人手分类器模型训练
关注文章
 戴夫来自 DesignSpark
戴夫来自 DesignSpark
你觉得这篇文章怎么样? 帮助我们为您提供更好的内容。
戴夫来自 DesignSpark
Thank you! Your feedback has been received.
戴夫来自 DesignSpark
There was a problem submitting your feedback, please try again later.
戴夫来自 DesignSpark
你觉得这篇文章怎么样?
| 作者 | Dan 罗杰瑞 |
| 难度 | 中等 |
| 所需时间 | 2小时 |
在上一篇文章中讨论了如何使用Raspberry Pi检测人手以激活继电器开关。在本文中,将介绍分类器模型是如何训练的以及如何写相关代码。在开始之前,要确保我们具有执行模型训练例程的最低系统要求。在运行培训计划时,我们使用了以下硬件规格:
- OS: Windows 10
- GPU: Nvidia GTX840M
- RAM: 12GB
请注意,这些规格仅基于笔记本电脑。最好将训练程序运行到专用的GPU计算机或服务器上。但是由于我们的样本集不大,所以已经足够了。为了构建环境,我们将Anaconda与Python 3.5结合使用。如果要出于不同目的管理多个环境,则更好。在Anaconda环境中,我们安装了以下Python库:
- keras 2.2.4
- matplotlib 2.1.1
- numpy 1.17.4
- opencv-python 3.4.3.18
- tensorflow-gpu 1.11.0
- scikit-image 0.15.0
- scikit-learn 0.19.1
注意系统环境,我们希望并假定您在运行培训程序之前已安装了这些库。建议您首先按照各自网站上的教程进行安装,避免在按照本文教程时由于库过时而导致程序无法正常工作的问题。
理论
让我们先谈谈一切如何发生。我们训练了卷积神经网络(ConvNet)模型,该模型可用于将图像分为两类:手和其他。但是什么是CNN模型? CNN模型利用卷积的概念,这是图像处理中的一个概念,其中基于定义的内核大小,对图像的单元进行特定操作。最常见的是,将卷积用于边缘检测。计算机科学家使用卷积来提取序列中的边缘,并进一步从这些边缘中提取更多信息以发现更高级别的特征。我们的示例中使用了一个简单的ConvNet模型。ConvNet模型由三层卷积层、完全连接层和一层softmax层组成。三个卷积层如下图所示提取低、中和高级特征:
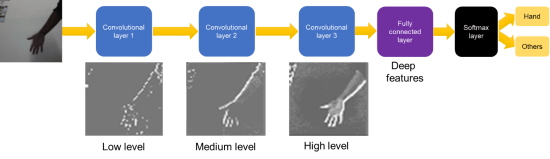
使用手图像作为输入,来自图像的手被第一卷积层缓慢识别。网络看到手的上边缘,然后看到整个手。第三卷积层的输出为完全连接的层,以学习可能的深层特征,例如手的颜色、形状或大小。有人说,人们可能无法理解深层网络程序,只有计算机才能理解。大多数网络在即使人类无法识别其深层程序情况下也是十分准确的。最后,深层特征进入softmax层,这层会输出图像属于哪个类别的概率。
但是,这种解释是对ConvNets如何工作的非常粗略的描述。实际上,参加一门深度学习的课程来了解这一点可能会有用得多。但是,我们仍然希望您能够了解ConvNets的基本概念。接着,我们将说明模型训练过程。
分类器模型训练
步骤1:样本准备
样本准备是训练神经网络模型中最关键的步骤之一。 大多数人会遇到训练问题,例如模型无法收敛。 有时候可能是因为他们缺少样本、训练样本太多、或样本未正确分类。
首先,我们通过每5秒拍摄一次图像来用Raspberry Pi收集样本(可以从图像的时间戳文件名中看到)。为了简化模型,对于手形课程,我们将手放在相机前面,对于其他类,则什么也不做。 示例图像如下所示:

从图像中可以看出,我们非常清楚地看到了手部类别和其他类别之间的差异。 这也使我们的模型更容易了解手和非手的不同。总共收集了142张手形图像和135张其他图像。由于我们的样本非常简单,因此这些图像数量已足够。 将图像分别作为手部类别和其他类别放置在文件夹中。
步骤2:模型训练
在介绍完所有内容之后,让我们进入模型训练程序。 训练程序依赖于两个我们准备好用于简化训练过程的python脚本库:dataset.py 和 image_classifier.py
dataset.py
脚本dataset.py有助于将训练图像准备为与我们将要使用的库兼容的格式。 dataset.py中最重要的功能是load_set。它从图像目录中检索所有图像文件,并根据类别将它们分类为列表。除此之外,图像文件会根据我们的网络结构要求调整为128 x 128大小,这将在后面讨论。 load_set的输出是cv Mat格式的图像文件,它们以相应的标签保存在列表中,并保存在列表中。 代码如下:
import cv2
import os
import numpy as np
from sklearn.utils import shuffle
class DataSet(object):
def __init__(self, images, labels):
self._num_examples = images.shape[0]
self._images = images
self._labels = labels
self._epochs_done = 0
self._index_in_epoch = 0
@property
def images(self):
return self._images
@property
def labels(self):
return self._labels
@property
def num_examples(self):
return self._num_examples
@property
def epochs_done(self):
return self._epochs_done
def next_batch(self, batch_size):
start = self._index_in_epoch
self._index_in_epoch += batch_size
if self._index_in_epoch > self._num_examples:
self._epochs_done += 1
start = 0
self._index_in_epoch = batch_size
assert batch_size <= self._num_examples
end = self._index_in_epoch
return self._images[start:end], self._labels[start:end]
#
#加载图像并将其及其标签存储到列表中。
#
def load_set(train_dir, image_size, classes):
images = []
labels = []
print('Now reading samples...')
