Apprehending Machine Vision
Follow article
 Dave from DesignSpark
Dave from DesignSpark
How do you feel about this article? Help us to provide better content for you.
Dave from DesignSpark
Thank you! Your feedback has been received.
Dave from DesignSpark
There was a problem submitting your feedback, please try again later.
Dave from DesignSpark
What do you think of this article?
The 1990’s were something of a golden age for discrete digital signal processors (DSPs) in high-end applications and they made my early engineering career a fascinating voyage of discovery once we crossed paths.
The Early Days of DSP
Of course, the ‘Cool Britannia’ decade was nowhere near the dawn of DSP: that had been around since the late 1960’s when commercially made digital computers first became available. However, the eye-watering cost of these machines meant that development only went into areas where money was no object: Defence (particularly radar and sonar), Oil exploration (pretty good return on investment!), Space exploration (deep taxpayer pockets) and medical imaging, where untold numbers of lives could be saved.
Telecomms giants were also beginning to show an interest in digital data transmission at this time and their research labs began creating what became some of the bedrock algorithms of DSP.
At AT&T's Bell Labs, Manfred Schroeder and Binshu Atal developed Adaptive Predictive Coding (APC) in 1967; demonstrating acceptable audio off a tiny 4.8kbps bit stream. Atal went on to develop Linear Predictive Coding (LPC) for speech compression, which (Nerd Nostalgia Nugget [or N3] warning) was used by Texas instruments in their first DSP based toy, 'Speak and Spell', released in 1978.
At the same time in Japan, Fumitada Imakura at Nagoya University and Shuzo Saito at NTT were developing a similar algorithm called partial correlation (PARCOR) coding. What these algorithms, and indeed most DSP algorithms, have in common at the hardware level is a heavy reliance on multiply then add (aka multiply/accumulate or MAC) operations.
With the integrated circuit technology improvements of the 1980’s came relatively low-cost, commercial DSP chips able to efficiently crank out MAC operations, starting with the AT&T DSP-1 chip in 1979.

The AT&T DSP-1 chip
This was followed by NEC's µPD7720, a true fixed-point DSP with a 16×16-bit multiplier and two 16-bit accumulators, commercially available (with dev tools) in 1981 for voiceband applications and was a huge hit in Japan and Europe.
Motorola's breakthrough device in the mid 80's was the DSP56000, with a 24-bit hardware multiplier and two 48-bit accumulators, extendable by another 8 bits with a pair of extension registers. This was ideal for high-precision audio and the DSP56000 became a de-facto king of high-end audio systems.
My Introduction to DSP
When DSP and I finally met in the mid 90’s, the Texas Instruments TMS320C40 (or just C40 to its mates), was well established; with a number of small manufacturers producing commercial, off-the-shelf (or COTS) DSP boards for standard bus interfaces like VME and the new (at the time) PCI bus.
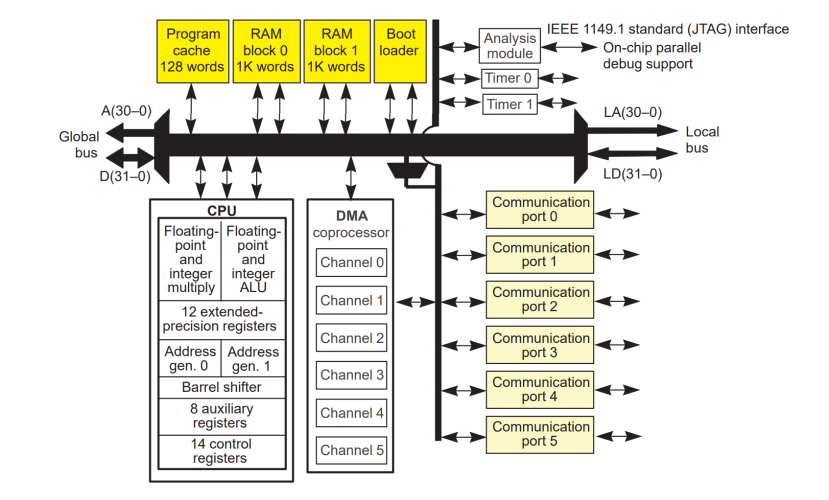
Block diagram of the Texas Instruments TMS320C40
I have fond memories of this 32-bit, floating-point device: it was relatively easy to program in C and was supported by a large number of optimised libraries. One of its coolest features were the six comm ports, which massively extended the I/O bandwidth (by a combined 384 Mbytes/s) over the paltry transfer rates achievable on VMEbus [80 MB/s on VME64] or even PCI [133 MB/s], and allowed the formation of parallel processing grids, much like the earlier INMOS Transputer. This meant that the C40 processing power could be scaled to match a large number of real-time DSP problems; including, of course, machine vision.
