Pytorch深度学习框架X NVIDIA JetsonNano应用-cDCGAN风格转换,图片自动填色
关注文章
 戴夫来自 DesignSpark
戴夫来自 DesignSpark
你觉得这篇文章怎么样? 帮助我们为您提供更好的内容。
戴夫来自 DesignSpark
Thank you! Your feedback has been received.
戴夫来自 DesignSpark
There was a problem submitting your feedback, please try again later.
戴夫来自 DesignSpark
你觉得这篇文章怎么样?
|
作者 |
张嘉钧 |
|
难度 |
中偏难 |
|
材料表 |
|
Pix2pix
说到风格转换第一个想到的就是 pix2pix,他算是很早期透过 cGAN 的方式去完成图像与图像之间的翻译,是风格转换的经典作品之一,风格转换有很多种有趣的应用,像是从语意分析图转换成实体图片,又或者将卫星地图转换成简化地图,也有给轮廓去填颜色,这些都算是风格转换也算是 pix2pix 提供范例的范畴。
风格转换 Style Transform
风格转换的概念其实很简单,只要将输入跟输出改变一下就可以完成风格转换了。原本图片生成的部分生成器的输入是一组噪声、输出是图片,就像下图一样:

现在只要把他改成输入是一个风格的图片、输出是另一种风格的图片,那我们就完成风格转换了~不过在这边我们的数据必须是对应的,如下图来说A风格的数字5跟B风格的数字5就是对应的:

Pix2pix重点技术简介
1.运用cGAN的架构 ( 以训练鉴别器为例 )
下图可以看到输入是A风格而经过生成器后会产生B风格的图片,这时候A风格跟B风格都要丢进鉴别器,主要用意是在轮廓都是A的状况下,鉴别器要去区分是真实颜色还是由生成器所生成出来的。

2.生成器采用 U-Net结构
论文中有提到生成器的架构有两种,一种是AutoEncoder的架构;另一种是U-Net的架构,作者提出来的论点主要在输入与输出的差别只有在「表面外观」不同,实际的「基础结构」是相同的,如果常看卷积神经网络的读者应该知道,卷积神经网络的浅层主要都在色块而深层特征比较多是在轮廓等结构上,所以使用U-Net结构可以让结构的讯息被共享,白话一点就是可以让轮廓这类型的特征在神经网络中更突出。

3.鉴别器使用 PatchGAN的技术
鉴别器运用了PatchGAN的技术,一般的GAN都是在输出的时候给予一个数值( 0或1 ),但是PatchGAN的技术是给予N*N的矩阵 (每一个位置也是 0或1),每一个数值都代表一个Patch,可以想象把图片切成很多个区块去判断成像是否真实,因为判断的区域较小可以顾及到的细节更多,而相对的整体上细节也就会更好,特别是Patch数量越多的时候。

4.损失函数加入了L1正规化
主要是L1会让数值区间更窄,表示让图像均值化,当RGB都相近的时候会越接近灰阶,而 cGAN则是目标要让图片有更多颜色。
实现 pix2pix
毕竟是经典之作,现在github上有提供很多PyTorch去实作pix2pix的程序,我看了几个觉得这个整合度比较高,他将pix2pix跟CycleGAN整合在一起,此外也写了PyTorch跟Tensorflow的版本,所以我们就用这个 github来体验一下pix2pix吧!
1.下载github
如果没安装过git则需先安装,下载完后档案结构如下图:
pip install git
git clone https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix

2.安装需求套件
接着在档案目录中可以找到 requirements.txt,我们只需要执行下列程序进行套件安装:
pip install -r requirements.txt套件如下,其中torch跟torchvision就是必备套件,dominate跟visdom是用于可是化的套件,跟tensorboard一样需要在开启server才能进行观察。

