NVIDIA Jetson Nano應用- Google Colab雲端訓練客製化 YOLOv4物件辨識-上篇
关注文章
 戴夫来自 DesignSpark
戴夫来自 DesignSpark
你觉得这篇文章怎么样? 帮助我们为您提供更好的内容。
戴夫来自 DesignSpark
Thank you! Your feedback has been received.
戴夫来自 DesignSpark
There was a problem submitting your feedback, please try again later.
戴夫来自 DesignSpark
你觉得这篇文章怎么样?
|
作者 |
張嘉鈞 |
|
難度 |
普通 |
|
材料表 |
Webcam X1 NVIDIA Jetson Nano X1 |
上篇分為兩個大項目:
1.YOLOv4訓練其他數據集的基本概念
2.如何在Colab上使用YOLOv4
關於YOLOv4這邊就不多作介紹了,基本上YOLOv4是現今集大成之作,整合了各種技術,想要了解詳細的技術可以在網路上找到很多相關的資源,我這邊蠻推薦初學者可以去看吳恩達老師在coursera上面的AI課程,其中也有教到YOLO的運作原理,雖然沒有講到論文這麼深入的技術但是卻貫穿了YOLO的精隨。
Transfer Learning的基本概念
這次實作的部分是關於YOLOv4用於客製化的數據集,還是有幾個基本的概念需要提到,像是用已經訓練好的權重再去訓練其他的數據集,這個動作就叫做「Transfer Learning」,中文可能會稱作「遷移式學習」、「轉移學習」;主要的遷移式學習有分成兩種「Feature Extraction」、「Fine Tuning」。
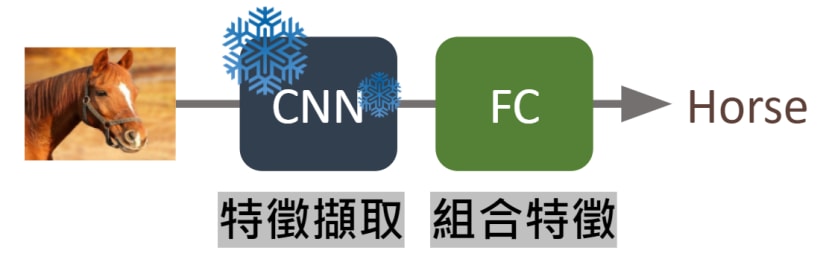
「Feature Extraction」中文為「特徵擷取」,會保留預訓練模型CNN的部分也就是保留模型良好的特徵擷取的能力,只會重新訓練Fully Connected的部分 (簡稱FC),我自己的理解會把FC當成是排列組合,原本只能辨識貓跟狗的模型,由於已經會擷取貓跟狗的特徵,這時候導入馬的圖片,它也能擷取出特徵,只是不懂得將擷取出來的特徵歸類成新的類別,所以這時候我們只訓練FC (排列組合的部分),讓他可以重新學習如何將各種特徵進行分類;我們用下圖來模擬情境,灰白格子代表CNN的權重。
1.透過預訓練模型的CNN的部分可以擷取出特定特徵

