NVIDIA Jetson Nanoのハンズオン
この記事を購読
 Dave from DesignSpark
Dave from DesignSpark
こちらの記事について、内容・翻訳・視点・長さなど、皆様のご意見をお送りください。今後の記事製作の参考にしたいと思います。
Dave from DesignSpark
Thank you! Your feedback has been received.
Dave from DesignSpark
There was a problem submitting your feedback, please try again later.
Dave from DesignSpark
こちらの記事の感想をお聞かせください。

機械学習処理に用いる「CUDA」に対応した安価な開発ボードで組込みAI端末を手軽に開発
人工知能(AI)は、自動運転から医療用の画像分析まで、幅広い用途での応用が検討されています。しかし、通常、従来のコンピュータビジョンアルゴリズムよりも桁違いの演算能力が必要となってしまいます。この演算能力を実装しようとすると、電力、コスト、サイズといった制約がボトルネックとなり実装できませんでした。
しかし近年、「専用のハードアクセラレータ」の出現と「強力なGPU技術」の応用により、この状況が変わり始めています。特に後者の「強力なGPU技術」についてはNVIDIA社が組込み業界向けへのアプローチとしてJetsonファミリを展開しており、その中でNanoボードは最もコンパクトでコスパが良いソリューションとして位置付けられています。
CUDA 101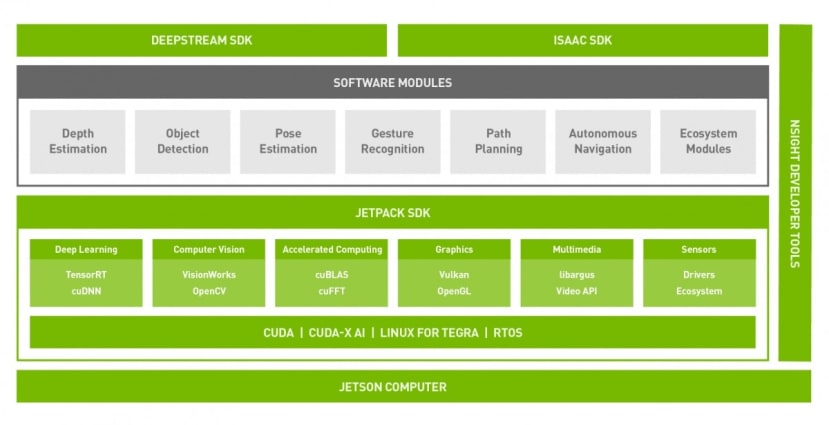 JetsonのSoftware構成
JetsonのSoftware構成
Wikipediaによると、CUDA (Compute Unified Device Architecture)は、NVIDIAが作成したパラレルコンピューティングプラットフォームとアプリケーションプログラミングインターフェイス(API)モデルです。これは、元々グラフィック専用だったグラフィックス・プロセッシング・ユニット(GPU)を汎用(General Purpose)に使用する技術で、別名GP-GPUと呼ばれています。これが興味深いのは、最新のグラフィック・プロセッサは、性能の点でいえば少し前のスーパーコンピュータに匹敵する点です。
しかし、スーパーコンピュータについて言えば、単にコードを再コンパイルするだけで、突然マシンの潜在能力がフルに発揮されることは、ほとんどありません。GPUも同様で、プロセスやスレッドの最適化により初めて優れた性能を発揮します。既存アプリケーションようにOS任せで良いという単純なものではありません。
そこでCUDAの出番です。CUDAは、NVIDIA GPUのパワーを最大限に発揮できるC/C++拡張アクセラレーション・ライブラリのセットで、ハイパフォーマンス・コンピューティング(HPC)で人気の高いFORTRANへの組込みも対応しています。その他にも、数多くのプログラミング言語用のラッパーがあり、さらにドメイン固有のフレームワークやアプリケーションのエコシステムも増え続けています。
