在Raspberry Pi 4設計GUI介面,匯入機器學習模型實現人臉辨識篇
关注文章
 戴夫来自 DesignSpark
戴夫来自 DesignSpark
你觉得这篇文章怎么样? 帮助我们为您提供更好的内容。
戴夫来自 DesignSpark
Thank you! Your feedback has been received.
戴夫来自 DesignSpark
There was a problem submitting your feedback, please try again later.
戴夫来自 DesignSpark
你觉得这篇文章怎么样?

|
作者 |
許鈺莨/曾俊霖 |
|
難度 |
簡單 |
|
材料表 |
一支網路攝影機 螢幕、鍵盤、滑鼠 |
本文章先備知識教學文章
使用Google Teachable Machine來實現Raspberry Pi 4 的影像分類推論
在Raspberry Pi 4設計GUI介面,匯入機器學習模型實現商品結帳應用
本篇文章完整範例程式請由文章最下方附件下載
筆者在使用Teachable Machine時,發現網站除了可以分辨物件的圖像外,也能分辨人臉,故智慧商店才將此功能結合進去。本主題會將焦點會放在臉部的圖像分類,在Teachable Machine收集人臉資料後,匯出人臉的模型檔案後,再使用Tkinter 的圖形化介面設計一套分辨人臉系統。
本文將分成下列幾個步驟來完成此專題
1.在Teachable Machine 收集人臉資料,並可以在網站上即時推論人臉圖像
2.將模型匯入到RPI4,並可執行人臉圖像分類程式
3.設計人臉GUI圖形化介面之程式說明,並執行智慧商店人臉程式
1.在Teachable Machine 收集人臉資料,並可以在網站上即時推論人臉圖像
先在Teachable Machine網頁訓練人臉模型,相關步驟可以參考"使用Google Teachable Machine 來實現Raspberry Pi 4 的影像分類推論",考慮到一般的商店的結帳系統,只要有人即可結帳,並不會去紀錄人名,所以在Teachable Machine 的模型標籤只有兩種情形,有人和無人。

因為只要判別是否有人接近,所以筆者是到網路上收集男性和女性,東方人或西方人的臉孔圖片約莫共120張,直接上傳至"people"的標籤中,讀者也可以程式下載區Store-->face_dataset資料夾中找到圖片,並且全選上傳。另外當初也有想過拍照,但是拍的人數樣本太少,不如直接上網收集人臉圖片,也考慮到不同的膚色、年齡、地方相關的因素。
而收集沒有人臉的圖片則是可以直接設定用Webcam拍照即可。

設定電腦使用的攝影機,本次使用Webcam的是Logi C170

另外,建議可以在電腦外接一個Webcam,收集圖片較為方便。

按下"Train Model" 即可開始訓練模型。

因為在訓練集中放入了相同兩張有帶口罩的人臉,所以即使戴著口罩,推論出來的結果也可以分類得出來是"people"。

無人臉接近則是"no_people"