2.輸入一樣是動物類型的圖片,就算不是原本訓練的數據它一樣能擷取出特定的特徵

3.所以我們只需要凍結 ( freeze ) CNN的部分,重新訓練FC即可:
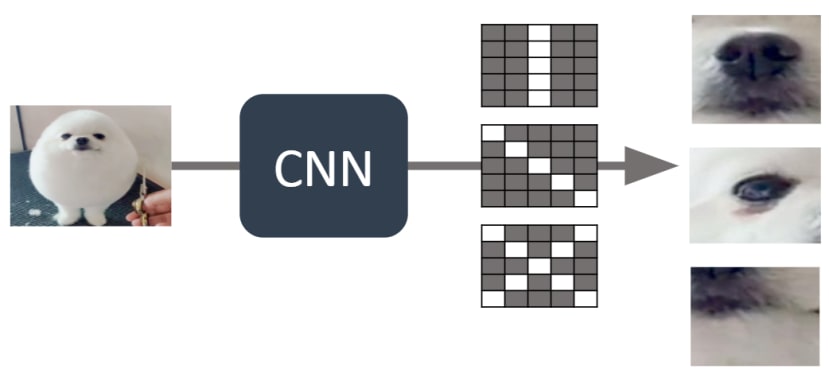
「Fine Tuning」中文為「微調」,我們直接用訓練好的權重進行重新訓練,與從頭訓練不同的地方在於從頭訓練是一組隨機的數值,而預訓練模型不是,它將能優化原本就已經訓練過的權重,不過這種方式最好還是基於數據集類型雷同的情況下;我們一樣用圖片來模擬情境。
1.原先預訓練模型訓練出來的CNN權重將能優秀的辨識出狗的特徵
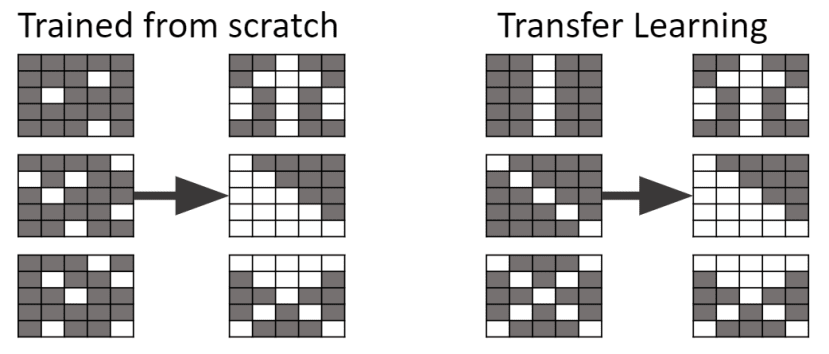
2.假設我們已經知道下圖的權重用來辨識新數據-馬更為優秀

3.從概念上來說,微調會比從頭訓練更快達到目標
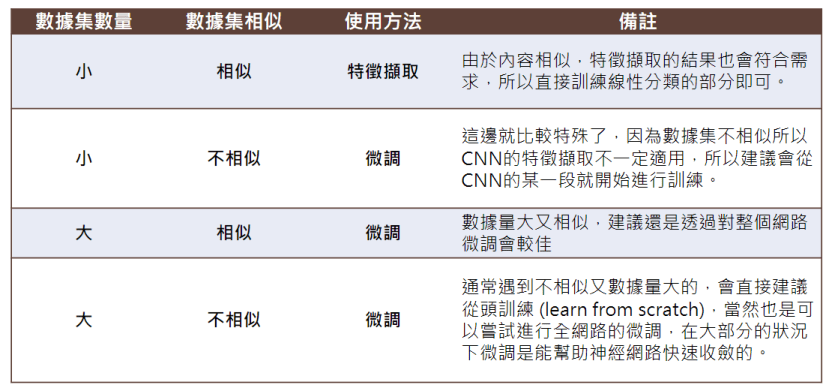
最後我整理了一個表格,讓大家參考一下什麼樣的情況適合用哪一個技術,以上如果有敘述錯誤或不清的地方,歡迎在下方留言區告訴我:
Colab介紹與使用
Transfer Learning概念的部分已經講完了,接下來就要開始進入實作的部分了!這次我們使用的工具是Colaboratory (簡稱Colab),如果有看我們早期的文章可以注意到我們很喜歡運用Colab這個平台,這是由Google推出的線上Python程式執行平台,免費版本的Colab提供了8小時的免費GPU可以使用,所以手邊沒有強大GPU的同學們就可以善用這個平台的資源。
 |
|
Colab的詳細介紹 https://colab.research.google.com/notebooks/intro.ipynb#scrollTo=5fCEDCU_qrC0 |
首先,我們要先在自己的Google雲端硬碟中心增Colab的檔案,我們需要在雲端硬碟的空白處點擊右鍵→更多→連結更多應用程式