ハードウェア 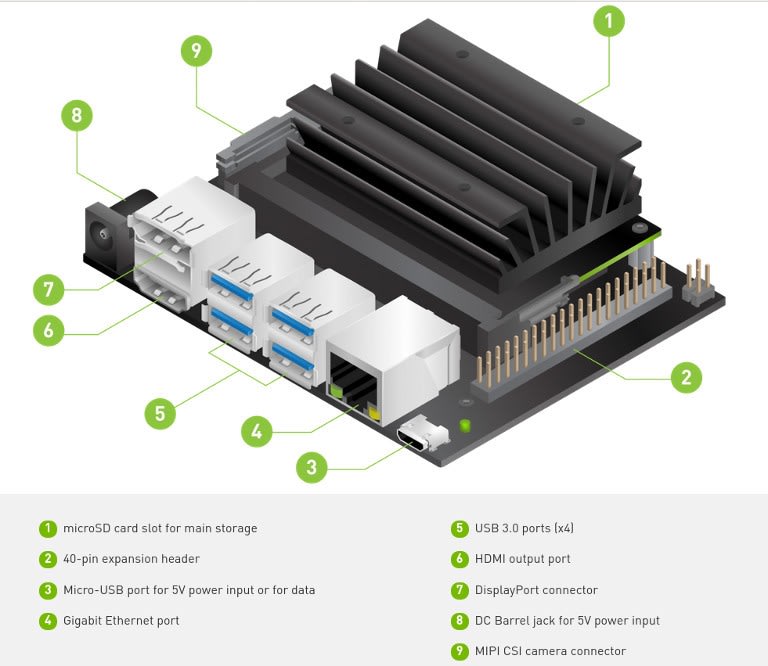
Jetsonファミリの歴史は意外と長く、Jetson TK1ボードをリリースした8年近く前の時点から既にNVIDIAは組込みアプリケーションにおけるGPGPUの可能性を認識してきました。2019 年 3 月に発表されたJetson Nano は、以前よりもはるかに低価格で CUDA のパフォーマンスを提供し、より多くの市場やアプリケーションに技術を開放しました。
では、Jetson Nanoは具体的にどのような機能を備えているのでしょうか?
- 0.5 TFLOP (FP16)の NVIDIA CUDA® コア を128個搭載したNVIDIA Maxwell™ アーキテクチャ
- クワッドコアARM® Cortex®-A57プロセッサ
- 4 GB 64ビットLPDDR4
- 16 GB eMMC 5.1フラッシュ
- Video encode (250MP/sec) and decode (500MP/sec)
- Camera interface: 12 lanes (3x4 or 4x2) MIPI CSI-2 DPHY 1.1 (18 Gbps)
- HDMI 2.0 or DP1.2 | eDP 1.4 | DSI (1 x2) 2 simultaneous
- 1 x 1/2/4 PCIE、1 x USB 3.0、3 x USB 2.0
- 1x SDIO / 2x SPI / 4x I2C / 2x I2S / GPIOs -> I2C, I2S
- 10 / 100 / 1000 BASE-Tイーサネット
これらすべてが69.6 x 45 mm SO-DIMMモジュールに収納されています。
当然、USB、HDMI、カメラなどのコネクタを備えた拡張ボードとバンドルされたキット品 Developer Kit (199-9831) も用意されています。これにはM.2スロットも含まれています。つまり、Micro SDカードスロットとJetsonモジュールオンボード16 GBフラッシュに加えて、高容量 / 高性能ストレージ用のSSDをストレージにすることもできます。
豊富なGPIOは、Raspberry Piのような40ピンヘッダを介して提供されます。このヘッダは、一般的なRPi.GPIOライブラリと同じAPIを備えたライブラリを介してサポートされます。つまり、ちょっとした入出力を行う程度のアプリケーションなら、比較的簡単にポーティング移植が出来るという事です。さらに、このDeveloper Kitは、Raspberry Pi Camera (913-2664) も利用することができます。
要するに、GPUを使用しないアプリケーションの開発でも、Jetson Nanoは非常に魅力的なシングルボード製品と言えます。
セットアップ
