使用Google Teachable Machine 來實現Raspberry Pi 4 的影像分類推論
关注文章
 戴夫来自 DesignSpark
戴夫来自 DesignSpark
你觉得这篇文章怎么样? 帮助我们为您提供更好的内容。
戴夫来自 DesignSpark
Thank you! Your feedback has been received.
戴夫来自 DesignSpark
There was a problem submitting your feedback, please try again later.
戴夫来自 DesignSpark
你觉得这篇文章怎么样?
| 作者 | 许钰莨/曾俊霖 |
| 難度 | 普通 |
| 材料表 |
|

本文實現影像分類分成幾個步驟:
- 在TM網頁中蒐集資料,訓練模型,在網站中即時影像分類。
- 匯出模型及標籤檔。
- 至樹莓派官網下載最新版本的RPi4映像檔。
- 安裝模型框架Tensorflow Lite。
- 安裝OpenCV套件。
- 實現影像分類於RPi4。
了解以上步驟後,其建置RPi4環境的時間花得最久,但讀者們仍可同步進行,例如:
RPi4在燒錄SD卡或安裝套件時,又同時在TM網站蒐集資料及訓練模型。
Teachable Machine (TM)介紹

TM網站可供初學者認識AI人工智慧的神經網路應用平台,主要是以「監督式學習Supervised learning」建置而成的訓練平台。目前網站針對使用者提供三種不同的AI應用,分別是影像分類專案(Image Project)、聲音辨識專案(Audio Project) 與身體姿態辨識專案(Pose Project),也提供了Tensorflow、Tensorflow.js與Tensorflow Lite三種訓練模型框架,可供使用者匯入如RPi4的裝置來實現邊緣運算。
每個專案都被設計成三個步驟,分別是蒐集(Gather)、訓練(Train) 與匯出(Export)。
請選擇 「Image Project」開始專案
Step1. 在TM網頁中蒐集資料,訓練模型,在網站中即時影像分類。
進入頁面後會看到幾項操作流程,a.設定標籤及蒐集資料、b.訓練集及c及時預覽功能和匯出模型。

首先在a部分,可將標籤名稱Class 1更名,接著透過電腦Webcam或Upload,從電腦或Google雲端硬碟上傳圖片,及按下「Add a class」來增加類別。本文是開啟電腦Webcam來蒐集資料。
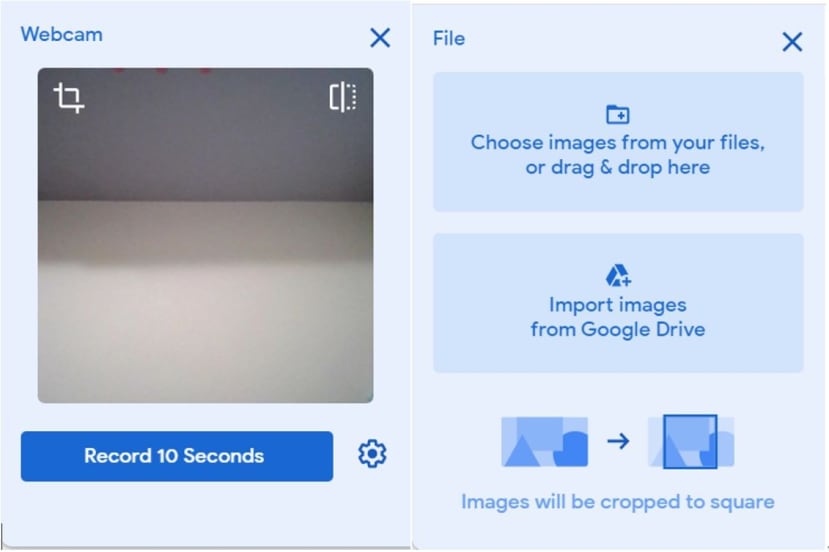
可直接按下「Record 10 Second」,網頁便會倒數計時持續拍攝直到10秒結束,如果認為10秒的張數太少,可以按下齒輪,可以更改秒數等相關參數。初始參數有「24FPS」 (理論值為每秒鐘拍24張)、「Hold-to-record OFF」(關閉手動拍攝)、「Delay: 2 seconds」(2秒後才開始拍攝)、「Duration: 10 second 」(拍攝10秒鐘,理論值約可拍攝240張,但實際上要取決於網頁執行效能),本文將秒數調成25秒,可以刪掉一些拍攝失敗的照片,再者也可以使資料量豐富。
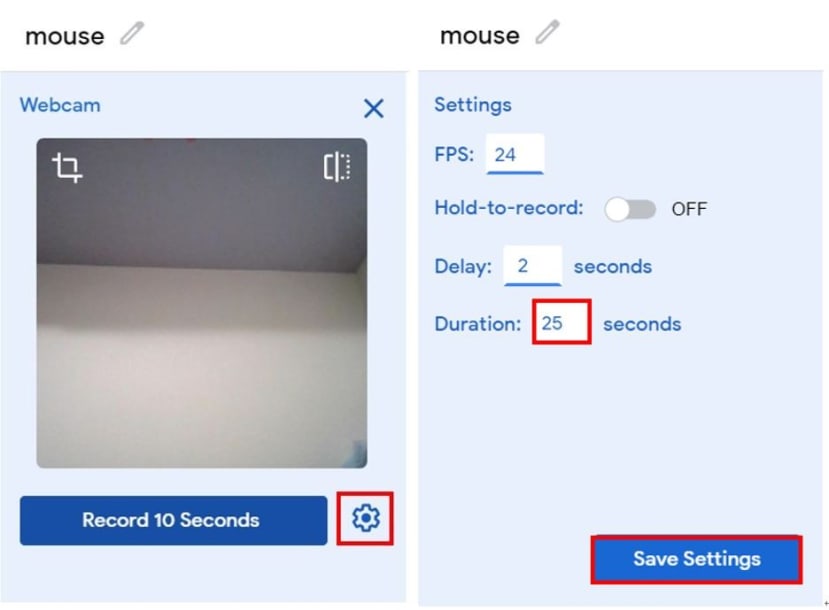
按下「Save Setting」à 「Record 25 seconds」,開始拍攝,拍攝完成可將拍得不好或模糊的圖片刪除。
本文建立了5種類別,分別是「mouse」、「nothing」、「RaspberryPi」、「PEN」、「Bruce Lee」,但有一個種類必須要建立的是「nothing」,意思是沒有照到「mouse」、「RaspberryPi」、「PEN」、「Bruce Lee」時的情形。當初筆者忘了建立「nothing」種類,當沒有照到物品時,就會一直認為「mouse」。

