NVIDIA Jetson Nano应用-使用Pose Estimation进行姿态辨识以及手部辨识
关注文章
 戴夫来自 DesignSpark
戴夫来自 DesignSpark
你觉得这篇文章怎么样? 帮助我们为您提供更好的内容。
戴夫来自 DesignSpark
Thank you! Your feedback has been received.
戴夫来自 DesignSpark
There was a problem submitting your feedback, please try again later.
戴夫来自 DesignSpark
你觉得这篇文章怎么样?
|
作者 |
张嘉钧 |
|
难度 |
普通 |
|
材料表 |
Webcam X1 NVIDIA JetsonNano X1 |
首先,我们先来运行 trt_pose,这个项目是一个实时姿态辨识的范例!他除了有提供Pre-Trained Model外也有提供Jupyter Notebook形式的教学程序,除此之外他使用的数据集是MSCOCO,所以也有大家也可以尝试去训练自己的数据,只需要参照MSCOCO的格式走即可,接下来就教大家怎么部属在Jetson Nano上吧。
注意:此篇文章使用的Jetson Nano系统为 JetPack 4.4.1。
1.安装相依套件
PyTorch、torchvision:
首先最主要的就是PyTorch、torchvision这边我们可以参考原厂的作法,我提供的范例为 pytorch 1.6,记得要确认自己的JetPack版本与PyTorch的对应版本是否正确。
## PyTorch
wget https://nvidia.box.com/shared/static/p57jwntv436lfrd78inwl7iml6p13fzh.whl -O torch-1.6.0-cp36-cp36m-linux_aarch64.whl
sudo apt-get install python3-pip libopenblas-base libopenmpi-dev
pip3 install Cython
pip3 install numpy torch-1.6.0-cp36-cp36m-linux_aarch64.whl
## torchvision
$ sudo apt-get install libjpeg-dev zlib1g-dev libpython3-dev libavcodec-dev libavformat-dev libswscale-dev
$ git clone --branch v0.7.0 https://github.com/pytorch/vision torchvision # see below for version of torchvision to download
$ cd torchvision
$ export BUILD_VERSION=0.7.0 # where 0.x.0 is the torchvision version
$ python3 setup.py install --user
torch2trt:
NVIDIA的项目基本上都会转换成TensorRT引擎,让整个推论的速度加快,而我们这次使用的trt_pose他提供的模型是PyTorch的,所以我们可以直接用这个Github提供的程序来做转换,透过torch2trt的函式库我们也将能更方便的使用TensorRT引擎,使用方法会与PyTorch相似。
git clone https://github.com/NVIDIA-AI-IOT/torch2trt
cd torch2trt
sudo python3 setup.py install --plugins

其他相关套件(tqdm, cython, pycocotools, matplotlib):
进度条使用到tqdm;cython则是Python跟C/C++的桥梁;由于我们使用到coco dataset所以也可以安装Python的工具,最后Jupyter Lab与matplotlib兼容度最高,所以在上面开图片基本上都会使用该函式库。
sudo pip3 install tqdm cython pycocotools
sudo apt-get install python3-matplotlib
2. 下载安装 trt_pose的Github:
cd ~
git clone https://github.com/NVIDIA-AI-IOT/trt_pose
cd trt_pose
sudo python3 setup.py install
3.下载预训练模型:
我们需要将模型下载到 ~/trt_pose/tasks/human_pose当中,由于Github提供的连结是Google Drvie不能直接透过wget加上网址去下载,所以我会建议直接从Github上下载,或者使用下列指令去下载,这个指令可以下载低于100M的Google Drive檔。
wget --no-check-certificate "https://drive.google.com/uc?export=download&id=1XYDdCUdiF2xxx4rznmLb62SdOUZuoNbd" -O ./tasks/human_pose/resnet18_baseline_att_224x224_A.pth
wget --no-check-certificate "https://drive.google.com/uc?export=download&id=13FkJkx7evQ1WwP54UmdiDXWyFMY1OxDU" -O ./tasks/human_pose/densenet121_baseline_att_256x256_B.pth
