Pytorch深度學習框架X NVIDIA JetsonNano應用-實作Pre-Trained Model
关注文章
 戴夫来自 DesignSpark
戴夫来自 DesignSpark
你觉得这篇文章怎么样? 帮助我们为您提供更好的内容。
戴夫来自 DesignSpark
Thank you! Your feedback has been received.
戴夫来自 DesignSpark
There was a problem submitting your feedback, please try again later.
戴夫来自 DesignSpark
你觉得这篇文章怎么样?
- 預訓練模型 (Pre-Trained Model)、微調 (Fine-Tuning)、轉移學習 (Transfer-Learning) 之間的差異
- 使用PyTorch進行Pre-Trained Model的Inference
Pre-Trained Model 預訓練模型
當你在使用別人的Github的時候是不是常常看到「請下載 Pre-Trained Model」、「使用Pre-Trained Model運行」之類的話,就像下面這張圖片,這張圖是擷取自Jetson-Inference的Github:

Pre-Trained Model顧名思義就是 Pre是事先、Trained是訓練完的,所以中文通常都會翻譯成「預訓練模型」,那這個預訓練模型就是只能使用在他當初訓練好的數據集上,如果你想要利用他人的網路架構訓練自己的模型的話,就叫做「Transfer Learning 」,也就是我們對YOLOv5做的事情。
Transfer Learning 遷移式學習
遷移式學習的部分,我們再來一下語文課,Transfer代表我將這個模型從那個數據集中轉移到我這個數據集中去使用,Learning可以想像就是再次訓練、再次學習的意思,所以遷移學習 ( 轉移學習 ) 也就很好理解了,不過還有很重要的一個點是,Transfer Learning是基於模型在上一個數據集中訓練好的權重,再進行訓練!
Transfer Learning的方法:
進行遷移學習的方式有兩種:
- 特徵擷取 (Feature Extraction):凍結除了全連接層或者輸出層以外的權重,只訓練沒凍結的即可。
- 微調 (Fine-tuning):不採用隨機的權重初始,而是使用先前訓練好的權重當作初始值,在這邊可以全部都訓練也可以只訓練某一個部分,甚至說針對網路架構去做更動,也都算是Fine-tuning的範疇。
兩種方式的本質都是相同的,就是站在巨人的肩膀上看世界,之前訓練好的權重已經具有一定的特徵擷取能力,那我們面臨哪種狀況又該使用哪種方式去做呢?做Transfer Learning最主要的原因通常是數據量小,當數據量小就容易發生Overfitting,所以才需要用別人先訓練好的權重幫助我們避免特徵擷取的時候發生Overfitting的現象;而當數據量大的時候,通常都會建議從頭訓練或是進行全網路的微調;而當數據量小的時候又有分與原本的數據集是否相似等的狀況,這邊也整理了一個表格方便大家做整理。
|
數據集數量 |