但如果人臉太遠離鏡頭,則也會被分類到"no_people"
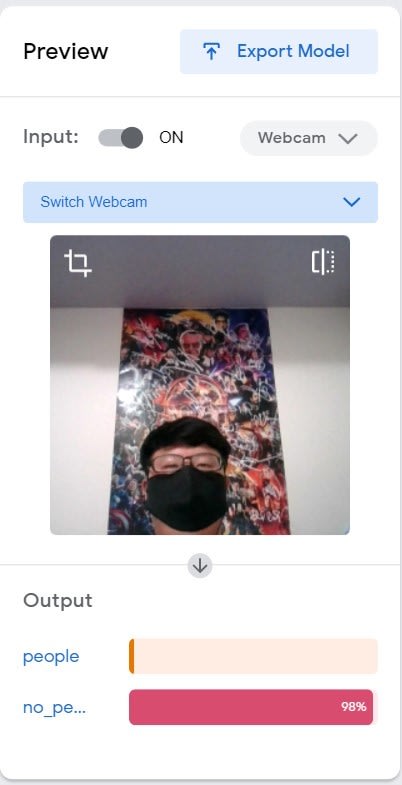
輸出模型

2.將模型匯入到RPI4,並可執行人臉圖像分類程式
點選Tensorflow Lite -->Quantize-->Download my model
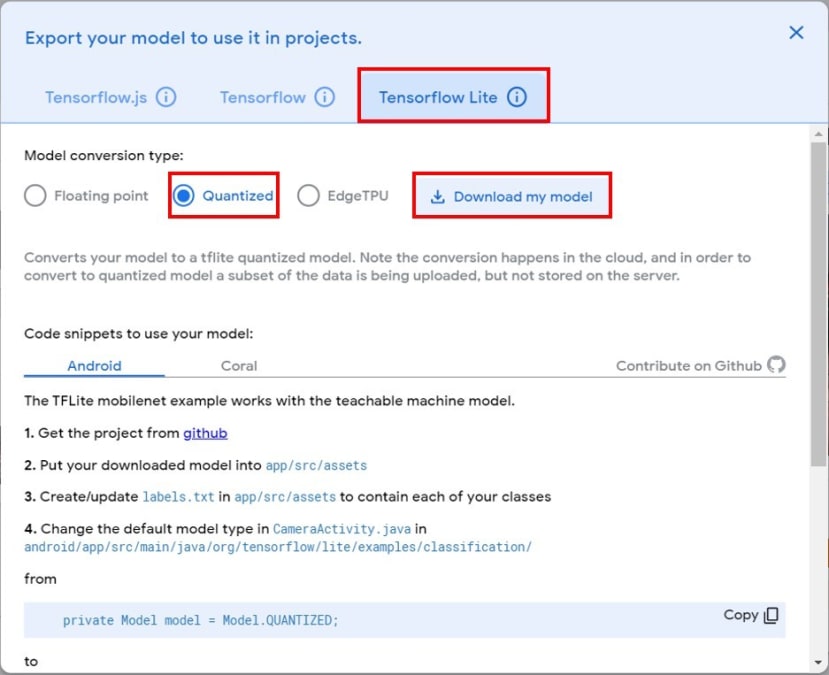
下載得到副檔名[專案名稱]+.txt、.tflite的兩個檔案

請將下載的資料夾解壓縮後,將兩個檔名分別改成"label_face.txt"和"model_face.tflite",並
傳送資料到Rpi4 的"Store"資料夾中。

在"Store"資料夾中有"TM2_tflite_new.py",可以執行程式,並將有無人臉的狀態顯示及預測值顯示在視窗上面。
先移動資料夾位置到Store
$ cd Store/
執行程式
$ python3 TM2_tflite_new.py --model model_face.tflite --label labels_face.txt

在執行程式的視窗中,筆者有將結果顯示在視窗上,"0"為標籤、"people"為預測出人臉的名稱、"0.9921875"為預測值,說明能分辨出人臉類別的預測值為99%。
3.設計人臉GUI圖形化介面之程式說明,並執行智慧商店人臉程式
3-1人臉GUI圖形化介面程式說明
設定視窗大小 300*300像素
self.window.geometry('300x300')
self.window.resizable(False, False)