But the C40 was still a fairly slow device, topping out with a 25ns cycle time at 80MHz (most ran at 40 or 50MHz) meaning you could end up with a pretty large processor array for some problems, assuming that cycle time wasn’t simply too long for your application. So there were also devices aimed squarely at processing video streams, like TI’s TMS320C80. However, my memories of working with that device are somewhat less rose-tinted.
The C80 was marketed as an MVP (multimedia video processor) with a 32-bit IEEE-754 floating-point RISC "master processor" (or MP) and four 32-bit fixed-point "parallel processor" DSPs (or PP’s). On paper, it was a performance Kaiju, but in reality, it was a very different kind of "strange beast". It ended up being pretty expensive and boy did it get hot – power consumption was a major user gripe. The PP’s were difficult to program and the available dev tools really didn’t really ease that problem. Then there was the deeply flawed Transfer Controller that handled all IO on and off the device and was enough to induce PTSD in developers. When asked about it, survivors of C80 projects often fall into a thousand-yard stare and whisper, “You don’t know, man. You weren’t there…”
It just goes to show, even amazing companies like TI can have an off-product. They weren’t alone: Analog Devices introduced the SHARC DSP family in the mid 90’s, which also had six ‘link ports’ for inter-DSP communications and was another fun DSP to work with. But even Analog Devices had something of a Vista moment with the release of the 100MHz Hammerhead device. From a user perspective, it never really overcame its teething problems and many people opted to simply jump to the TigerSHARC for higher performance when it arrived.
Commonalities
Anyway, talk of the SHARC brings me nicely to some common features across DSP chips. SHARC is an acronym of Super Harvard Architecture Computer. For the cost of a fair amount of increased design complexity, the Harvard architecture (which is common across dedicated DSP devices) allows simultaneous access to separate program and data memories across separate busses. Unlike the general purpose Von Neumann architecture, this means the CPU can load both the program instruction and the data it will operate on, at the same time; facilitating the gold standard of DSP: the single cycle MAC operation.
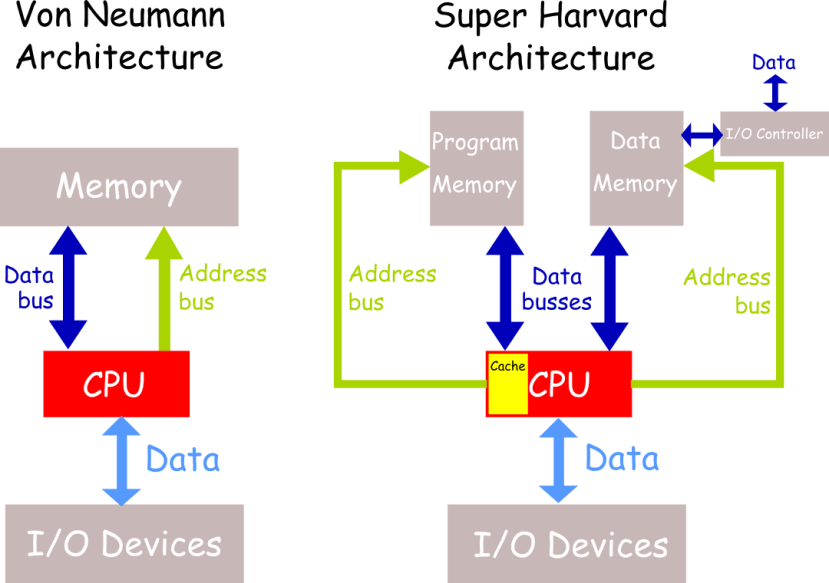
Comparison of the Von Neumann and Super Harvard computer architectures
The Super Harvard Architecture adds an instruction cache and an I/O controller for DMA transfers into the data memory, which will usually be dual-port to facilitate circular buffering.