在上方搜尋列輸入「Colab」就可以進行安裝

安裝完再回到雲端硬碟點擊右鍵→更多→Google Colaboratory,接著就會看到跟下圖一樣的畫面,這樣就成功在你的雲端硬碟中開啟了Colab

接下來有幾個重要的部分,第一個要先啟動你的GPU,編輯→筆記本設定→硬體加速器→GPU→儲存,這樣就完成GPU設定了。

我們可以使用各種AI框架的程式來檢查,這邊我使用PyTorch來檢查GPU的狀況,第一個print是確認GPU能否運作,第二個print是顯示顯示卡的名稱,我們將程式複製到區塊裡面,並且透過Shift+Enter執行程式。
import torch
print(torch.cuda.is_available())
print(torch.cuda.get_device_name())

YOLOv4在Colab上如何運作
到目前我們的事前準備已經完成一半了,接下來我們要測試一下在Colab上能否運作YOLOv4,Colab如果沒有綁定雲端硬碟的話它會自動分配一些空間給你暫存使用,所以這邊我們直接使用暫存的空間來測試YOLOv4就可以了,後續會再教如何掛接到雲端硬碟,首先一樣要先將darknet的Github給Clone下來。
!git clone https://github.com/AlexeyAB/darknet.git
接著需要移動進去darknet的資料夾,在Colab這種互動式Python環境,可以透過%、! 來模擬終端機的指令,特別是cd只能透過%不能透過 !。
%cd ./darknet在建構darknet之前需要先修改Makefile才行,這邊使用Linux的指令sed,-i代表會直接替換檔案內容,替換的模式選擇s (search),第一個//包住的內容是要搜尋的內容,第二個//中的則是要替換掉的內容。
!sed -i 's/OPENCV=0/OPENCV=1/' Makefile
!sed -i 's/GPU=0/GPU=1/' Makefile
!sed -i 's/CUDNN=0/CUDNN=1/' Makefile
!sed -i 's/CUDNN_HALF=0/CUDNN_HALF=1/' Makefile
!sed -i 's/LIBSO=0/LIBSO=1/' Makefile
最後就可以開始建構了,大概需要兩分至三分鐘的時間。
!make我們現在已經可以使用darknet的函式庫了,進行推論前還需要下載訓練好的權重,我們使用wget直接從網路上抓取,這些檔案連結都可以在darknet的github中找到。
# 下載 yolov4-tiny
!wget https://github.com/AlexeyAB/darknet/releases/download/darknet_yolo_v4_pre/yolov4-tiny.weights
# 下載 yolov4
!wget https://github.com/AlexeyAB/darknet/releases/download/darknet_yolo_v3_optimal/yolov4.weights
接著可以透過下列指令進行測試,coco.data 存放資料集的資訊 像是圖片大小、類別等等;yolov4.cfg 則是存放yolov4神經網路模型的資訊;yolov4.weights 為剛剛下載的訓練好的權重;data/dog.jpg 為輸入的資料;-thresh 閥值 越大需要的信心指數越高。
!./darknet detector test ./cfg/coco.data ./cfg/yolov4.cfg ./yolov4.weights data/dog.jpg -i 0 -thresh 0.25觀察輸出結果可以看到我們這張dog.jpg中有bicycle、dog、truck、pottedplant以及他們對應的信心指數,還有一個warning表達的是它沒有螢幕可以顯示,這個無傷大雅,我們可以通過直接在檔案總管找到/darknet/predictions.jpg這張圖片並點擊兩下開啟查看:

除此之外也可以透過下列的程式來將結果顯示出來,因為matplotlib跟Jupyter有較高的相容性,而Colab使用的是Jupyter Notebook的環境,我們可以透過 %matplotlib inline 這段程式讓matplot的圖表顯示在Colab當中。
import cv2
import matplotlib.pyplot as plt
# 讓 matplot 圖表顯示在Jupyter Notebook裡面
%matplotlib inline
# 透過OpenCV讀取圖片
path = 'predictions.jpg'
img = cv2.imread(path)
# 在 Jupyter Notebook 上需要轉換成 Matplot 顯示才行
fig = plt.gcf()
fig.set_size_inches(18, 10)
plt.axis('off')
plt.imshow(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
plt.show()
接著我在網路上找到這段程式碼可以在Colab上運行即時影像辨識,第一段程式碼表示的是透過Python建構一個Inference的副函式叫做 darknet_helper,通過這個darknet_helper可以獲取到辨識結果與輸出結果的寬高比例。
# import darknet functions to perform object detections
from darknet import *
# load in our YOLOv4 architecture network
network, class_names, class_colors = load_network("cfg/yolov4.cfg", "cfg/coco.data", "yolov4.weights")
width = network_width(network)
height = network_height(network)
# darknet helper function to run detection on image
def darknet_helper(img, width, height):
darknet_image = make_image(width, height, 3)
img_rgb = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img_resized = cv2.resize(img_rgb, (width, height),
interpolation=cv2.INTER_LINEAR)
# get image ratios to convert bounding boxes to proper size
img_height, img_width, _ = img.shape
width_ratio = img_width/width
height_ratio = img_height/height
# run model on darknet style image to get detections
copy_image_from_bytes(darknet_image, img_resized.tobytes())
detections = detect_image(network, class_names, darknet_image)
free_image(darknet_image)
return detections, width_ratio, height_ratio
第二段程式碼則是如何在Colab上運作即時影像的部分,由於是Javascript的程式所以我也不多作介紹了,有興趣的可以在自己研究。
# import dependencies
from IPython.display import display, Javascript, Image
from google.colab.output import eval_js
from google.colab.patches import cv2_imshow
from base64 import b64decode, b64encode
import cv2
import numpy as np
import PIL
import io
import html
import time
import matplotlib.pyplot as plt
%matplotlib inline
# function to convert the JavaScript object into an OpenCV image
def js_to_image(js_reply):
"""
Params:
js_reply: JavaScript object containing image from webcam
Returns:
img: OpenCV BGR image
"""
# decode base64 image
image_bytes = b64decode(js_reply.split(',')[1])
# convert bytes to numpy array
jpg_as_np = np.frombuffer(image_bytes, dtype=np.uint8)
# decode numpy array into OpenCV BGR image
img = cv2.imdecode(jpg_as_np, flags=1)
return img
# function to convert OpenCV Rectangle bounding box image into base64 byte string to be overlayed on video stream
def bbox_to_bytes(bbox_array):
"""
Params:
bbox_array: Numpy array (pixels) containing rectangle to overlay on video stream.
Returns:
bytes: Base64 image byte string
"""
# convert array into PIL image
bbox_PIL = PIL.Image.fromarray(bbox_array, 'RGBA')
iobuf = io.BytesIO()
# format bbox into png for return
bbox_PIL.save(iobuf, format='png')
# format return string
bbox_bytes = 'data:image/png;base64,{}'.format((str(b64encode(iobuf.getvalue()), 'utf-8')))
return bbox_bytes
# JavaScript to properly create our live video stream using our webcam as input
def video_stream():
js = Javascript('''
var video;
var div = null;
var stream;
var captureCanvas;
var imgElement;
var labelElement;
var pendingResolve = null;
var shutdown = false;
function removeDom() {
stream.getVideoTracks()[0].stop();
video.remove();
div.remove();
video = null;
div = null;
stream = null;
imgElement = null;
captureCanvas = null;
labelElement = null;
}
function onAnimationFrame() {
if (!shutdown) {
window.requestAnimationFrame(onAnimationFrame);
}
if (pendingResolve) {
var result = "";
if (!shutdown) {
captureCanvas.getContext('2d').drawImage(video, 0, 0, 640, 480);
result = captureCanvas.toDataURL('image/jpeg', 0.8)
}
