only=False, period=save_every_epoch)
#
# Option 2:
# Save only the best models
#
if save_model_mode == BEST_MODELS:
mc = keras.callbacks.ModelCheckpoint(str(savemodel_filename) + "_{epoch:d}.h5",
save_weights_only=False,
save_best_only=True,
mode='auto')
# Start training
history = model.fit_generator(datagen.flow(train_data, train_labels_one_hot, batch_size=batch_size),
epochs=epochs,
steps_per_epoch=step_per_epoch,
validation_data=datagen.flow(valid_data, valid_labels_one_hot),
validation_steps=batch_size,
verbose=1,
callbacks=[mc])
Finally, our program saves your training summary to .csv file. Most importantly, the training and validation accuracy and loss curves are also shown for your reference.
# Save training summary to csv
import pandas as pd
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(len(acc))
summary_dict = {'Epoch': epochs, 'TrainAcc': acc, 'ValAcc': val_acc, 'TrainLoss': loss, 'ValLoss': val_loss}
df = pd.DataFrame(data=summary_dict)
df.to_csv(model_save_dir + "/" + model_name + ".csv")
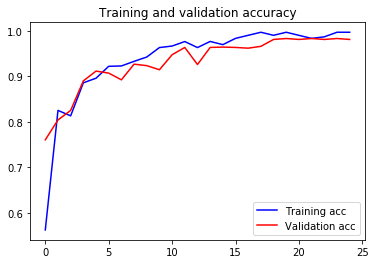
# Plot accuracy curves
plt.plot(epochs, acc, 'b', label='Training acc')
plt.plot(epochs, val_acc, 'r', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'b', label='Training loss')
plt.plot(epochs, val_loss, 'r', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.interactive(False)
plt.show()