The other key feature of this architecture, for real-time DSP, is deterministic operation: any given operation will always take the same number of machine cycles to complete. That’s why one of the common DSP benchmarks for devices is the number of cycles to complete a fixed DSP algorithm like the 1024-point FFT. The addition of other features, like SIMD instructions (where some instructions can operate on multiple data elements [that have been packed into wide ALU registers] simultaneously) massively improves vector processing performance on large arrays, like image frames.
With all this goodness packed into single chips, the DSPs were the kings of high-end signal processing. In the video arena, this included applications like optical inspection of finished goods and even fruit on production lines, aperture synthesis and image fusion.
Clouds on the Horizon
The first cracks in this rosy picture began to appear when general-purpose processors started to include SIMD instructions to improve their multimedia abilities.
Motorola's AltiVec instruction set on the PowerPC changed the landscape and had a lot of DSP users jumping ship: as a general-purpose device, it was easy to program and had a lot of software support, including full real-time operating systems, from many sources. It was also fast. When your processor is clocking a couple of orders of magnitude faster than the devices you currently use on your application, determinism is not necessarily the priority it once was.
But what really dethroned DSPs was the introduction in January 2001 of the Xilinx Virtex-II FPGA family. By July, Xilinx announced that it had already shipped a million dollars worth of these FPGAs. These FPGAs came with embedded functional blocks that included a PowerPC 405 Processor Block, up to 444 separate 18 x 18-bit multiplier blocks (in the largest device); the same number of 18kb dual-port SelectRAM+ memory blocks; up to 20 separate 3.125 Gb/s Full-Duplex RocketIOTM Serial Transceivers plus a host of other supporting hardware. If you were a DSP engineer reading this in 2001, you realised that the first FPGA to incorporate hardware multipliers could already vastly outperform every single-chip DSP that existed at the time. Altera followed up with first-generation Stratix FPGAs that had 36×36-bit hardware multipliers in 2002.
While DSPs still find space in a wide variety of applications today, that was the end of their heyday as the first choice for high-end signal processing.
Machine Vision
“So, what’s this all got to do with machine vision?” I hear you ask. Well, apart from the fact I found all this reminiscing enjoyable, it is useful to know something of the past if you want to understand the present.
Traditional DSP uses algorithms to change data from the form in which we collected it, to the form we want, through step-by-step procedures. In most cases, convolution is the underlying mathematical heart of the algorithm, where we are combining two signals to form a third. We use coefficients to form the 'signal' we apply to the input signal in order to get our desired output. For example, recursive (IIR) filters apply recursion coefficients to the input samples and feature detection in images uses correlation (mathematically, a form of convolution) with threshold coefficients. The judicious selection of these parameters is essential and often more important than the algorithm itself.
In many ways, the current trend in the use of neural networks for image processing is simply an extreme example of this, where the algorithms are actually pretty simple but use a huge set of highly optimised parameters. Unlike traditional methods, which use a predetermined mathematical strategy to solve the problem, neural nets use trial and error; essentially a "this works better than that" methodology in the training cycles to hone the coefficients for the final application.
It is also worth remembering that images are just a representation of how a parameter varies over a surface. We tend to think of images as being light intensity variations across a two-dimensional plane but they could equally be variations in the radio waves from a black hole, sound in sonar returns, reflections in ground-penetrating radar or even variations in ground movement in an earthquake. Just as knowledge is only power when it is used, images are only useful when interpreted for their contextual meaning. Traditionally, DSP would be used to convert these exotic variations into conventional images that a human expert could study but the accelerating trend is for them to be used directly by neural networks to autonomously make determinations and predictions.
It is this autonomy that separates ‘machine vision’ from simple ‘image processing’. Extracting information from an image on an automated basis to guide machines in the execution of their function has been done industrially and militarily for decades; neural networks have simply opened new application vistas and techniques for machine vision.