開啟Webcam攝影機
self.vid_0 = MyVideoCapture(self.video_source_0)
建立人臉尺寸為240*180像素的圖像畫布
self.canvas_face = tkinter.Canvas(window, width = 240, height = 180)
設置畫布尺寸視窗中的於第0行第0列,在grid網格中使用"sticky"參數,是west向左對齊
self.canvas_face.grid(row=0, column=0, sticky="w")
建立具有拍照功能按鈕,並名稱為"Face",排列在第1行第0列
tkinter.Button(window, text="Face", command=self.face).grid(row=1, column=0)
Webcam得到影像後,必須使用PIL套件,才能在Tkinter 畫布中顯示動態影像。
def face(self):
ret_0, frame_0 = self.vid_0.get_frame()
if (ret_0):
Face_class(frame_0)
def update(self):
ret_0, frame_0 = self.vid_0.get_frame()
#調整Webcam影像之畫面大小,需和Tkinter畫布同尺寸
frame_0_small=cv2.resize(frame_0,(240,180))
if ret_0:
self.photo_2 = PIL.ImageTk.PhotoImage(image = PIL.Image.fromarray(frame_0_small))
self.canvas_face.create_image(241,0,image = self.photo_2, anchor="ne")
self.window.after(self.delay, self.update)
Webcam影像畫面相關尺寸大小設定
class MyVideoCapture:
def __init__(self, video_source):
#將原本Webcam影像畫面大小設定為320X240
self.vid = cv2.VideoCapture(video_source)
self.vid.set(cv2.CAP_PROP_FRAME_WIDTH,320)
self.vid.set(cv2.CAP_PROP_FRAME_HEIGHT,240)
if not self.vid.isOpened():
raise ValueError("Unable to open video source", video_source)
# 設定視訊來源的尺寸
self.width = self.vid.get(cv2.CAP_PROP_FRAME_WIDTH)
self.height = self.vid.get(cv2.CAP_PROP_FRAME_HEIGHT)
def get_frame(self):
if self.vid.isOpened():
ret, frame = self.vid.read()
if ret:
# 將影像畫面轉換成RGB格式
return (ret, cv2.cvtColor(frame, cv2.COLOR_BGR2RGB))
else:
return (ret, None)
else:
return (ret, None)
# 釋放影像資源
def __del__(self):
if self.vid.isOpened():
self.vid.release()
做人臉圖像推論,若偵測到人臉時則顯示"歡迎光臨智慧商店",訊息會排序在第2行第0列中顯示出來,並播放歡迎詞音訊,也同時啟動拍照功能。
class Face_class:
def load_labels(self,path):
with open(path, 'r') as f:
return {i: line.strip() for i, line in enumerate(f.readlines())}
def set_input_tensor(self, interpreter, image):
tensor_index = interpreter.get_input_details()[0]['index']
input_tensor = interpreter.tensor(tensor_index)()[0]
input_tensor[:, :] = image
def classify_image(self, interpreter, image, top_k=1):
self.set_input_tensor(interpreter, image)
interpreter.invoke()
output_details = interpreter.get_output_details()[0]
output = np.squeeze(interpreter.get_tensor(output_details['index']))
# If the model is quantized (uint8 data), then dequantize the results
if output_details['dtype'] == np.uint8:
scale, zero_point = output_details['quantization']
output = scale * (output - zero_point)
ordered = np.argpartition(-output, top_k)
return [(i, output[i]) for i in ordered[:top_k]]
def __init__(self,image_src):
labels = self.load_labels('/home/pi/Store/labels_face.txt')
interpreter = Interpreter('/home/pi/Store/model_face.tflite')
interpreter.allocate_tensors()
_, height, width, _ = interpreter.get_input_details()[0]['shape']
image=cv2.resize(image_src,(224,224))
results = self.classify_image(interpreter, image)
label_id, prob = results[0]
if (labels[label_id] == "1 no_people"):
labelExample = tkinter.Label(text="____________________")
labelExample.grid(row=2, column=0)
else :
labelExample = tkinter.Label(text="____________________")
labelExample.grid(row=2, column=0)
labelExample = tkinter.Label(text="歡迎光臨智慧商店")
labelExample.grid(row=2, column=0)
#開啟拍照功能並存在face_collect資料夾中
cv2.imwrite("face_collect/" + "face-" + time.strftime("%d-%m-%Y-%H-%M-%S") + ".jpg", cv2.cvtColor(image_src, cv2.COLOR_RGB2BGR))
#播放歡迎光臨音訊檔
file=r'/home/pi/Store/welcome.mp3'
while (pygame.mixer.music.get_busy()!=1):
track = pygame.mixer.music.load(file)
pygame.mixer.music.play()
#視窗標題為"智慧商店"
App(tkinter.Tk(), "智慧商店")
3-2 執行程式畫面及元件位置
執行Python程式
$python3 tk_cv_face.py
Tkinter排列的元件,分別為畫布(Canvas)在第0行第0列、"Face"按鈕(Button)在第1行第0列、文字標籤(Label)在第2行第0列。偵測到人臉時,除了可以播放音訊檔案外,也同時會開啟拍照功能,其目的在於收集使用者臉孔,可以達成兩種目的,一、可以大致推論出性別或年齡,哪種族群較多人使用。二、可重新訓練模型,雖然google taechable machine在一般的情況下已經可以偵測人臉,但資料集中卻沒有使用者的照片,會使得預測有稍微的偏差,若要符合真實情形,則需要將收集到的人臉照片到google taechable machine再做一次訓練。