images = []
labels = []
total_number_of_files = []
for index, class_name in enumerate(classes):
target_folder = train_dir + "/" + class_name
files = os.listdir(target_folder)
# Check if it is a huge folder
if len(files) > 0:
maybe_dir = target_folder + "/" + files[0]
if os.path.isdir(maybe_dir):
files = []
sub_dirs = os.listdir(target_folder)
for sub_folder in sub_dirs:
sub_files = os.listdir(target_folder + "/" + sub_folder)
for file in sub_files:
files.append(target_folder + "/" + sub_folder + "/" + file)
else:
for i, file in enumerate(files):
files[i] = target_folder + "/" + file
number_of_files = len(files)
for file in files:
original_image = cv2.imread(file)
image = cv2.resize(original_image, (image_size, image_size),0,0, cv2.INTER_CUBIC)
images.append(image)
labels.append(index)
print('{} ({}), #: {})'.format(class_name, str(index), number_of_files))
total_number_of_files.append(labels.count(index))
images = np.array(images)
labels = np.array(labels)
return images, labels, total_number_of_files
实际上,函数load_set由另一个称为read_train_sets的函数调用:
#
#加载图像,随机排列图像数据集,并分配每个集的图像数量
#
def read_train_sets(train_path, class_names, image_size, validation_size):
class DataSets(object):
pass
data_sets = DataSets()
images, labels, number_of_files = load_set(train_path, image_size, class_names)
images, labels = shuffle(images, labels)
if isinstance(validation_size, float):
validation_size = int(validation_size * images.shape[0])
validation_images = images[:validation_size]
validation_labels = labels[:validation_size]
train_images = images[validation_size:]
train_labels = labels[validation_size:]
data_sets.train = DataSet(train_images, train_labels)
data_sets.valid = DataSet(validation_images, validation_labels)
return data_sets
该函数的输入是图像路径、类名、图像大小和验证集大小。调用函数时,将执行load_set,重要的子函数是shuffle,可对训练和验证集进行随机排序,以使训练有效。此外,还设置了验证大小,将图像分为训练集和验证集。通常,验证集的最佳大小约为训练集的10%-25%。
image_classifiers.py
脚本image_classifiers.py包含用于构建ConvNet的代码。 首先,库的调用如下:
from keras.models import Sequential
from keras.layers.core import Dense, Activation, Flatten
from keras.layers.convolutional import Conv2D, MaxPooling2D
import tensorflow as tf
import numpy as np
import keras as ks
from skimage.transform import resize脚本中有几个子功能。 首先是load_classify_image:
def load_classify_image(image, image_size):
num_channels = 3
images = []
# Resizing the image to our desired size and preprocessing will be done exactly as done during training
image = resize(image, (image_size, image_size))
image = image * 255
images.append(image)
images = np.array(images, dtype=np.uint8)
