人手分類器模型訓練(繁體)
关注文章
 戴夫来自 DesignSpark
戴夫来自 DesignSpark
你觉得这篇文章怎么样? 帮助我们为您提供更好的内容。
戴夫来自 DesignSpark
Thank you! Your feedback has been received.
戴夫来自 DesignSpark
There was a problem submitting your feedback, please try again later.
戴夫来自 DesignSpark
你觉得这篇文章怎么样?
| 作者 | Dan 羅傑瑞 |
| 難度 | 中等 |
| 所需時間 | 2小時 |
在上一篇文章中討論了如何使用Raspberry Pi檢測人手以啟動繼電器開關。在本文中,將介紹分類器模型是如何訓練的以及如何寫相關代碼。在開始之前,要確保我們具有執行模型訓練常式的最低系統要求。在運行培訓計畫時,我們使用了以下硬體規格:
- OS: Windows 10
- GPU: Nvidia GTX840M
- RAM: 12GB
請注意,這些規格僅基於筆記型電腦。最好將訓練程式運行到專用的GPU電腦或伺服器上。但是由於我們的樣本集不大,所以已經足夠了。為了構建環境,我們將Anaconda與Python 3.5結合使用。如果要出於不同目的管理多個環境,則更好。在Anaconda環境中,我們安裝了以下Python庫:
- keras 2.2.4
- matplotlib 2.1.1
- numpy 1.17.4
- opencv-python 3.4.3.18
- tensorflow-gpu 1.11.0
- scikit-image 0.15.0
- scikit-learn 0.19.1
注意系統環境,我們希望並假定您在運行培訓程式之前已安裝了這些庫。建議您首先按照各自網站上的教程進行安裝,避免在按照本文教程時由於庫過時而導致程式無法正常工作的問題。
理論
讓我們先談談一切如何發生。我們訓練了卷積神經網路(ConvNet)模型,該模型可用於將圖像分為兩類:手和其他。但是什麼是CNN模型? CNN模型利用卷積的概念,這是影像處理中的一個概念,其中基於定義的內核大小,對圖像的單元進行特定操作。最常見的是,將卷積用於邊緣檢測。電腦科學家使用卷積來提取序列中的邊緣,並進一步從這些邊緣中提取更多資訊以發現更高級別的特徵。我們的示例中使用了一個簡單的ConvNet模型。ConvNet模型由三層卷積層、完全連接層和一層softmax層組成。三個卷積層如下圖所示提取低、中和高級特徵:
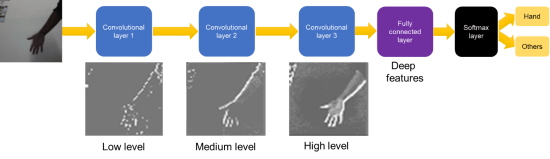
使用手圖像作為輸入,來自圖像的手被第一卷積層緩慢識別。網路看到手的上邊緣,然後看到整個手。第三卷積層的輸出為完全連接的層,以學習可能的深層特徵,例如手的顏色、形狀或大小。有人說,人們可能無法理解深層網路程式,只有電腦才能理解。大多數網路在即使人類無法識別其深層程式情況下也是十分準確的。最後,深層特徵進入softmax層,這層會輸出圖像屬於哪個類別的概率。
但是,這種解釋是對ConvNets如何工作的非常粗略的描述。實際上,參加一門深度學習的課程來瞭解這一點可能會有用得多。但是,我們仍然希望您能夠瞭解ConvNets的基本概念。接著,我們將說明模型訓練過程。
分類器模型訓練分類
步驟1:樣本準備
樣本準備是訓練神經網路模型中最關鍵的步驟之一。 大多數人會遇到訓練問題,例如模型無法收斂。 有時候可能是因為他們缺少樣本、訓練樣本太多、或樣本未正確分類。