4.运行程序:
原厂有提供 trt_pose/tasks/human_pose/live_demo.ipynb,不过我决定带大家写两支程序,顺便熟悉各个指令的用途,首先我们需要将下载下来的PyTorch模型转换成TensorRT引擎,所以我们先新增一个文件名为 cvt_trt.py,接下来就一一新增程序代码,首先导入函式库:
import json
import torch2trt
import torch
import trt_pose.coco
import trt_pose.models
def print_div(txt):
print(f"\n{txt}\n")
接着加载预训练模型并且修改最后一层,这边增加的是 cmap_channels跟 paf_channels,每一个模型会有两个输出cmap与paf,cmap(Confidence Map)就是Pose Estimation常见的热力图,能透过其找出Keypoint所在;Paf (Part Affinity Fields)则是提供一个向量区域,可以表示人体各个Keypoint、skeleton的关联性,而paf 由于是一个向量所以会有 x, y的数值,输出要乘以2。
print_div("LOAD MODEL")
with open('human_pose.json', 'r') as f:
human_pose = json.load(f)
# 取得 keypoint 数量
num_parts = len(human_pose['keypoints'])
num_links = len(human_pose['skeleton'])
# 修改输出层
model = trt_pose.models.resnet18_baseline_att(num_parts, 2 * num_links).cuda().eval()
# 载入权重
MODEL_WEIGHTS = 'resnet18_baseline_att_224x224_A.pth'
model.load_state_dict(torch.load(MODEL_WEIGHTS))
关于cmap与paf的详细可以去看这篇论文的叙述Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields。
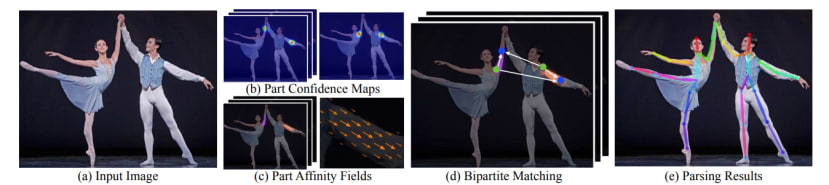 |
|
图片撷取自Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields 论文 |
最后我们就可以进行转换与储存引擎:
print_div("COVERTING")
WIDTH, HEIGHT = 224, 224
data = torch.zeros((1, 3, HEIGHT, WIDTH)).cuda()
model_trt = torch2trt.torch2trt(model, [data], fp16_mode=True, max_workspace_size=1<<25)
print_div("SAVING TENSORRT")
OPTIMIZED_MODEL = 'resnet18_baseline_att_224x224_A.trt'
torch.save(model_trt.state_dict(), OPTIMIZED_MODEL)
print_div("FINISH")
储存档案之后就可以透过Python3去运行程序来将PyTorch转换成TensorRT:
$ python3 cvt_trt.py我们已经完成第一步转换模型了,接下来要再新增一个Python档案 demo.py,来实作推论的部分,首先一样先导入函式库:
import torch
import torchvision.transforms as transforms
import cv2
import PIL.Image
import json
import time
from torch2trt import TRTModule
import trt_pose
import trt_pose.coco
import trt_pose.models
from trt_pose.draw_objects import DrawObjects
from trt_pose.parse_objects import ParseObjects
接着我定义了两个副函式,一个是print_div与cvt_trt.py中功能相同只是换了写法;另一个是preprocess用来将OpenCV的图片转换成PIL并且进行正规化:
print_div = lambda x: print(f"\n{x}\n")
mean = torch.Tensor([0.485, 0.456, 0.406]).cuda()
std = torch.Tensor([0.229, 0.224, 0.225]).cuda()
device = torch.device('cuda')
def preprocess(image):
global device
device = torch.device('cuda')
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
image = PIL.Image.fromarray(image)
image = transforms.functional.to_tensor(image).to(device)
image.sub_(mean[:, None, None]).div_(std[:, None, None])
return image[None, ...]