NVIDIAのスタートアップガイドでは、電源として5V/2A以上のMicro USBアダプタを指定しています。これを満たさないアダプタは必要な電流を供給できず、トラブルになる可能性があります。また Micro USBの代わりに、5.5 / 2.1 mm DC電源アダプタ使用することもできます。この方法を使用する場合は、4 A電源を推奨します。
Raspberry Pi公式の3Aの電源アダプタ (187-3416) でも良いでしょ。5.5 / 2.1 mm DC電源アダプタ、5 V 4 A RS PROデスクトップ電源 (175-3274) も、接続された周辺機器に十分な余剰容量を提供する必要があります。バレルコネクタを使用する場合は、J48にジャンパを取り付ける必要があります。

こちらガイドには、マイクロSDカード・イメージのダウンロードリンクと、その書き出し方法が記載されています。ダウンロードしたファイルを解凍し、Linux上で次のコマンドをタイプします:
$ sudo dd if=sd-blob-b01.img of=/dev/mmcblk0 bs=4M status=progress conv=fdatasync
このddコマンドを使用する際には注意が必要です。of パラメータは、ご使用になるコンピュータ毎に異なっているかもしれません。conv=fdatasync オプションは、処理終了前にバッファをフラッシュ(同期)したいことを意味します。これにより、dd コマンドが完了した後に sudo 同期を入力する必要がなくなります。
Micro SDカードを挿入し、電源を接続した後は、キーボード、モニタ、マウスを接続する必要があります。ただし、DVIモニタとアダプタケーブルは機能しないため、適切なHDMI又はDisplayPortインターフェイスを備えたモニタを使用する必要があります。さらに、ライブカメラ認識デモを実行する場合には、Raspberry Pi Camera v2 (913-2664) など、接続されたカメラも必要です。
最初の起動時に、セットアッププロセスが開始され、キーボードの言語やタイムゾーンなどが設定されます。その一部として、他のタスクの中で、最初のユーザーアカウントが作成されます。このプロセスが成功しなければ、次のブートでUARTヘッダの端子セッションでセットアップを完了するように指示されます。したがって、最初の起動でUSBキーボードとマウスとともに互換性のあるモニタが接続されていることを確認することが重要です。
最初のセットアップ後、お馴染みのUbuntuデスクトップが表示され、Jetson Nanoはほとんど他の小型コンピュータと同様に使用できます。まず真っ先に行う事は、ターミナルを開き、インストールされたすべてのソフトウェアを最新にバージョンアップすることです。
$ sudo apt update
$ sudo apt dist-upgradeSSHサーバーはデフォルトで起動されるため、直接ネットワーク経由で接続することもできます。
JetPack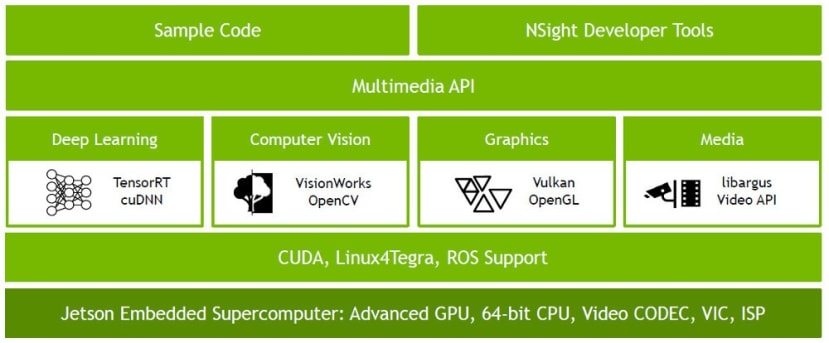