3.下载数据集
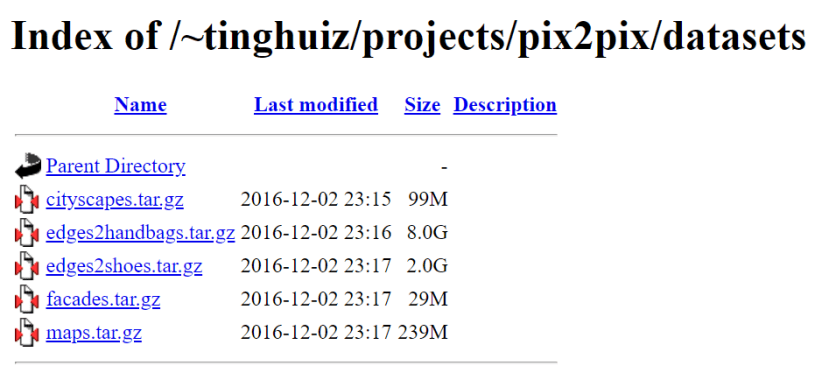
根据论文提供的数据集,总共有五种可以下载!今天我们想要让计算机尝试去填颜色,所以我们可以选择 edges2shoes来玩玩看,下载后解压缩到pytorch-CycleGAN-and-pix2pix/datasets当中:
|
数据集链接:https://people.eecs.berkeley.edu/~tinghuiz/projects/pix2pix/datasets/ |
 |
Edges2shoes中有两个文件夹 ( train, val),每张图片大小为 ( 256 , 512 ) ,代表是将轮廓图与原始图合并在一起,左边为轮廓右边为原始图,所以如果之后我们要预测自己的图也必须符合这个形式:

4.下载欲训练模型
接下来就要下载欲训练模型了,一样提供5种,请找到跟数据集对应的下载:
|
欲训练模型载点:http://efrosgans.eecs.berkeley.edu/pix2pix/models-pytorch/ |
 |
下载完后放置到pytorch-CycleGAN-and-pix2pix\checkpoints\edges2shoes_pretrained底下,并且更名为 latest_net_G.pth,通常需要自己新增文件夹checkpoints、edges2shoes_pretrained。
这边可以注意到.pth文件是PyTorch的其中一种模型文件,它包含了神经网络模型以及权重,储存跟读取都很方便,缺点就是自由度不高,官方也比较倾向只储存权重的方式,不过这部分就不是今天探讨的范围了。
5.进行预测
首先,需要先将数据集中的val 更名为 test,接着执行程序:
python test.py --dataroot ./datasets/edges2shoes --name edges2shoes_pretrained --model pix2pix --direction BtoA--dataroot 就是数据集的位置
--name 是checkpoint的文件夹,也就是模型、权重的文件夹名称
--model 有 cycleGAN与pix2pix可选择
--direction 是风格转换方向;要将轮廓填满还是将填满的转成轮廓
6.执行结果
最后结果将会输出在pytorch-CycleGAN-and-pix2pix的results当中,有个别的图档也有作者整理在网页上的比较图,下图撷取部分html上的结果。可以看到效果还蛮有趣的,大致的轮廓其实掌握得很好,但颜色都会稍微有一点色偏。

玩转 pix2pix
我在找pix2pix的时候找到一个很厉害的大神,他自己做了猫咪数据集并且放在交互式网页上https://affinelayer.com/pixsrv/,我就在思考自己或许也能做一个阳春版的。

既然有了决断就只差执行了!我就直接拿预训练好的edges2shoes来尝试,要做到这个首先需要做一个手写绘图版,这次我使用的是 pyqt5 ,它是 Python 用来撰写 GUI的套件之一,可以取代内建的TKinter,我个人蛮喜欢它是它有一个Qt Designer可以像 Visual Studio 拉窗口程序那样处理,相对来说方便许多。

不过今天我们要制作极简手绘版就不需要这个Qt Designer了,一切从简~
首先记得没安装pyqt5的要先安装一下
pip install PyQt5先在那个github中建立一个新的 Jupyter Notebook,我们可以透过终端机开启 Notebook,输入:
jupyter notebook开启后,在右上角new的地方新增 python3 档案即可,这边我命名为 drawpad。