# The input to the network is of shape [None image_size image_size num_channels]. Hence we reshape.
x_input = images.reshape(1, image_size, image_size, num_channels)
return x_input此功能根据对ConvNet的输入对图像进行预处理。接下来是load_labels,它只是获取ConvNet的类別名称:
def load_labels(filename):
# print("Loaded labels: " + str(filename))
return [line.rstrip() for line in tf.gfile.GFile(filename)]
此外,还包括一个名为ImportGraph()的类別。该函数用于将我们的ConvNet模型存储到一个易于调用的对象:
class ImportGraph():
def __init__(self, loc):
self.loc = loc
if ".h5" in str(loc):
self.kerasmodel = ks.models.load_model(loc)该类別中最重要的组件是predict_by_cnn函数。 它从我们的ConvNet获取预测结果并对分类结果进行排序。根据分类概率对结果进行分类。向predict_by_cnn输入的是图像数据、概率和字符串标签。特殊的部分是概率输入。它用于设置预测的阈值。假设图片的分类概率仅为0.30。您可以使用0.50的阈值来过滤代表该模型并不比猜测更好的此分类。如下所示的predict_by_cnn函数:
def predict_by_cnn(self, data, probability, labels):
number_of_labels = len(labels)
try:
if ".h5" in self.loc:
predictions = self.kerasmodel.predict(data)[0]
# sort predictions
top_k = predictions.argsort()[-number_of_labels:][::-1]
this_class = "na"
this_score = 0
human_strings = []
scores = []
# get results
for node_id in top_k:
human_strings.append(labels[node_id])
scores.append(predictions[node_id])
top_index = scores.index(max(scores))
top_score = scores[top_index]
if top_score >= probability:
this_score = top_score
this_class = human_strings[top_index]
if top_score < probability:
this_class = "unknown"
except Exception as e:
print(e)
return this_class, this_score
最后,我们的ConvNet模型是在createCNNModel中构建的。具体来说,我们的模型是顺序模型。 这意味着该模型遵循一定的顺序来执行多个功能:
# cnn
def createCNNModel(img_shape, n_classes, n_layers):
# Initialize model
model = Sequential()接下来,我们构建ConvNet的每一层。谈到ConvNet结构之前,可以看到我们具有三个卷积层。在这里,可以看到不同大小的图层,允许以不同级别(例如低、中和高)提取特征。代码如下:
# Layer 1
model.add(Conv2D(64, (5, 5), input_shape=img_shape))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(3, 3), strides=2))
# Layer 2
model.add(Conv2D(64, (5, 5), padding='same'))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(3, 3), strides=2))
# Layer 3
model.add(Conv2D(128, (3, 3), padding='same'))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(3, 3), strides=2))
实际上,您可以尝试更改这些参数,例如卷积层内核大小。但是,最好先尝试检查卷积的工作原理,然后再这样做。最后,添加平整层以将我们的特征转换为单一尺寸,使用整流线性单元(ReLu)从较低级别的特征激活深度特征:
model.add(Flatten())
model.add(Dense(n_layers))
model.add(Activation('relu'))密集层用于设置类别数,而其softmax激活层则输出图像属于特定类别的概率。
model.add(Dense(n_classes))
model.add(Activation('softmax'))
return model最后,我们进入训练脚本– cnn_trainer.py。 该脚本一开始会调用必要的库:
#
# Library and dependencies
#
import matplotlib.pyplot as plt
import keras
import dataset as dataset
import os
from keras.preprocessing.image import ImageDataGenerator
from keras.utils import to_categorical
import image_classifiers as IC接下来,我们设置一些任意的程序常量,例如型号名称:
#
# Arbitrary constants
#
# Define model name
model_name = "hand_cnn"您可以根据模型将其设置为所需的任何名称。 除此之外,我们还有训练目录或图像目录。 目录内是图像类文件夹:
# Train directories
train_dir = "hand_samples"接下来是很重要的训练设置。首先是batch_size,用于设置每个时期使用多少图像来测试模型。通常将其设置为类数的倍数,例如2 x 8 =16。但这取决于您的GPU。如果GPU足够好,则可以将其设置得尽可能高:
# Train settings
batch_size = 16 # number of validation and training samples per step现在,step_per_epoch包括每个时期的训练步骤数。
step_per_epoch = 20 # number of training steps per epoch现在,epochs 是训练的验证步骤,也是测试模型的次数。 通常此设置取决于样本数。根据初始测试,我们设置epochs为25:
epochs = 25 # number of epochs可以在每n个时期保存模型。在这种情况下,保存就是冻结模型。我们已将save_every_epoch函数用作程序的可选功能:
save_every_epoch = 5 # saves model every epochtarget_size是ConvNet模型的输入大小。其中包括number_of_layers,是完全连接的层的层数。根据图像的复杂性,可以将其设置为64到4096,其中64是最不复杂的:
target_size = 128 # resizes images to this size
number_of_layers = 128现在,我们设置模型保存设置。在此示例中,我们将其设置为BEST_MODELS,在此程序将根据先前时间之前的训练和验证准确性来保存模型。这可以提高效率,因为它可以检查每个时期之后模型是否有所改善:
# Model saving settings
EVERY_N_EPOCHS = 1
BEST_MODELS = 2
save_model_mode = BEST_MODELS在开始训练例程之前,我们设置一个随机种子,以使我们的训练变得可重现:
# Set seed to make reproducible training results
from numpy.random import seed
seed(1)
from tensorflow import set_random_seed
set_random_seed(2)接下来,我们设置模型保存目录、获取类数、设置模型保存目录,并将类名称保存在.txt文件中:
# Assigns model save directory
model_dir = "generated_models/" # saves all model (.h5) files to this location
model_save_dir = model_dir + model_name # saves model to the name assigned in train_path
savemodel_filename = model_save_dir + "/" + str(model_name)
# Scan folder and check number of classes
class_names = os.listdir(train_dir)
class_names = [f for f in class_names if ".jpg" not in f]
num_classes = len(class_names)
# Makes model save directory
try:
os.mkdir(model_save_dir)
except:
print("Directory exists!")