NVIDIA JetPack SDKには、OSイメージ、ライブラリ、API、サンプル、開発ツール、ドキュメントが含まれています。適切に構成されたLinuxカーネルとNVIDIAドライバとともに、先ほど書いたUbuntuベースのリファレンスOSイメージは、JetPackで事前入力されており、以下のライブラリとサンプルコードを提供します。
- CUDA
- 高性能な深層学習推論のためのTensorRT SDK
- ディープニューラルネットワークのための cuDNN GPU 加速ライブラリ
- ビデオエンコード / デコードなどのためのマルチメディア(MM)API
- コンピュータビジョン及び画像処理用 OpenVXベースツールキット VisionWorks
- コンピュータビジョン、画像処理、機械学習のためのOpenCVの一般的なライブラリ
- Vision Processing Interface (VPI) library
自分でインストールする必要がなく、より早く稼働させることができます。
デモ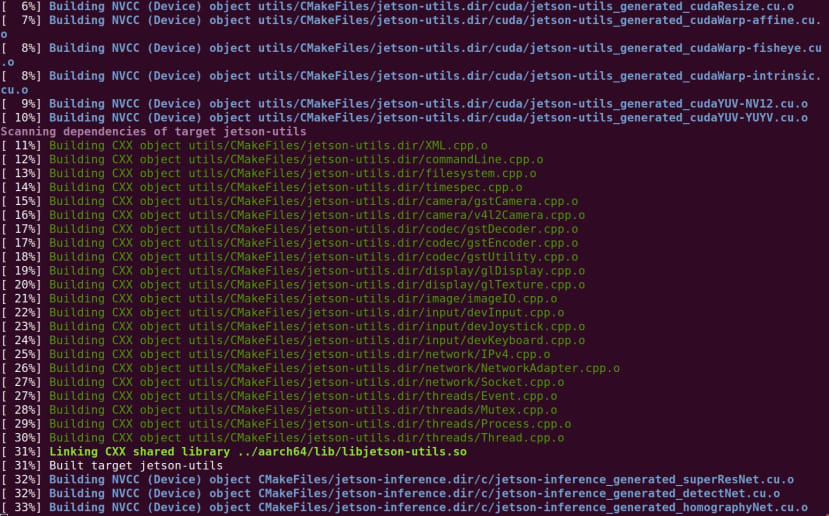
NVIDIAサイトやコミュニティでは、サンプルコードだけではなく、オンラインの自己学習コースやユーザのプロジェクトファイルが随時追加されています。「Two Days to a Demo」と命名された自己学習コースには、「NVIDIA Jetson AGX Xavier、Jetson TX2、Jetson TX1、Jetson Nano」でAIとコンピュータビジョンをフィールドに展開するためのディープラーニングチュートリアルシリーズで、その名前が示すように、最初からデモ完了まで約2日かかるコースになっています。これには、ディープラーニング推論デモのセット「Hello AI World」が含まれています。
デモをセットアップするには、次のコマンドを実行する必要があります。
$ sudo apt update
$ sudo apt install git cmake libpython3-dev python3-numpy
$ git clone --recursive https://github.com/dusty-nv/jetson-inference
$ cd jetson-inference
$ mkdir build
$ cd build
$ cmake ../
$ make
$ sudo make install
$ sudo ldconfig
このプロセスで、ダウンロードしたい「事前トレーニング済みのニューラルネットワーク」を選択するように求められます。

また、トレーニング済みのモデルを別のタスクのモデルのスタートポイントとして使用する転送学習を含むデモを実行したい場合に必要なPyTorchをインストールするように求められます。必要に応じて、追加モデルとPyTorchの両方を後でインストールできます。詳細については、GitHubリポのドキュメントを参照してください。
さて、ついにデモを実行してみましょう!
