Federated Learning for IoT
Follow article
 Dave from DesignSpark
Dave from DesignSpark
How do you feel about this article? Help us to provide better content for you.
Dave from DesignSpark
Thank you! Your feedback has been received.
Dave from DesignSpark
There was a problem submitting your feedback, please try again later.
Dave from DesignSpark
What do you think of this article?
Back in May of 2022, there was a great deal of excitement among radio astronomers when the first image of the supermassive black hole at the centre of our Milky Way galaxy was unveiled:

Although it may not look particularly interesting to the untrained eye, the image captured by the Event Horizon Telescope (EHT), is both a scientific and technological triumph. The image is of Sagittarius A* (or Sgr A* for short) a dark object four million times more massive than our Sun. Although it isn't possible to directly see an event horizon, as this is the point in the gravity well that even light can no longer escape the black-hole's gravity, glowing gas orbiting a dark central region (called a “shadow”) is a tell-tale signature. The image is a significant addition to understanding the physics of galaxy formation.
What’s interesting from the tech perspective is that Sagittarius A* is more than 26,000 light years away and resolving this image required a radio telescope with the diameter of the earth. If you hadn’t noticed an earth-sized radio dish hanging off the side of our planet, it’s not because you’re lacking powers of observation. EHT synthesises such a large aperture by a technique known as interferometry using an array of eight existing radio observatories across the planet linked together to form a single “Earth-sized” virtual telescope.
The image was produced from the EHT Collaboration’s 2017 observations by averaging together thousands of images which fit the EHT data set. The averaged image retains commonly seen features in the varied images while suppressing features that appear infrequently. In some ways, this process is analogous to the concepts behind federated learning.
Federated Learning 101
Traditionally, machine learning is a seriously data-hungry business. Optimization algorithms like Stochastic Gradient Descent need huge datasets, partitioned homogeneously across servers in the cloud to train the models, improve their accuracy and (hopefully) eliminate bias. As these algorithms are highly iterative, they require low-latency, high-throughput connections to the training data if they are going to be anything approaching efficient.
Herein lies a problem: how do you keep that data secure and ensure privacy, especially in areas like medical data collection where privacy is mandated by law?
One solution is to use federated learning where a current machine learning model is downloaded from the cloud by an edge device. The device will train the model locally using the data it collects. A summary of the changes to this locally trained model would then be sent back to the cloud, using encrypted communication. The changes are aggregated with other locally-trained model updates to average weights and create a consolidated, global model that forms the new shared model for download by the edge devices.
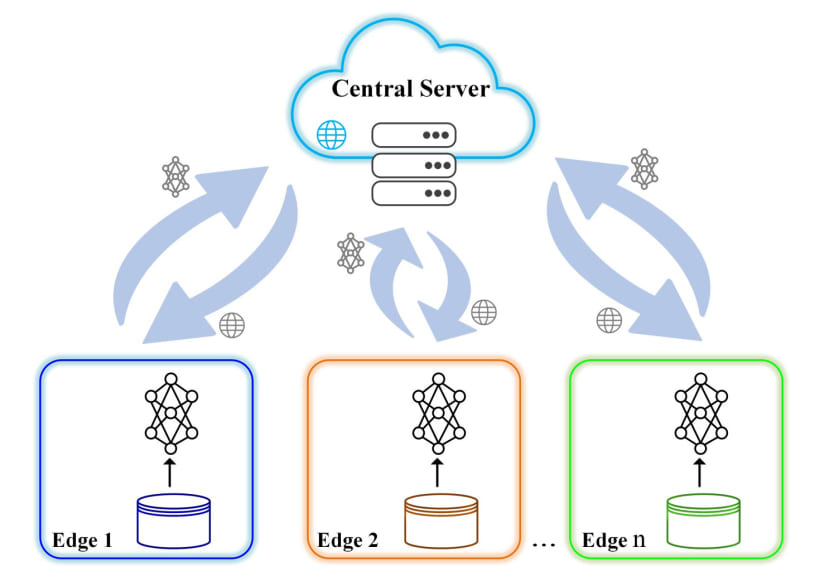
The obvious advantage here is that only the updates to the model are sent to the central server; the local data stays on the edge device, enhancing security and maintaining data privacy.