首先要先定义窗口程序,设定标题、窗口显示的位置 ( 起始坐标x,起始坐标y,宽,高)
self.setWindowTitle("Paint with PyQt5")
merge = 40
size = canvas_size - merge
self.setGeometry(merge, merge, size, size)
接着建立一个全白的图片用于绘图
self.image = QImage(self.size(), QImage.Format_RGB32)
self.image.fill(Qt.white)
绘图的相关设定,状态变量、笔刷大小颜色以及鼠标最后的位置
self.drawing = False
self.brushSize = brush_size
self.brushColor = Qt.black
self.lastPoint = QPoint()
定义菜单以及对应功能,鉴于触碰屏幕的菜单有点难按所以我没增加到菜单中,不过有设定快捷键所以使用上还是很方便的,总共有三个功能,储存、清除、离开:
mainMenu = self.menuBar()
fileMenu = mainMenu.addMenu("File")
saveAction = QAction("Save", self)
saveAction.setShortcut(QKeySequence('Ctrl+s'))
fileMenu.addAction(saveAction)
saveAction.triggered.connect(self.save)
clearAction = QAction("Clear", self)
clearAction.setShortcut(QKeySequence('Ctrl+c'))
fileMenu.addAction(clearAction)
clearAction.triggered.connect(self.clear)
exitAction = QAction("Exit", self)
exitAction.setShortcut(QKeySequence('Ctrl+q'))
fileMenu.addAction(exitAction)
exitAction.triggered.connect(self.exitapp)
接下来就是绘图的关键,pyqt5在触碰上面好像有另外的写法,不过这边我就直接采用鼠标点击的方式来写,所以要先定义鼠标按下、拖曳、放开三个动作事件。首先是按下的时候,我们要先将状态设定成True并且纪录按下的位置:
def mousePressEvent(self, event):
if event.button() == Qt.LeftButton:
self.drawing = True
self.lastPoint = event.pos()
在鼠标拖曳的时候,要先实例化画布功能,实现在image上并且设定笔刷参数,接着划一条线从上一个位置到现在位置,最后更新位置信息并且刷新画布:
def mouseMoveEvent(self, event):
if (event.buttons() & Qt.LeftButton) & self.drawing:
painter = QPainter(self.image)
painter.setPen(QPen(self.brushColor, self.brushSize,
Qt.SolidLine, Qt.RoundCap, Qt.RoundJoin))
painter.drawLine(self.lastPoint, event.pos())
self.lastPoint = event.pos()
self.update()
最后放开左键的时候就将状态设为False,也就不会画线跟刷新了:
def mouseReleaseEvent(self, event):
if event.button() == Qt.LeftButton:
self.drawing = False
各种功能设定,第一个是画图的事件,需要先将画图功能打开,对象是主窗口,利用drawImage将刚刚的self.image绘制上去;第二跟第三个是为了绑定菜单跟快捷键而设计的副函式:
# 建立 painter 后还须建立画图的事件
def paintEvent(self, event):
canvasPainter = QPainter(self)
canvasPainter.drawImage(self.rect(), self.image, self.image.rect())
# 清除画布
def clear(self):
self.image.fill(Qt.white)
self.update()
# 离开窗口
def exitapp(self):
self.close()
接下来是储存图片的部分,储存图片的大小我是预设为画布大小所以会随着你的屏幕大小而改变,但是训练、测试数据维度大小为 (256, 256) 所以必须先重新朔形,此外还需增加Ground Truth的部分,不过因为是自己画得所以Ground Truth为空白,上述说的全都再initImage 这个副函式中执行,接着再储存的时候先进行储存 (self.image.save) 再进行前处理 ( iniImage):