Whether the image is examined by eye or AI, the most common motive is to find out if an object or condition is present. That could be disease in a patient, oil or gas in a rock formation or a defect in a manufactured product. Usually, this involves comparing our acquired data against some threshold values. If the threshold is exceeded, the target (what we are looking for) is considered to be present. AI uses systematised statistical analysis to determine the likelihood that the detected feature is what we're looking for, given what is known about the classification of the target and what is known about the environment. This is where Bayesian analysis can be particularly helpful.
Applications
The applications for machine vision are probably only limited by the imaginations of tech visionaries, but they will all feature some form of pre-processing to remove noise and otherwise prep the image for segmentation and feature extraction. Beyond that, there are essentially two types of imaging methods: 2D and 3D.
2D imaging techniques include:
Visual spectrum (light) imaging. The most common technique in machine vision, using optical cameras that capture images that can then be used in applications that include operations like gauging (measuring object dimensions), pattern recognition or template matching, edge detection, thresholding and colour analysis. These techniques facilitate everything from process control to part assembly and part inspection for quality control and sorting.
Multispectral imaging. Measures light in a small number (typically from 3 to 15) of spectral bands. Some of the bands will be beyond visual range, such as ultraviolet or infrared to gather information not detectable in the visual range. If a visual image is being constructed, these outside bands will be recoloured into the visual range for assessment.

Multispectral imaging uses multiple wide spectral bands
As every material has an identifiable infrared signature, multispectral imaging was (not surprisingly) first developed to aid military target tracking. Mid-wave infrared (MWIR) and long-wave infrared (LWIR) - AKA heat - is inherent to every object, so how bright it looks to a thermal imager is down to the emissivity of the material it is made of and how hot it is. Using multiple bands mitigates for atmospheric conditions (like fog) making sure the target is not lost.
Emissivity also aids in land mine detection, as disturbed soil has increased emissivity in the 8.5 to 9.5µm wavelength range.
Landsat 8 uses 11 bands, including near-infrared and SWIR, to enhance costal and vegetation imaging. These techniques are also used in artwork and ancient document investigations to uncover forgeries or read long-faded text.
Hyperspectral imaging. Uses a large number (sometimes into the hundreds) of very narrow bands for imaging.

Hyperspectral imaging uses many very narrow spectral bands
Essentially the sensors collect information as a set of frames, each of which represent a narrow wavelength range. The frames are combined to form a three-dimensional (x,y,λ) hyperspectral data cube, where x and y are two spatial dimensions for the image, and λ is the spectral dimension: i.e. the range of wavelengths present for each pixel, as a spectrometer collects wavelength information as well as relative intensity information for the different wavelengths detected.
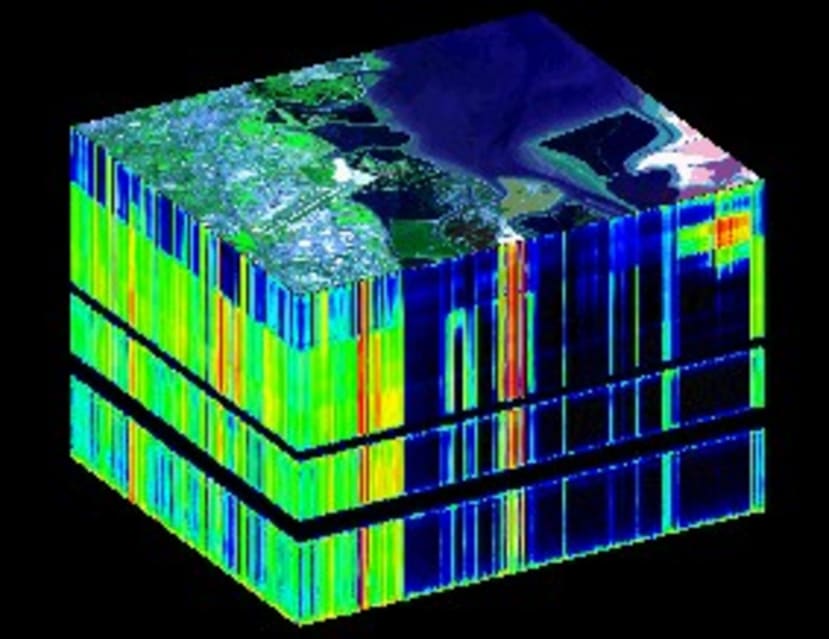
Example of a hyperspectral cube
Hyperspectral imaging is used in diverse places from geology - the ability to narrowly identify minerals makes it ideal for the mining and oil industries – to historical manuscript research, such as the imaging of the Archimedes Palimpsest.