首先,我們通過每5秒拍攝一次圖像來用Raspberry Pi收集樣本(可以從圖像的時間戳記檔案名中看到)。為了簡化模型,對於手形課程,我們將手放在相機前面,對於其他類,則什麼也不做。 示例圖像如下所示:

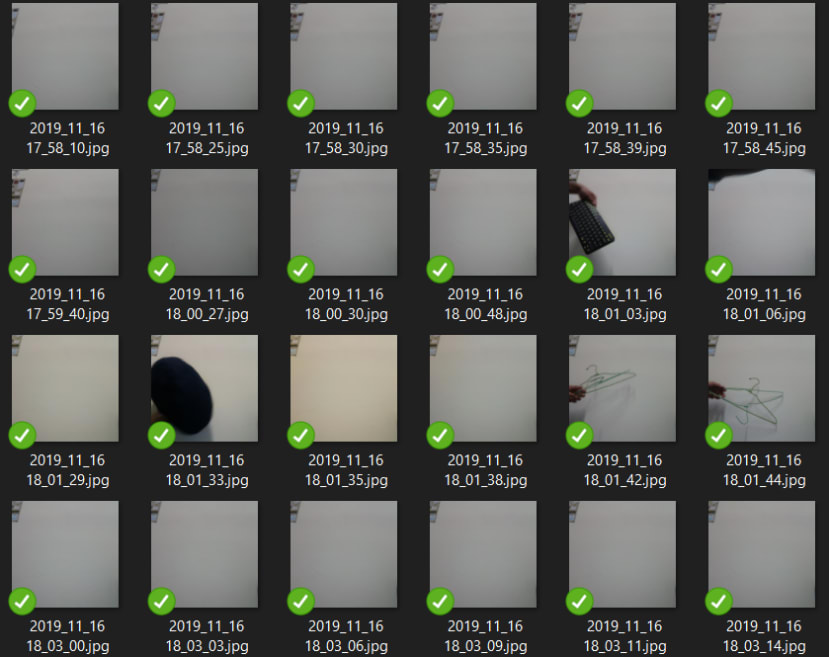
從圖像中可以看出,我們非常清楚地看到了手部類別和其他類別之間的差異。 這也使我們的模型更容易了解手和非手的不同。總共收集了142張手形圖像和135張其他圖像。由於我們的樣本非常簡單,因此這些圖像數量已足夠。 將圖像分別作為手部類別和其他類別放置在資料夾中。
步驟2:模型訓練
在介紹完所有內容之後,讓我們進入模型訓練程式。 訓練程式依賴於兩個我們準備好用於簡化訓練過程的python腳本庫:dataset.py 和 image_classifier.py
dataset.py
腳本dataset.py有助於將訓練圖像準備為與我們將要使用的庫相容的格式。 dataset.py中最重要的功能是load_set。它從圖像目錄中檢索所有影像檔,並根據類別將它們分類為列表。除此之外,影像檔會根據我們的網路結構要求調整為128 x 128大小,這將在後面討論。 load_set的輸出是cv Mat格式的影像檔,它們以相應的標籤保存在列表中,並保存在列表中。 代碼如下:
import cv2
import os
import numpy as np
from sklearn.utils import shuffle
class DataSet(object):
def __init__(self, images, labels):
self._num_examples = images.shape[0]
self._images = images
self._labels = labels
self._epochs_done = 0
self._index_in_epoch = 0
@property
def images(self):
return self._images
@property
def labels(self):
return self._labels
@property
def num_examples(self):
return self._num_examples
@property
def epochs_done(self):
return self._epochs_done
def next_batch(self, batch_size):
start = self._index_in_epoch
self._index_in_epoch += batch_size
if self._index_in_epoch > self._num_examples:
self._epochs_done += 1
start = 0
self._index_in_epoch = batch_size
assert batch_size <= self._num_examples
end = self._index_in_epoch
return self._images[start:end], self._labels[start:end]
#
#載入圖像並將其及其標籤存儲到清單中。
#
def load_set(train_dir, image_size, classes):
images = []
labels = []
print('Now reading samples...')