pass
# Make labels .txt file
label_filename = savemodel_filename + ".txt"
with open(label_filename, 'w') as txt_file:
for x in range(0,len(class_names)):
txt_file.write(class_names[x] + "\n")
我们终于调用了前一阵子提到的read_train_sets函数:
# Separate training and validation set
data = dataset.read_train_sets(train_path=train_dir,
class_names=class_names,
image_size=target_size,
validation_size=0.2)
这样做之后,您将能够看到以下输出:
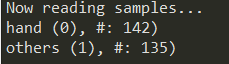
图像数据已准备就绪,可作为我们训练程序的输入:
# Prepare training and validation data
train_data = data.train.images.astype('float32')
valid_data = data.valid.images.astype('float32')
nRows,nCols,nDims = train_data.shape[1:]
input_shape = (nRows, nCols, nDims)
train_labels = data.train.labels
valid_labels = data.valid.labels
train_labels_one_hot = to_categorical(data.train.labels)
valid_labels_one_hot = to_categorical(data.valid.labels)
现在,我们设置模型保存设置。在此示例中,我们将其设置为BEST_MODELS,在此程序将根据先前时间之前的训练和验证准确性来保存模型。这可以提高效率,因为它可以检查每个时期之后模型是否有所改善:
# Set image normalization
datagen = ImageDataGenerator(rescale=1./255)
在这一部分中将调用并编译该模型:
# Create model and show its structure
# Refer to "image_classifiers.py" for changing the structures
model = IC.createCNNModel((target_size, target_size, 3), num_classes, number_of_layers)
# Compile model
optim = keras.optimizers.Adam(lr=0.00005)
model.compile(optimizer=optim, loss='categorical_crossentropy', metrics=['accuracy'])
print(model.summary())
训练循环从这里开始:
#
# Option 1:
# Saves model every 10 epochs
#
if save_model_mode == EVERY_N_EPOCHS:
mc = keras.callbacks.ModelCheckpoint(str(savemodel_filename) + "_{epoch:d}.h5",
save_weights_only=False, period=save_every_epoch)
#
# Option 2:
# Save only the best models
#
if save_model_mode == BEST_MODELS:
mc = keras.callbacks.ModelCheckpoint(str(savemodel_filename) + "_{epoch:d}.h5",
save_weights_only=False,
save_best_only=True,
mode='auto')
# Start training
history = model.fit_generator(datagen.flow(train_data, train_labels_one_hot, batch_size=batch_size),
epochs=epochs,
steps_per_epoch=step_per_epoch,
validation_data=datagen.flow(valid_data, valid_labels_one_hot),
validation_steps=batch_size,
verbose=1,
callbacks=[mc])
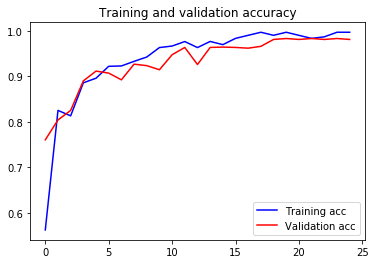
最后,我们的程序将您的训练摘要保存到.csv文件中。 最重要的是,还显示了训练和验证的准确性以及损失曲线,以供您参考。
# Save training summary to csv
import pandas as pd
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(len(acc))
summary_dict = {'Epoch': epochs, 'TrainAcc': acc, 'ValAcc': val_acc, 'TrainLoss': loss, 'ValLoss': val_loss}
df = pd.DataFrame(data=summary_dict)
df.to_csv(model_save_dir + "/" + model_name + ".csv")
# Plot accuracy curves
plt.plot(epochs, acc, 'b', label='Training acc')
plt.plot(epochs, val_acc, 'r', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'b', label='Training loss')
plt.plot(epochs, val_loss, 'r', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.interactive(False)
plt.show()