Advantages & Disadvantages
However, like any engineered solution, there are pros and cons to this approach. Let’s look at the upside first.
As we have already stated, only the update to the model is sent to the cloud, using encrypted communication. There, it is immediately averaged with other device updates to improve the shared model. All the training data remains on the device, and no individual updates are stored in the cloud. This makes it possible to apply machine learning to restricted-access datasets, like medical information.
The training data collected by the device is by definition, real-world data; not proxy data assembled by a data scientist from whatever was available. This means the model is being trained for real interactions with the messy analogue world, not best-guesses.
This approach also makes real-time predictions possible as they are determined on the device itself. Federated Learning eliminates the indeterminate time lag presented by transmitting raw data to a central server and then sending the prediction results back to the device. This also means that vast amounts of internet bandwidth are not needed for raw data transmission and, with the model(s) on the device, the prediction process will work even when there is no internet connectivity.
The downside is that federated learning has a number of challenges to implementation. How well these are overcome will determine the viability of the models being produced. Unlike a typical distributed optimization problem, federated learning data is distributed across potentially millions of devices in a highly uneven fashion. This means that the optimisation algorithm has to overcome:
Non-IID (Independent, Identically Distributed) training data: Usage of the device (e.g. a mobile phone) will be peculiar to the user/location/circumstances of the setup, so any local dataset will not be representative of the population distribution.
Unbalanced data: Some devices will have much heavier usage than others, leading to varying amounts of local training data.
Varying levels of device participation: only a small fraction of the devices may be active at once.
Hardware variability: affecting storage, computation, and communication capabilities of each device in the network; including handling dropped devices.
Communication bottlenecks: Limited communication devices may be frequently offline or on slow or expensive connections so global training requires communication-efficient methods that reduce the total number of communication rounds; iteratively sending small model updates as part of the training process.
Computational Costs
All these factors mean there is a level of computational cost incurred to generate model updates, though this is probably not in the way you expect.
Data centre optimization incurs minimal communication costs and it is the computational cost that dominates - which is why such heavy emphasis has been placed on using GPUs to lower that overhead. In federated optimization, communication costs dominate - particularly in terms of limits on bandwidth. Many devices will be limited to an upload bandwidth of 1 MB/s or less and this will be only when connected to an external power supply and/or unmetered wifi. Also, many devices would only be able to participate in a small number of update rounds per day. On the flip side, modern ARM-based microcontrollers or mobile phone processors are relatively powerful and would be working on a small dataset on the device, so in this instance computation costs become negligible.
The goal in federated optimisation then, is to have the client device perform more complex calculations between each communication round, in order to decrease the number of rounds needed to train a model, minimising the communication overhead.
Real World
It probably won’t surprise you to learn that Google has done a lot of research into Federated Learning and there is a TensorFlow Federated, complete with wrappers for Keras to create models. If you would like to try it out, there are tutorials available.
As Google themselves admit, they have only begun to scratch the surface of what may be possible with this approach. In many ways, the techniques employed in Federated Learning open the door to some interesting possibilities to solve larger problems using data that is never seen by the problem solver.
The ideas behind what is called oblivious transfer aren’t new, though they have proven historically difficult to implement efficiently. Andy Yao's Millionaire’s Problem, introduced in 1982 as a thought experiment on privacy-preserving multiparty computation, was a famous excursion down this rabbit hole. The problem, in a nutshell is: Alice and Bob are millionaires who want to determine who is richer but cannot (or will not) divulge their exact worth either to each other or a third party. How do they determine who is richer?
The answer to that question lies in cryptography and opens the way to using data owned by others for solving large-scale problems. OpenMined is an organisation that takes this idea of Remote Data Science very seriously, believing it could lead to datasets large enough to cure diseases and solve (currently) intractable science problems. They will even teach you how to do it!
Final Thoughts
Federated Learning has a lot of potential as it aggregates results and identifies common patterns from a large number of devices, which will tend to make for a robust operational model. At the same time, it is creating something of a new era in secured AI by protecting sensitive local information from abuse. That’s got to be welcome on both counts.
Maybe some Google Manga can shed some extra light on the potential. I will also leave you with another, more scholarly look at where federated learning may go.