images = []
labels = []
total_number_of_files = []
for index, class_name in enumerate(classes):
target_folder = train_dir + "/" + class_name
files = os.listdir(target_folder)
# Check if it is a huge folder
if len(files) > 0:
maybe_dir = target_folder + "/" + files[0]
if os.path.isdir(maybe_dir):
files = []
sub_dirs = os.listdir(target_folder)
for sub_folder in sub_dirs:
sub_files = os.listdir(target_folder + "/" + sub_folder)
for file in sub_files:
files.append(target_folder + "/" + sub_folder + "/" + file)
else:
for i, file in enumerate(files):
files[i] = target_folder + "/" + file
number_of_files = len(files)
for file in files:
original_image = cv2.imread(file)
image = cv2.resize(original_image, (image_size, image_size),0,0, cv2.INTER_CUBIC)
images.append(image)
labels.append(index)
print('{} ({}), #: {})'.format(class_name, str(index), number_of_files))
total_number_of_files.append(labels.count(index))
images = np.array(images)
labels = np.array(labels)
return images, labels, total_number_of_files
實際上,函數load_set由另一個稱為read_train_sets的函式呼叫:
#
#載入圖像,隨機排列圖像資料集,並分配每個集的圖像數量
#
def read_train_sets(train_path, class_names, image_size, validation_size):
class DataSets(object):
pass
data_sets = DataSets()
images, labels, number_of_files = load_set(train_path, image_size, class_names)
images, labels = shuffle(images, labels)
if isinstance(validation_size, float):
validation_size = int(validation_size * images.shape[0])
validation_images = images[:validation_size]
validation_labels = labels[:validation_size]
train_images = images[validation_size:]
train_labels = labels[validation_size:]
data_sets.train = DataSet(train_images, train_labels)
data_sets.valid = DataSet(validation_images, validation_labels)
return data_sets
該函數的輸入是圖像路徑、類名、圖像大小和驗證集大小。調用函數時,將執行load_set,重要的子函數是shuffle,可對訓練和驗證集進行隨機排序,以使訓練有效。此外,還設置了驗證大小,將圖像分為訓練集和驗證集。通常,驗證集的最佳大小約為訓練集的10%-25%。
image_classifiers.py
腳本image_classifiers.py包含用於構建ConvNet的代碼。 首先,庫的調用如下:
from keras.models import Sequential
from keras.layers.core import Dense, Activation, Flatten
from keras.layers.convolutional import Conv2D, MaxPooling2D
import tensorflow as tf
import numpy as np
import keras as ks
from skimage.transform import resize腳本中有幾個子功能。 首先是load_classify_image:
def load_classify_image(image, image_size):
num_channels = 3
images = []
# Resizing the image to our desired size and preprocessing will be done exactly as done during training
image = resize(image, (image_size, image_size))
image = image * 255
images.append(image)
images = np.array(images, dtype=np.uint8)
# The input to the network is of shape [None image_size image_size num_channels]. Hence we reshape.
x_input = images.reshape(1, image_size, image_size, num_channels)
return x_input此功能根據對ConvNet的輸入對圖像進行預處理。接下來是load_labels,它只是獲取ConvNet的類別名稱:
def load_labels(filename):
# print("Loaded labels: " + str(filename))
return [line.rstrip() for line in tf.gfile.GFile(filename)]
此外,還包括一個名為ImportGraph()的類別。該函數用於將我們的ConvNet模型存儲到一個易於調用的物件:
class ImportGraph():
def __init__(self, loc):
self.loc = loc
if ".h5" in str(loc):
self.kerasmodel = ks.models.load_model(loc)該類別中最重要的元件是predict_by_cnn函數。 它從我們的ConvNet獲取預測結果並對分類結果進行排序。根據分類概率對結果進行分類。向predict_by_cnn輸入的是圖像資料、概率和字串標籤。特殊的部分是概率輸入。它用於設置預測的閾值。假設圖片的分類概率僅為0.30。您可以使用0.50的閾值來過濾代表該模型並不比猜測更好的此分類。如下所示的predict_by_cnn函數:
def predict_by_cnn(self, data, probability, labels):
number_of_labels = len(labels)
try:
if ".h5" in self.loc:
predictions = self.kerasmodel.predict(data)[0]