數據集相似 |
使用方法 |
備註 |
|
小 |
相似 |
特徵擷取 |
由於內容相似,特徵擷取的結果也會符合需求,所以直接訓練線性分類的部分即可。 |
|
小 |
不相似 |
微調 |
這邊就比較特殊了,因為數據集不相似所以CNN的特徵擷取不一定適用,所以建議會從CNN的某一段就開始進行訓練。 |
|
大 |
相似 |
微調 |
數據量大又相似,建議還是透過對整個網路微調會較佳 |
|
大 |
不相似 |
微調 |
通常遇到不相似又數據量大的,會直接建議從頭訓練 (learn from scratch),當然也是可以嘗試進行全網路的微調,在大部分的狀況下微調是能幫助神經網路快速收斂的。 |
補充:增量學習 (Incremental Learning)
還有另一個要釐清的點,當你的訓練資料都是相同類別的而且不停地在更新,這時候用上的技術是叫做增量學習 ( incremental learning ),概念跟Transfer learning相似,但Transfer的定義比較像是你從A任務轉成B任務後,模型就會忘記A任務分辨的技巧;Incremental則是當A任務轉到B任務時他依舊記得A任務的技巧,又再學習了B任務的技巧,兩者還是有差別的,別搞錯囉!
PyTorch提供的Pre-Trained Model
PyTorch 等AI框架為了讓使用者方便學習,本身的API當中都會包含著著名的幾個神經網路模型可供大家使用,所以接下來我們就稍微對Pre-Trained Model進行介紹與實作。
在PyTorch的官方文件中可以找到 torchvision.model(如下圖),而這是在介紹PyTorch供使用者使用的網路模型,點擊名稱都會直接連結到該模型的論文,那接下來我將稍微針對幾個比較有名的模型做介紹。
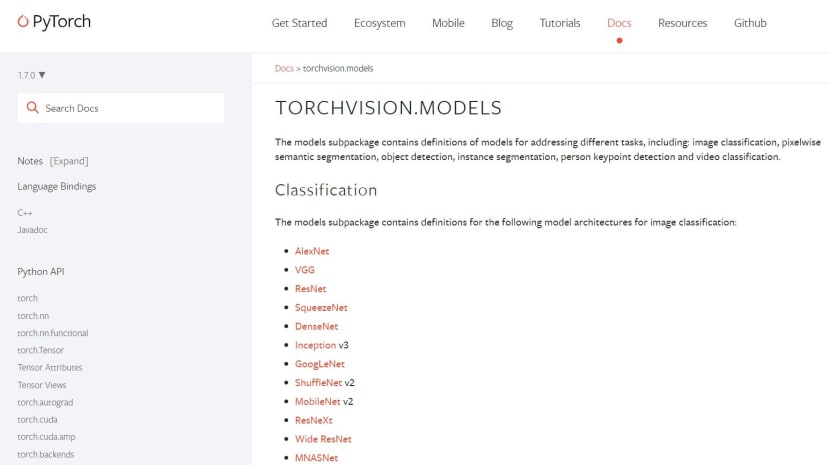
AlexNet (2012)、VGG (2014)、GoogleNet (2014)
這三個都是相當相當有名的神經網路模型,都是在ImageNet這個影像辨識的比賽中獲得名次,最明顯的差異就是他們的隱藏層一個比一個還要多,AlexNet是2012年的第一名,而這是開啟大AI時代的一個關鍵點,因為他們使用了GPU去做平行運算也使用了更深 (8層) 的卷積神經網路;接下來2014年ImageNet比賽中的第一名跟第二名分別是GoogleNet、VGG,那VGG的部分是探討了深度對於神經網路影響,深度來到了19層,其實跟AlexNet很像但調整了卷積層的數量跟Kernel大小;而GoogleNet又採用更深的神經網路來到了22層,並且導入了1x1的卷積層 (降維)、Global Average Pooling (全局平均池化)、Auxiliary Classifiers (輔助分類器),這些技術一直到現在都十分受用。
ResNet ( 2015 )
隨著網路層的深度增加,越來越長發生梯度消失的問題,所以ResNet就被研發出來了,他用的核心技術是殘缺塊 ( Residual Block ),經過實驗證明確實能改善梯度消失的問題,透過跳接的概念,如果某一層發生梯度消失也不會連帶影響其他的權重。