要分辨的影像張數盡量不要相差太遠,本文接近約莫300張左右,在「nothing」類別較多張是為了沒有照到的影像都要視為「nothing」,故照了很多「mouse」、「RaspberryPi」、「PEN」、「Bruce Lee」以外的照片。
接下來是訓練模型,按下「Train Model」即可。但要修改參數,請按下「Advanced」,預設參數有「Epochs :50」(50個訓練回合)、「Batch Size: 16」(批次大小)、「Learning Rate:0.001」(學習率),以下分別說明。
Epochs:
訓練的回合設定,訓練回合數和時間成正比,若要針對細微變化的差異進行辨識時則要提高回合數,會助於模型辨識效能,但特別要注意的是過高的回合數可能會使模型產生「過適Overfitting」的問題,若是過低的回合數會產生「乏適Underfitting」的問題,但無論是甚麼問題都會降低模型辨識效能。
Batch Size:
適當的批次大小設定有助於模型的優化,而且可以提高訓練的速度,及減少訓練誤差。
Learning Rate:
學習率設定影響著訓練模型尋找最佳解的過程中是否會收斂或發散。若設定過大,雖會快速收斂,但也可能難以收斂產生震盪甚至發散;相對的,設定過小會導致尋找最佳解時緩慢收斂。讀者們若有興趣,可以搜尋『梯度下降法』。
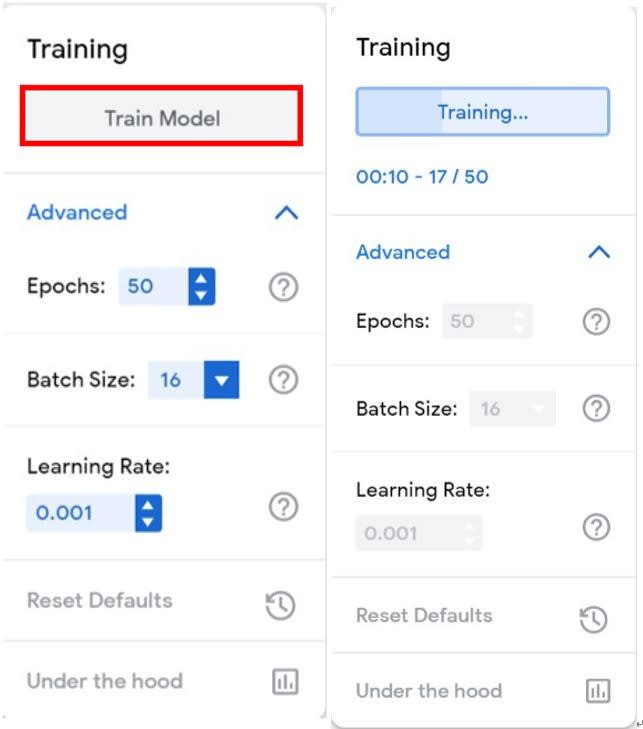
在訓練過程中會跑出對話框 ,提醒使用者不要更動到標籤類別以免影響訓練。