# sort predictions
top_k = predictions.argsort()[-number_of_labels:][::-1]
this_class = "na"
this_score = 0
human_strings = []
scores = []
# get results
for node_id in top_k:
human_strings.append(labels[node_id])
scores.append(predictions[node_id])
top_index = scores.index(max(scores))
top_score = scores[top_index]
if top_score >= probability:
this_score = top_score
this_class = human_strings[top_index]
if top_score < probability:
this_class = "unknown"
except Exception as e:
print(e)
return this_class, this_score
最後,我們的ConvNet模型是在createCNNModel中構建的。具體來說,我們的模型是順序模型。 這意味著該模型遵循一定的順序來執行多個功能:
# cnn
def createCNNModel(img_shape, n_classes, n_layers):
# Initialize model
model = Sequential()接下來,我們構建ConvNet的每一層。談到ConvNet結構之前,可以看到我們具有三個卷積層。在這裡,可以看到不同大小的圖層,允許以不同級別(例如低、中和高)提取特徵。代碼如下:
# Layer 1
model.add(Conv2D(64, (5, 5), input_shape=img_shape))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(3, 3), strides=2))
# Layer 2
model.add(Conv2D(64, (5, 5), padding='same'))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(3, 3), strides=2))
# Layer 3
model.add(Conv2D(128, (3, 3), padding='same'))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(3, 3), strides=2))
實際上,您可以嘗試更改這些參數,例如卷積層內核大小。但是,最好先嘗試檢查卷積的工作原理,然後再這樣做。最後,添加平整層以將我們的特徵轉換為單一尺寸,使用整流線性單元(ReLu)從較低級別的特徵啟動深度特徵:
model.add(Flatten())
model.add(Dense(n_layers))
model.add(Activation('relu'))密集層用於設置類別數,而其softmax啟動層則輸出圖像屬於特定類別的概率。
model.add(Dense(n_classes))
model.add(Activation('softmax'))
return model最後,我們進入訓練腳本– cnn_trainer.py。 該腳本一開始會調用必要的庫:
#
# Library and dependencies
#
import matplotlib.pyplot as plt
import keras
import dataset as dataset
import os
from keras.preprocessing.image import ImageDataGenerator
from keras.utils import to_categorical
import image_classifiers as IC接下來,我們設置一些任意的程式常量,例如型號名稱:
#
# Arbitrary constants
#
# Define model name
model_name = "hand_cnn"您可以根據模型將其設置為所需的任何名稱。 除此之外,我們還有訓練目錄或圖像目錄。 目錄內是圖像類資料夾:
# Train directories
train_dir = "hand_samples"接下來是很重要的訓練設置。首先是batch_size,用於設置每個時期使用多少圖像來測試模型。通常將其設置為類數的倍數,例如2 x 8 =16。但這取決於您的GPU。如果GPU足夠好,則可以將其設置得盡可能高:
# Train settings
batch_size = 16 # number of validation and training samples per step現在,step_per_epoch包括每個時期的訓練步驟數。
step_per_epoch = 20 # number of training steps per epoch現在,epochs 是訓練的驗證步驟,也是測試模型的次數。 通常此設置取決於樣本數。根據初始測試,我們設置epochs為25:
epochs = 25 # number of epochs可以在每n個時期保存模型。在這種情況下,保存就是凍結模型。我們已將save_every_epoch函數用作程式的可選功能:
save_every_epoch = 5 # saves model every epochtarget_size是ConvNet模型的輸入大小。其中包括number_of_layers,是完全連接的層的層數。根據圖像的複雜性,可以將其設置為64到4096,其中64是最不複雜的:
target_size = 128 # resizes images to this size
number_of_layers = 128現在,我們設置模型保存設置。在此示例中,我們將其設置為BEST_MODELS,在此程式將根據先前時間之前的訓練和驗證準確性來保存模型。這可以提高效率,因為它可以檢查每個時期之後模型是否有所改善:
# Model saving settings
EVERY_N_EPOCHS = 1
BEST_MODELS = 2
save_model_mode = BEST_MODELS在開始訓練常式之前,我們設置一個隨機種子,以使我們的訓練變得可重現:
# Set seed to make reproducible training results
from numpy.random import seed
seed(1)
from tensorflow import set_random_seed
set_random_seed(2)接下來,我們設置模型保存目錄、獲取類數、設置模型保存目錄,並將類名稱保存在.txt文件中:
# Assigns model save directory
model_dir = "generated_models/" # saves all model (.h5) files to this location
model_save_dir = model_dir + model_name # saves model to the name assigned in train_path
savemodel_filename = model_save_dir + "/" + str(model_name)
# Scan folder and check number of classes
class_names = os.listdir(train_dir)
class_names = [f for f in class_names if ".jpg" not in f]
num_classes = len(class_names)
# Makes model save directory
try:
os.mkdir(model_save_dir)
except:
print("Directory exists!")