接着加载TensorRT引擎,通过torch2trt的函式库可以使用类似PyTorch的方式汇入,更简单直观:
print_div("LOAD TENSORRT ENGINE")
OPTIMIZED_MODEL = 'resnet18_baseline_att_224x224_A.trt'
model_trt = TRTModule()
model_trt.load_state_dict(torch.load(OPTIMIZED_MODEL))
接着就到Real-time的Inference程序,我们透过OpenCV撷取摄影机,并且先取得分辨率,待会会将图片进行裁切、缩放:
print_div("START STREAM")
cap = cv2.VideoCapture(0)
w = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
h = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
crop_size = (w-h)//2
# print(w, h, crop_size)
我们需要透过While循环让摄影机不断撷取当前的frame并且进行Inference以及显示结果,t_start用于计算FPS,如果没有影像的话我们就会跳过当前循环,直到有影像内容才会往下运行:
while(True):
t_start = time.time()
ret, frame = cap.read()
if not ret:
continue
资料前处理的部分除了刚刚撰写的preprocess之外还需要针对frame裁切成正方形以及缩放大小,若省略这些步骤会导致模型辨识不出结果:
frame = frame[:, crop_size:(w-crop_size)]
image = cv2.resize(frame, (224,224))
data = preprocess(image)
接着就是推论的部分,模型丢入数据后会输出cmap以及paf,透过 parse_objects可以解析出里面的内容,counts是对象的数量;objects是对象的坐标等信息;peaks用于绘制skeleton。
cmap, paf = model_trt(data)
cmap, paf = cmap.detach().cpu(), paf.detach().cpu()
counts, objects, peaks = parse_objects(cmap, paf)#, cmap_threshold=0.15, link_threshold=0.15)
draw_objects(image, counts, objects, peaks)
最后就是显示结果以及一些基本的关闭设定,这里我们会运算出FPS并将其绘制在图片上:
t_end = time.time()
cv2.putText(image, f"FPS:{int(1/(t_end-t_start))}", (10,20), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0,0,255), 1, cv2.LINE_AA)
cv2.imshow('pose esimation', image)
if cv2.waitKey(1)==ord('q'):
break
cap.release()
cv2.destroyAllWindows()
执行结果如下,可以看到Jetson Nano运行有12左右的FPS,效果还算不错:
到目前我们已经成功执行了trt_pose,而强大的作者们还有针对手部做一个项目,我们就直接来安装并执行看看吧。
1.安装 trt_pose以及相依套件,如果从文章开始执行到现在基本上这一步都处理好了,有需求的读者可以往回查看。
2. 安装traitlets:
$ pip3 install traitlets3.下载他们的Github并移动到该目录:
$ cd ~
$ git clone https://github.com/NVIDIA-AI-IOT/trt_pose_hand.git && cd trt_pose_hand
4. 下载预训练模型:
$ wget --no-check-certificate "https://drive.google.com/uc?export=download&id=1NCVo0FiooWccDzY7hCc5MAKaoUpts3mo" -O ./model /hand_pose_resnet18_baseline_att_224x224.pth接着就可以撰写程序来运行了,他们一样有提供范例程序live_hand_demo.ipynb,不过我们也一样自己来写一个吧!首先也需要将PyTorch的预训练模型给转换好,新增一个cvt_trt.py,程序代码与早先的那个几乎一样,只需要更改json、.pth、.trt的名称即可:
import json
import torch2trt
import torch
import trt_pose.coco
import trt_pose.models
def print_div(txt):
print(f"\n{txt}\n")
print_div("LOAD MODEL")
with open('preprocess/hand_pose.json', 'r') as f:
human_pose = json.load(f)
# 取得 keypoint 数量
num_parts = len(human_pose['keypoints'])
num_links = len(human_pose['skeleton'])
# 修改输出层
model = trt_pose.models.resnet18_baseline_att(num_parts, 2 * num_links).cuda().eval()
# 载入权重
MODEL_WEIGHTS = 'model/hand_pose_resnet18_baseline_att_224x224.pth'
model.load_state_dict(torch.load(MODEL_WEIGHTS))
print_div("COVERTING")
WIDTH, HEIGHT = 224, 224
data = torch.zeros((1, 3, HEIGHT, WIDTH)).cuda()
model_trt = torch2trt.torch2trt(model, [data], fp16_mode=True, max_workspace_size=1<<25)
print_div("SAVING TENSORRT")
OPTIMIZED_MODEL = 'model/hand_pose_resnet18_baseline_att_224x224.trt'