3D Imaging Techniques
These are generally looking to add depth or range of information and include:
Laser triangulation. Operates by projecting a laser beam on the target under measurement and a part of this beam is reflected via focusing optics onto a detector.
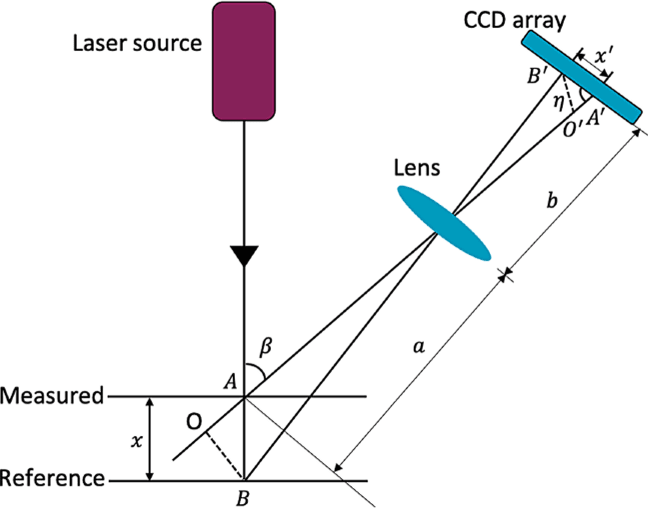
Laser triangulation
As the target shifts up or down from the reference distance the angle of incidence changes, so the beam moves on the detector providing spot height information. Moving across a surface allows you to map height changes.
Time of flight. Measures the time it takes for a laser photon to travel from a source to an object and back to the sensor. With that and some knowledge of wave propagation, you can determine the distance of the object from the source. This forms the basis of Lidar systems.
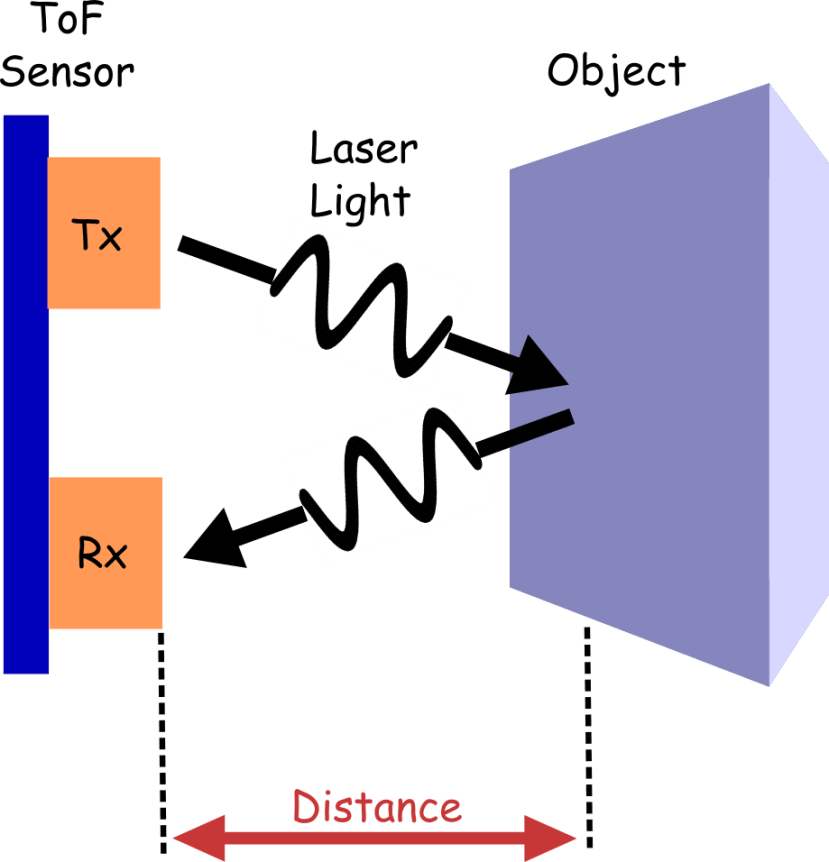
Time-Of-Flight sensor operation
This tech is used in a wide range of applications from enhancing the quality of photos from smartphone cameras to robotic assembly lines (guiding arms for part manipulation) and driver assist to mobile robot or vehicle navigation using SLAM (simultaneous localization and mapping) and even building occupancy measurement.