pass
# Make labels .txt file
label_filename = savemodel_filename + ".txt"
with open(label_filename, 'w') as txt_file:
for x in range(0,len(class_names)):
txt_file.write(class_names[x] + "\n")
我們終於調用了前一陣子提到的read_train_sets函數:
# Separate training and validation set
data = dataset.read_train_sets(train_path=train_dir,
class_names=class_names,
image_size=target_size,
validation_size=0.2)
這樣做之後,您將能夠看到以下輸出:
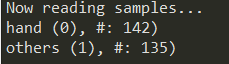
圖像資料已準備就緒,可作為我們訓練程式的輸入:
# Prepare training and validation data
train_data = data.train.images.astype('float32')
valid_data = data.valid.images.astype('float32')
nRows,nCols,nDims = train_data.shape[1:]
input_shape = (nRows, nCols, nDims)
train_labels = data.train.labels
valid_labels = data.valid.labels
train_labels_one_hot = to_categorical(data.train.labels)
valid_labels_one_hot = to_categorical(data.valid.labels)
現在,我們設置模型保存設置。在此示例中,我們將其設置為BEST_MODELS,在此程式將根據先前時間之前的訓練和驗證準確性來保存模型。這可以提高效率,因為它可以檢查每個時期之後模型是否有所改善:
# Set image normalization
datagen = ImageDataGenerator(rescale=1./255)
在這一部分中將調用並編譯該模型:
# Create model and show its structure
# Refer to "image_classifiers.py" for changing the structures
model = IC.createCNNModel((target_size, target_size, 3), num_classes, number_of_layers)
# Compile model
optim = keras.optimizers.Adam(lr=0.00005)
model.compile(optimizer=optim, loss='categorical_crossentropy', metrics=['accuracy'])
print(model.summary())
訓練迴圈從這裡開始:
#
# Option 1:
# Saves model every 10 epochs
#
if save_model_mode == EVERY_N_EPOCHS:
mc = keras.callbacks.ModelCheckpoint(str(savemodel_filename) + "_{epoch:d}.h5",
save_weights_only=False, period=save_every_epoch)
#
# Option 2:
# Save only the best models
#
if save_model_mode == BEST_MODELS:
mc = keras.callbacks.ModelCheckpoint(str(savemodel_filename) + "_{epoch:d}.h5",
save_weights_only=False,
save_best_only=True,
mode='auto')
# Start training
history = model.fit_generator(datagen.flow(train_data, train_labels_one_hot, batch_size=batch_size),
epochs=epochs,
steps_per_epoch=step_per_epoch,
validation_data=datagen.flow(valid_data, valid_labels_one_hot),
validation_steps=batch_size,
verbose=1,
callbacks=[mc])
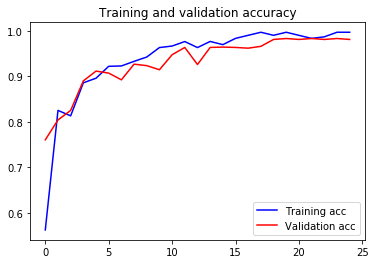
最後,我們的程式將您的訓練摘要保存到.csv文件中。 最重要的是,還顯示了訓練和驗證的準確性以及損失曲線,以供您參考。
# Save training summary to csv
import pandas as pd
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(len(acc))
summary_dict = {'Epoch': epochs, 'TrainAcc': acc, 'ValAcc': val_acc, 'TrainLoss': loss, 'ValLoss': val_loss}
df = pd.DataFrame(data=summary_dict)
df.to_csv(model_save_dir + "/" + model_name + ".csv")
# Plot accuracy curves
plt.plot(epochs, acc, 'b', label='Training acc')
plt.plot(epochs, val_acc, 'r', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'b', label='Training loss')
plt.plot(epochs, val_loss, 'r', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.interactive(False)
plt.show()