torch.save(model_trt.state_dict(), OPTIMIZED_MODEL)
print_div("FINISH")
接着新增demo.py,也与之前的雷同,json、trt的档名记得改,值得注意的地方是Parse Objects 这个函式多设定了cmap_threshold与 link_threshold,因为这个模型其他地方很容易辨识错误,所以只好提高阀值:
import torch
import torchvision.transforms as transforms
import cv2
import PIL.Image
import json
import time
import math
import os
import numpy as np
import traitlets
from torch2trt import TRTModule
import trt_pose
import trt_pose.coco
import trt_pose.models
from trt_pose.draw_objects import DrawObjects
from trt_pose.parse_objects import ParseObjects
#############################################################
print_div = lambda x: print(f"\n{x}\n")
mean = torch.Tensor([0.485, 0.456, 0.406]).cuda()
std = torch.Tensor([0.229, 0.224, 0.225]).cuda()
device = torch.device('cuda')
def preprocess(image):
global device
device = torch.device('cuda')
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
image = PIL.Image.fromarray(image)
image = transforms.functional.to_tensor(image).to(device)
image.sub_(mean[:, None, None]).div_(std[:, None, None])
return image[None, ...]
############################################################
print_div("INIT")
with open('preprocess/hand_pose.json', 'r') as f:
hand_pose = json.load(f)
# 改变卷标结构 : 增加颈部keypoint以及 paf的维度空间
topology = trt_pose.coco.coco_category_to_topology(hand_pose)
# 用于解析预测后的 cmap与paf
parse_objects = ParseObjects(topology, cmap_threshold=0.30, link_threshold=0.30)
# 用于将keypoint绘制到图片上
draw_objects = DrawObjects(topology)
############################################################
print_div("LOAD TENSORRT ENGINE")
OPTIMIZED_MODEL = 'model/hand_pose_resnet18_baseline_att_224x224.trt'
model_trt = TRTModule()
model_trt.load_state_dict(torch.load(OPTIMIZED_MODEL))
###########################################################
print_div("START STREAM")
cap = cv2.VideoCapture(0)
w = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
h = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
crop_size = (w-h)//2
# print(w, h, crop_size)
while(True):
t_start = time.time()
ret, frame = cap.read()
if not ret:
continue
frame = frame[:, crop_size:(w-crop_size)]
image = cv2.resize(frame, (224,224))
data = preprocess(image)
cmap, paf = model_trt(data)
cmap, paf = cmap.detach().cpu(), paf.detach().cpu()
counts, objects, peaks = parse_objects(cmap, paf)#, cmap_threshold=0.15, link_threshold=0.15)
draw_objects(image, counts, objects, peaks)
t_end = time.time()
cv2.putText(image, f"FPS:{int(1/(t_end-t_start))}", (10,20), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0,0,255), 1, cv2.LINE_AA)
cv2.imshow('pose esimation', image)
if cv2.waitKey(1)==ord('q'):
break
cap.release()
cv2.destroyAllWindows()
#############################################################
执行结果如下:
结语
恭喜你们成功执行trt_pose以及trt_pose_hand,针对trt_pose_hand作者还有两个范例可以运行,我们将在下一篇进行介绍与分析。
相关文章
trt_pose
https://github.com/NVIDIA-AI-IOT/trt_pose
Hand Pose Estimation And Classification