def initImage(self, filepath):
trg_size = 256
new_img = np.zeros([256,512,3], dtype=np.uint8)
new_img.fill(255)
org_img = cv2.imread('{}'.format(filepath))
src_img = cv2.resize(org_img, (trg_size, trg_size) )
print('org_img {} > src_img {}'.format(org_img.shape, src_img.shape))
for h in range(trg_size):
for w in range(trg_size*2):
if w< 256:
new_img[h][w] = src_img[h][w]
else:
break
cv2.imwrite(filepath, new_img)
# 储存画布
def save(self):
filePath = {your path}
self.image.save(filePath)
self.initImage(filePath)
print('save image: ', filePath)
self.close()
以上宣告完,就是主要执行的阶段了:
# 实例化 app 这支程序
if not QtWidgets.QApplication.instance():
app = QtWidgets.QApplication(sys.argv)
else:
app = QtWidgets.QApplication.instance()
# 获得屏幕可使用范围
screen = app.primaryScreen()
rect = screen.availableGeometry()
print('Available: %d x %d' % (rect.width(), rect.height()))
# 宣告画布大小以及笔刷大小
canvas_size = rect.width() if rect.width() < rect.height() else rect.height()
brush_size = 10
# 实例化窗口
window = Window(canvas_size, brush_size)
# 显示窗口
window.show()
# 执行 app
sys.exit(app.exec())
接着下一个block的目标就是执行pix2pix并且查看成果,这边直接写了指令 (有点懒得整合),执行完成后再透过opencv来开启成果图,按任意键即可退出。
!python test.py --dataroot datasets\edges2shoes --model pix2pix --name edges2shoes_pretrained
ImPath = {your path} + ‘custom_edge_fake_B.png’
im = cv2.imread(ImPath)
cv2.imshow('result', im)
cv2.waitKey(0)
cv2.destroyAllWindows()
玩转pix2pix的执行成果
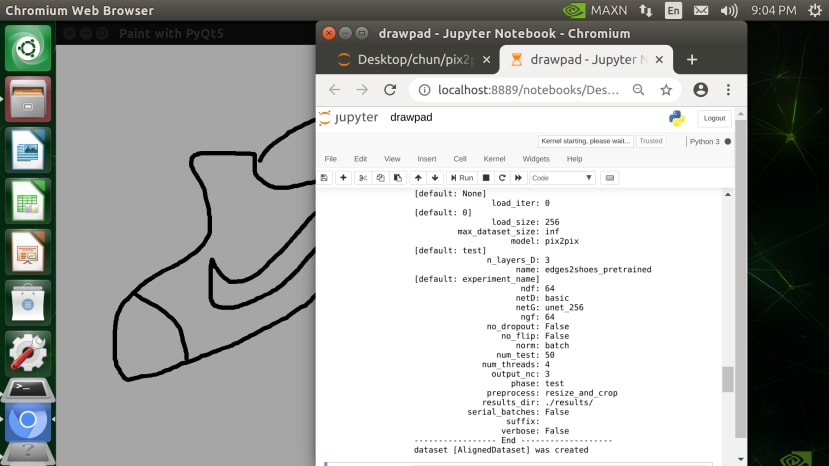
我有尝试用PC以及Jetson Nano都可以成功运行,当程序开始执行会跳出一个手绘板,

画完之后按 ctrl + s 就会自动储存到 test,接下来可以执行下一个 block的程序来利用
pix2pix 生成图片。
这边也提供了 PC 、Jetson Nano的DEMO影片:
结语
这次带大家认识了pix2pix,是不是很好玩?GAN很多应用都是相当有趣的~不过就是训练起来要人命,所以可以先尝试别人做好的预训练模型,来看能不能完成自己想要的结果。像是今天这个案例,如果我要做一个狗狗自动填色的其实就是在datasets中换成自己的数据就可以了。 下一次将带大家认识另个经典之作 CycleGAN,它与pix2pix都是属于风格转换,不过它的数据是可以不用成对的,下一篇会再仔细说明~
参考文章
AI修图!pix2pix网络介绍
https://www.itread01.com/content/1544921642.html
图像翻译——pix2pix模型
https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix
CycleGAN and pix2pix in PyTorch
https://codertw.com/%E7%A8%8B%E5%BC%8F%E8%AA%9E%E8%A8%80/662259/
Python GUI How to Create Paint Application in PyQt5 https://codeloop.org/python-gui-how-to-create-paint-application-in-pyqt5/