var lp = pendingResolve;
pendingResolve = null;
lp(result);
}
}
async function createDom() {
if (div !== null) {
return stream;
}
div = document.createElement('div');
div.style.border = '2px solid black';
div.style.padding = '3px';
div.style.width = '100%';
div.style.maxWidth = '600px';
document.body.appendChild(div);
const modelOut = document.createElement('div');
modelOut.innerHTML = "<span>Status:</span>";
labelElement = document.createElement('span');
labelElement.innerText = 'No data';
labelElement.style.fontWeight = 'bold';
modelOut.appendChild(labelElement);
div.appendChild(modelOut);
video = document.createElement('video');
video.style.display = 'block';
video.width = div.clientWidth - 6;
video.setAttribute('playsinline', '');
video.onclick = () => { shutdown = true; };
stream = await navigator.mediaDevices.getUserMedia(
{video: { facingMode: "environment"}});
div.appendChild(video);
imgElement = document.createElement('img');
imgElement.style.position = 'absolute';
imgElement.style.zIndex = 1;
imgElement.onclick = () => { shutdown = true; };
div.appendChild(imgElement);
const instruction = document.createElement('div');
instruction.innerHTML =
'<span style="color: red; font-weight: bold;">' +
'When finished, click here or on the video to stop this demo</span>';
div.appendChild(instruction);
instruction.onclick = () => { shutdown = true; };
video.srcObject = stream;
await video.play();
captureCanvas = document.createElement('canvas');
captureCanvas.width = 640; //video.videoWidth;
captureCanvas.height = 480; //video.videoHeight;
window.requestAnimationFrame(onAnimationFrame);
return stream;
}
async function stream_frame(label, imgData) {
if (shutdown) {
removeDom();
shutdown = false;
return '';
}
var preCreate = Date.now();
stream = await createDom();
var preShow = Date.now();
if (label != "") {
labelElement.innerHTML = label;
}
if (imgData != "") {
var videoRect = video.getClientRects()[0];
imgElement.style.top = videoRect.top + "px";
imgElement.style.left = videoRect.left + "px";
imgElement.style.width = videoRect.width + "px";
imgElement.style.height = videoRect.height + "px";
imgElement.src = imgData;
}
var preCapture = Date.now();
var result = await new Promise(function(resolve, reject) {
pendingResolve = resolve;
});
shutdown = false;
return {'create': preShow - preCreate,
'show': preCapture - preShow,
'capture': Date.now() - preCapture,
'img': result};
}
''')
display(js)
def video_frame(label, bbox):
data = eval_js('stream_frame("{}", "{}")'.format(label, bbox))
return data
最後的流程如下:取得影像,將影像轉換成特定格式並且辨識,將結果繪製到特定圖層,將圖層覆蓋上去並且更新畫面的內容。
# 開啟影像串流
video_stream()
# 標題
label_html = 'Capturing...'
# 初始化參數
bbox = ''
count = 0
while True:
# 顯示並取得影像
js_reply = video_frame(label_html, bbox)
if not js_reply:
break
# 將影像轉換成OpenCV的格式
frame = js_to_image(js_reply["img"])
# 建立邊界框的底圖
bbox_array = np.zeros([480,640,4], dtype=np.uint8)
# 進行辨識
detections, width_ratio, height_ratio = darknet_helper(frame, width, height)
# 繪製邊界框於剛剛建立的bbox_array
for label, confidence, bbox in detections:
left, top, right, bottom = bbox2points(bbox)
left, top, right, bottom = int(left * width_ratio), int(top * height_ratio), int(right * width_ratio), int(bottom * height_ratio)
bbox_array = cv2.rectangle(bbox_array, (left, top), (right, bottom), class_colors[label], 2)
bbox_array = cv2.putText(bbox_array, "{} [{:.2f}]".format(label, float(confidence)),
(left, top - 5), cv2.FONT_HERSHEY_SIMPLEX, 0.5,
class_colors[label], 2)
bbox_array[:,:,3] = (bbox_array.max(axis = 2) > 0 ).astype(int) * 255
# 將 bbox_array轉換成可以輸入到畫面上的 byte 格式
bbox_bytes = bbox_to_bytes(bbox_array)
# 更新bbox這樣下一次畫面中的畫面才會更新
bbox = bbox_bytes
結語
到這邊你已經將基礎觀念都已經摸熟了,包括怎麼去Transfer Learning的基本概念以及 YOLOv4如何在Colab上運作,接下來我們就進入Transfer Learning的實作的部分吧!