訓練完成後即可在網頁上作及時的影像推論,影像來源除了根據攝影機之外,還可以從電腦端及Google雲端匯入照片進行物件辨識。

Step2. 匯出模型及標籤檔
按下「Export Model」後可匯出模型檔及標籤檔

請選「Tensorflow Lite」à「Quantized」à「Download my model」。「Floating point」格式建議在個人電腦的環境操作;「Quantized」格式適合在像Raspberry Pi的單板電腦操作則有最佳效能;「Edge TPU」格式則僅限於Google Coral 的系列產品,如: Google Coral USB Accelerator 或 Google Coral Dev Board 的產品上。

Step3. 至樹莓派官網下載最新版本的RPi4映像檔。
請到 https://www.raspberrypi.org/downloads/raspbian/ 下載 「Raspbian Buster with desktop」,此版本為桌面簡易版,沒有多餘的軟體,且較不占SD卡空間。

下載至電腦後,須將檔案解壓縮,再準備一張16G的SD卡,利用Win32 Disk Imager 軟體(下載點: https://sourceforge.net/projects/win32diskimager/)燒錄至SD卡中。

a部分先選擇RPi4 的映像檔;b部分選擇燒錄SD卡的磁碟位置(要小心不要選錯,以免燒錯磁區);c部分則選擇資料到「裝置」,將映像檔燒錄至SD卡內。
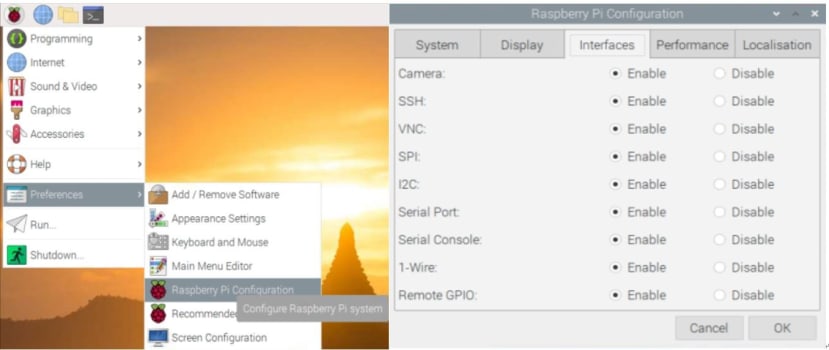
燒錄完成後可將SD卡插至RPi4 卡槽後,但先別急著開機,而是先將RPi4連結到螢幕再開機,否則開機後再接螢幕是沒有畫面的,最後在接上鍵盤、滑鼠即可,這樣較好設定網路。將網路和地區都設定好之後,請開啟RPi4圖示à「Preferences」à「Raspberry Pi configuration」à「Interfaces」,將所有功能開啟後重新開機,以便可用遠端軟體控制RPi4。
本文所使用的遠端連線軟體為MobaXterm (下載處: https://mobaxterm.mobatek.net/download.html) ,此軟體優點除了可以遠端連線RPi4,也可以對RPi4傳輸檔案,但RPi4必須要和MobaXterm同個網域,開啟後請按「Session」à「SSH」à在「Remote host*」輸入RPi4 IP(本文IP為192.168.12.56),連線成功會出現「login as:」,請輸入預設帳號pi ,再來是預設輸入密碼raspberry(密碼不會顯示在畫面上),按下Enter即可登入成功。
之後的安裝套件步驟可直接將指令複製並貼至MobaXterm中。

登入RPi4成功畫面。

Step4. 安裝模型框架Tensorflow Lite。
請到https://www.tensorflow.org/lite/guide/python 官方網站下載套件,新下載的RPi4 映像檔的版本預設為Raspbian Buster ,Python 版本為3.7版 ,所以在MobaXterm請輸入:
$ pip3 install https://dl.google.com/coral/python/tflite_runtime-2.1.0.post1-cp37-cp37m-linux_armv7l.whl (P.S. $指令不需要複製)