Structured Light. An image composed of a known structured pattern, like a line or point grid, is projected on the object. The pattern is observed by a camera as it is projected onto the figure and will appear deformed due to the geometry of the object. Analysing the deformation of the pattern makes it possible to reconstruct a 3d model of the surface.
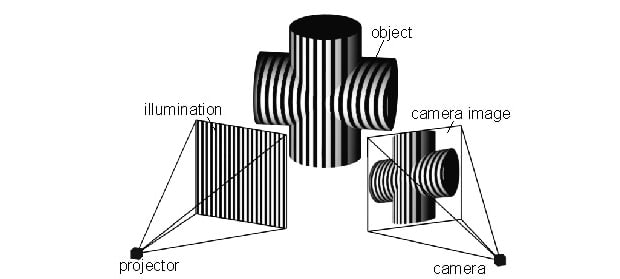
Structured light methodology
A great example is Apple’s Face ID, where a dot projector flashes thousands of infrared dots out which are read by an infrared camera. The dot readings are used to build a depth map as more distant dots will appear smaller and closer dots will appear larger.

Face recognition with structured light
Your old Xbox Kinect also used structured light compute a depth map and then infer player body position using machine learning.
Stereoscopic Imaging. Most stereoscopic imaging platforms use two cameras at different angles, delivering a slightly different image to each camera. The difference is called parallax. Image processing software identifies common features in both images - some algorithms attempt to match each pixel with its corresponding pixel from the other image - and extracts distance information through triangulation.
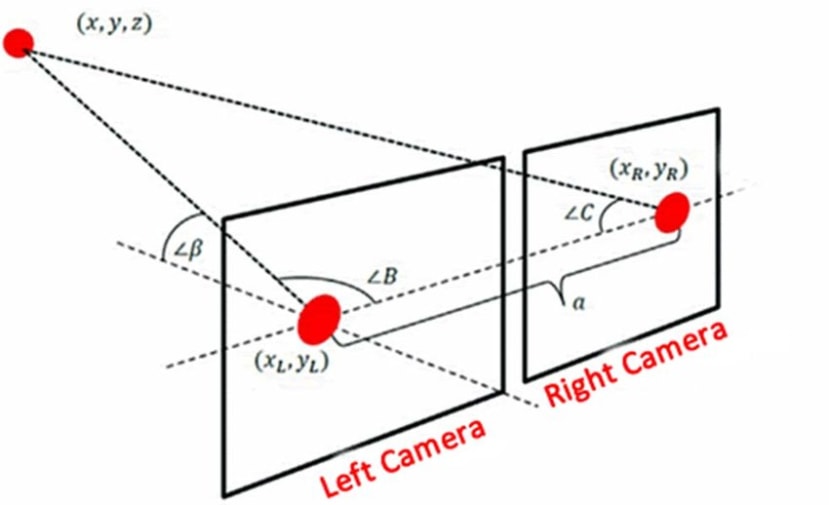
Stereoscopic imaging
This is, of course, how our eyes perceive depth but one downside to this method can be impaired performance when a scene lacks features: a flat, smooth surface like a wall. However, there are a wide variety of applications from satellite terrain mapping to medical imaging.
Final Thoughts
Machine vision is an exciting and ever-expanding area of engineering. I hope our little meander through some of its vagaries may inspire some of the new generation of engineers to take on the challenge and help bring it to even more application areas in the coming years.