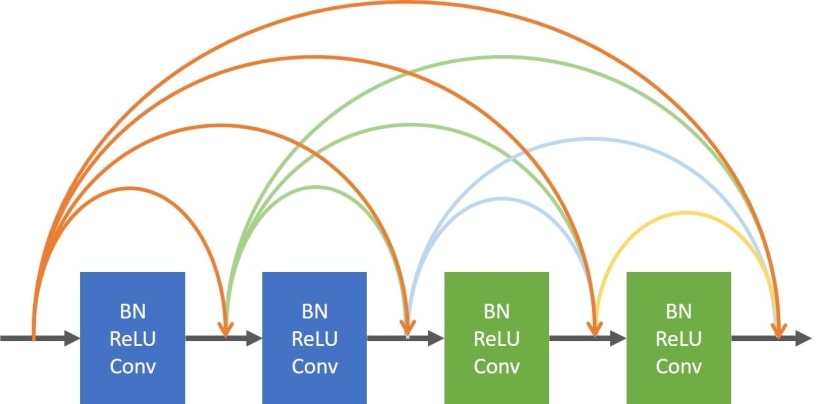
DenseNet ( 2016 )
DenseNet則是ResNet的進化版本,在DenseNet當中,每一層都會跟其餘層做連接,看似會讓權重變多,但實質則相反反而比傳統的一對一連接還要少。
Inception v3 (2015)
這個模型的第一代就是GoogleNet,一直到今年已經有了第四代了,中間變化的過程有興趣再自行研究囉~
Mobile Net v2 (2018)
Mobile Net是著名的輕量化網路,一直到現在各種邊緣裝置上都能見到他的身影,那第二代跟第一代的差異在於導入了Linear Bottleneck 和 Inverted Residual Blocks,我們今天的Pre-Trained Model也會利用Mobile Net來做實作。
使用Pre-Trained Model進行Inference
這裡需要先導入 torchvision.models,剛剛上面的圖片有提到有哪些可以模型可以導入,除此之外,在導入模型的同時你可以定義是否要用預訓練好的模型還是只是單純的模型架構:
import torchvision.models as models
target_model = models.mobilenet_v2( ) # 沒導入預訓練的權重
target_model = models.mobilenet_v2(pretrained=True) # # 導入預訓練的權重
在這邊官方的文件中有說建議是以下列的參數作為正規化的參數:
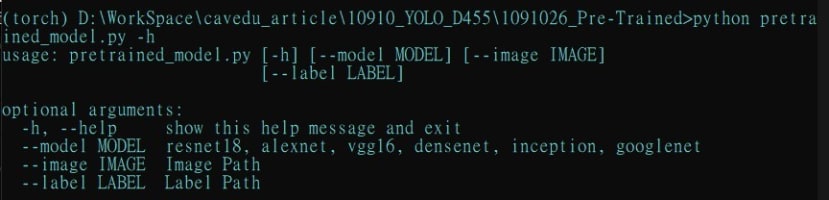
normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])那接下來就可以來寫程式了,在主要執行的部分我寫成透過命令列改變參數的方式,所以導入了argparse這個套件,並且將主要執行的程式寫在run_pretrained_model的副函式中,其中我提供了7個常見的模型選擇,然後自訂義要辨識的圖片、還有需要導入模型對應的標籤檔:
if __name__=="__main__":
parser = argparse.ArgumentParser()
parser.add_argument('--model', default='mobilenet', help="resnet18, alexnet, vgg16, densenet, inception, googlenet")
parser.add_argument('--image', default='image.jpg', help="Image Path")
parser.add_argument('--label', default='imagenet_classes.txt', help="Label Path")
args = parser.parse_args()
run_pretrained_model(args)
主要執行的函式如下,第一步是導入模型、標籤,接著設定PyTorch提供的資料處理torchvistion.transforms,要注意的是它吃的是PIL格式,一開始我用OpenCV讀圖檔,但當然可以一開始就用PIL,不過我提供給大家一個轉換的範例,在Inference前記得要將模型的模式調成eval (驗證模式),透過np.argmax找到最大的數值的位置,再將對應的Label顯示出來:
def run_pretrained_model(args):
### 打印參數
print_args(args)
### 導入預訓練模型、標籤
target_model = choose_model(args.model)
ls_label = read_txt(args.label)
### 先定義數據處理的部分
transform = T.Compose([ T.Resize(256),
T.CenterCrop(224),
T.ToTensor(),
T.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])])
### 透過 OpenCV 導入圖片
path = args.image
img = cv2.imread(f"{path}")
### PyTorch 吃PIL圖
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img_pil = Image.fromarray(img)
img_tensor = transform(img_pil).unsqueeze(0) # 將數據加一維,模擬batch_size
### 推論 Infernece
target_model.eval()
predict = target_model(img_tensor).squeeze(0)
### 找到最大的值 find max value
idx = np.argmax(predict.detach().numpy())
print("\n\n辨識結果: {}".format(ls_label[idx]))
其餘的程式碼分別是選擇模型 ( choose_model )、讀取txt檔 ( read_txt )、打印argparser的內容 ( print_args ):
def choose_model(n):
trg_model = None
if n=='resnet18':
trg_model = models.resnet18(pretrained=True)
elif n=='alexnet':
trg_model = models.alexnet(pretrained=True)
elif n=='vgg16':
trg_model = models.vgg16(pretrained=True)
elif n=='densenet':
trg_model = models.vgg16(pretrained=True)
elif n=='inception':
trg_model = models.inception_v3(pretrained=True)
elif n=='googlenet':
trg_model = models.googlenet(pretrained=True)
else:
trg_model = models.mobilenet_v2(pretrained=True)
return trg_model
def read_txt(path):
f = open(path, 'r')
total = f.readlines()
print(f'classes number:{len(total)}')
f.close()
return total
def print_args(args):
for arg in vars(args):
print (arg, getattr(args, arg))
這次我使用我們家的貓咪來當測試照片:

執行成果如下,如果是第一次使用pre-trained model它會自動幫你下載下來,這個部分是GoogleNet的成果:

可以看到結果為tabby cat,非常正確的是虎斑貓,那接下來來看一下還有什麼模型可以選擇:
接著我們使用densenet來看看有沒有辨識出不同的內容:

結果是都是相同的,其實這幾個都是各個年度的佼佼者,準確度都是嚇嚇叫,丟一些簡單的貓狗要難倒他們真的是不太可能~
結語
這次介紹Pre-Trained Model、Transfer Learning的差別,大家有沒有更加了解呢?如果有相關的問題歡迎留言提問,文章的結果也帶大家實作PyTorch提供的Pre-Trained Model,應用上也是非常的簡單,大家可以多方嘗試看看。
相關文章
CS231n: Convolutional Neural Networks for Visual Recognition