Step5. 安裝OpenCV套件。
- 擴展文件系統到整張SD卡
首先在MobaXterm輸入
$ sudo raspi-config選擇"7 Advanced Options" à "A1 Expand filesystem ",重開機。

- 刪除不必要的軟體Wolfram Engine和LibreOffice,非必要做,但可以省下約1G的SD卡容量。
$ sudo apt-get purge wolfram-engine
$ sudo apt-get purge libreoffice *
$ sudo apt-get clean
$ sudo apt-get autoremove
- 更新及升級所有套件包
$ sudo apt-get update && sudo apt-get upgrade
- 安裝開發者套件CMake 需要用來編譯
$ sudo apt-get install build-essential cmake pkg-config
- 安裝有關OpenCV的相依套件
$ sudo apt-get install libjpeg-dev libpng-dev libtiff-dev
$ sudo apt-get install libavcodec-dev libavformat-dev libswscale-dev libv4l-dev
$ sudo apt-get install libxvidcore-dev libx264-dev
$ sudo apt-get install libgtk-3-dev
$ sudo apt-get install libcanberra-gtk*
$ sudo apt-get install libatlas-base-dev gfortran
$ sudo apt-get install python3-dev
- 下載OpenCV4.0版至RPi4 。
$ cd ~
$ wget -O opencv.zip https://github.com/opencv/opencv/archive/4.0.0.zip
$ wget -O opencv_contrib.zip https://github.com/opencv/opencv_contrib/archive/4.0.0.zip
- 並解壓縮檔案
$ unzip opencv.zip
$ unzip opencv_contrib.zip
- 建立opencv 和 opencv_contrib資料夾及將檔案放置資料夾內
$ mv opencv-4.0.0 opencv
$ mv opencv_contrib-4.0.0 opencv_contrib
- 先在opencv資料夾內建立名為build的資料夾
$ cd ~/opencv
$ mkdir build
$ cd build
- 使用CMake來設置OpenCV 4環境(從這步驟開始是最花時間)
$ cmake -D CMAKE_BUILD_TYPE=RELEASE \
-D CMAKE_INSTALL_PREFIX=/usr/local \
-D OPENCV_EXTRA_MODULES_PATH=~/opencv_contrib/modules \
-D ENABLE_NEON=ON \
-D ENABLE_VFPV3=ON \
-D BUILD_TESTS=OFF \
-D OPENCV_ENABLE_NONFREE=ON \
-D INSTALL_PYTHON_EXAMPLES=OFF \
-D BUILD_EXAMPLES=OFF
- 調整RPi4的SWAP交換空間,來解決編譯OpenCV記憶體不足的問題。
$ sudo nano /etc/dphys-swapfile
請把 CONF_SWAPSIZE=100改成 2048
- 重新開啟SWAP服務
$ sudo /etc/init.d/dphys-swapfile stop
$ sudo /etc/init.d/dphys-swapfile start
- 開啟四核心編譯OpenCV
$ make -j4
- 安裝OpenCV
$ sudo make install
$ sudo ldconfig
- 重新調整RPi4的SWAP 交換空間
$ sudo nano /etc/dphys-swapfile
將CONF_SWAPSIZE=2048改成 100
- 重新開啟SWAP服務
$ sudo /etc/init.d/dphys-swapfile stop
$ sudo /etc/init.d/dphys-swapfile start
Step6. 實現影像分類於RPi4
- 將Step2 下載模型及標籤檔解壓縮後透過MobaXterm傳入RPi4中
- 匯入OpenCV 檔於專案資料夾內

- 查詢OpenCV 版本,會顯示4.0.0版
$python3
>>> import cv2
>>> cv2.__version__
'4.0.0'
>>> exit()
可回到指令列

- 在RPi4實現影像分類推論!
- 在執行程式之前需要下載分類器的檔案,連結: https://reurl.cc/4R3dVL
連接上Webcam 至RPi4 USB中,本文範例是將下列指令寫入RPi4的Terminal裡執行,讀者們亦可輸入至MobaXterm。
$ python3 TM2_tflite.py --model model.tflite --labels labels.txt則可成功開啟畫面。

- 以下是辨識結果:nothing
- 以下是辨識結果:RaspberryPi
- 以下是辨識結果:mouse
- 以下是辨識結果:Bruce Lee
所有步驟在此告一段落,希望讀者們能夠做出屬於自己專案或用於生活當中,謝謝大家!