「Hello AI World」は、次のようなカテゴリで構成されています。
- ImageNetで画像を分類
- DetectNetでオブジェクトの位置決め
- SegNetでセマンティックセグメント
- PyTorchでの転送学習
1つ目のものは画像認識であり、ここではシーンやオブジェクトを特定しようとしています。2つ目は、もう一歩進み、フレーム内のオブジェクトを見つけます。セマンティックセグメントには、ピクセルレベルでの分類が必要ですが、ドライバレス車で使用されるように、環境認識に特に役立ちます。先ほど簡単に述べた転送学習です。
画像を分類する最初のカテゴリのデモを見てみましょう。このデモは2つのパートに分かれています。1つはコンソール・プログラムで、ネットワークに静止画を入力するもの、もう1つはライブ・ビデオ・ストリームを入力するものです。後者を実行し、ビデオにPi Cameraを使用してみましょう。デフォルトオプションでこれを実行するには、端子に次のコマンドを入力するだけです。
$ imagenet-camera
短い遅延の後、ビデオウィンドウが表示されます。フレームの上部に分類されたオブジェクト / シーンと信頼性の数字が付いたテキストが表示されます。
デフォルトでは、ニューラルネットワークとしてGoogleNetが使用され、1,000個のオブジェクトクラスを含むImageNetデータセットでトレーニングされています。ご覧のように、シーンが不明で、認識するようにトレーニングされていない場合、出力は多くの信頼性の低い分類でジャンプします。しかし、それが認識するようにトレーニングされたオブジェクトが現場の最前線になると、それはそれを識別するのに非常に良い仕事をします。
AlexNet、ResNet-152、Inception-v4など、「--network」引数を使用して代替ネットワークを指定することもできます。これらはすべて、事前にトレーニング済みのモデルとして提供されています。さらに、これらは、ゼロからまたは転送学習を通じて、特定のアプリケーションにはるかに適しているカスタムデータセットを使用してトレーニングされることもあります。たとえば、このネットワークは、工場環境で品質コントロールの適合と不良を分類するようにトレーニングされたネットワークであるかもしれません。また、職場での潜在的な危険な状況もあります。
ここで注目すべき重要なことは、ニューラルネットワークがどのくらいの速度で推測を行うかです。このピークは70フレーム/秒(FPS)を超えるため、かなり高速です。もちろん、パフォーマンスはネットワークによって異なりますが、それでも優れています。
パフォーマンスについては、CPU使用量や熱などの情報を提供するTegraStatsツールで次のように確認できます。
$ tegrastats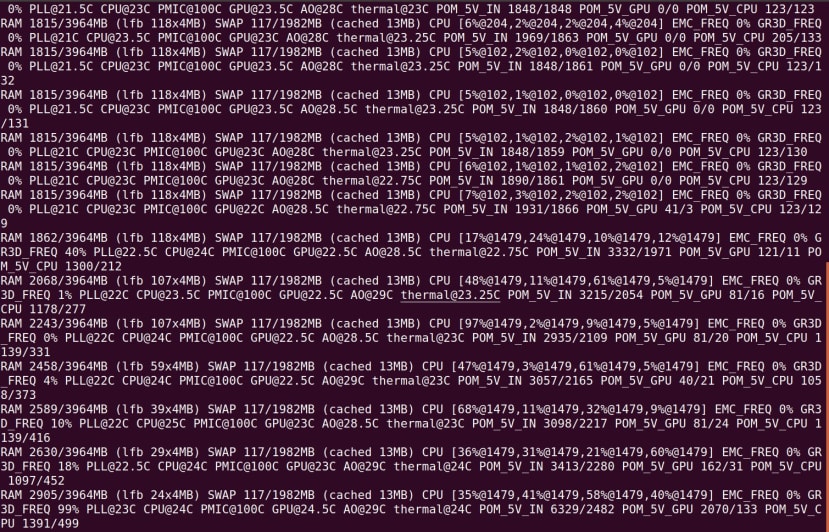
上記のスクリーンショットでは、最初にCPUがアイドル状態であることがわかります。その後、imagenet-cameraアプリケーションが開始されます。この時点で、ビデオストリームが開始されネットワークに負荷がかかり始めると、CPUの使用量がピークになり、その後ビデオストリームが安定し始めます。
まとめ
Jetson Nanoは、小さなフォームファクタに大量のパッケージを組み込み、以前は実用的でなかったかもしれない組み込みアプリケーションにAIやそれ以上のものをもたらします。この記事では、ほんの上辺か見きれておらず、シンプルなニューラルネットワーク推論デモを実行しただけでしたが、NVIDIA及び広範なコミュニティが提供するさまざまなサンプルや学習リソースを入手することでより幅広いアプリケーションの開発が容易に行えます。